Pandas知识点-排序操作
共
3807字,需浏览
8分钟
·
2021-03-19 12:13

数据处理过程中,经常需要对数据进行排序,使数据按指定的顺序排列(升序或降序)。
在Pandas中,排序功能已经实现好了,我们只需要调用对应的方法即可。
一、数据读取
数据文件是600519.csv,将此文件放到代码同级目录下,从文件中读取出数据。
为了方便后面进行排序操作,只读取了数据中的前十行,并删除了一些列,设置“日期”和“收盘价”为索引。
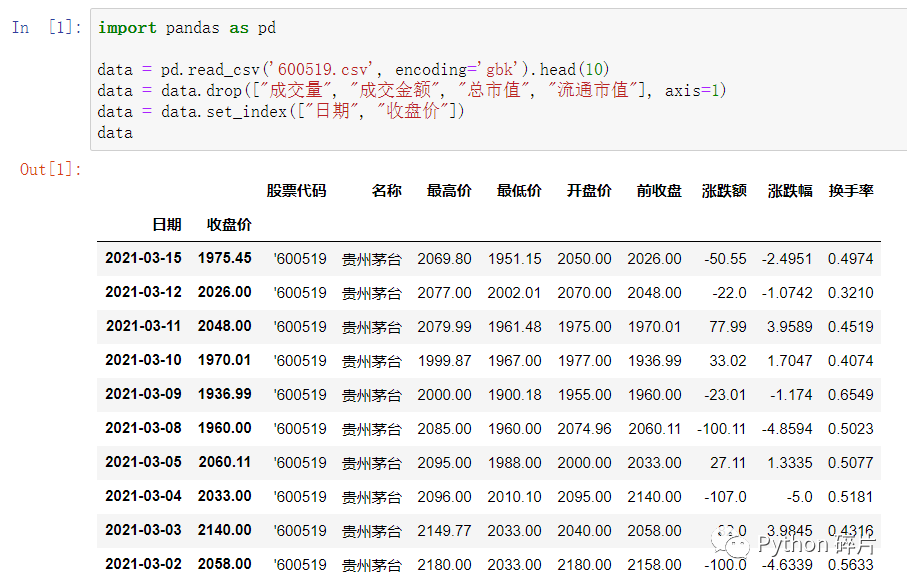
读取的原始数据如上图,本文基于这些数据来进行排序操作。
二、DataFrame排序操作
1. 按索引进行排序
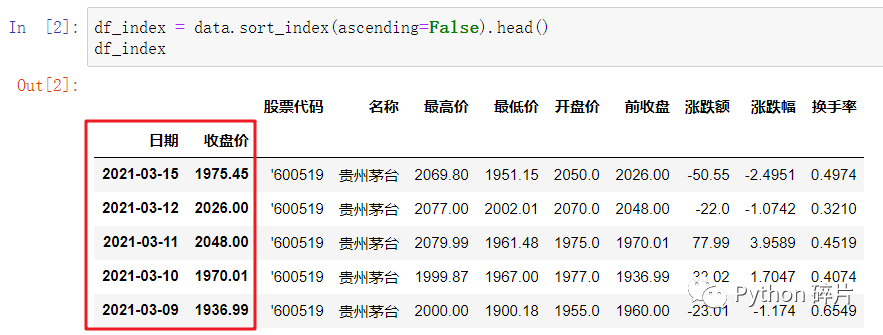
sort_index(): 对DataFrame按索引排序。
一般情况下DataFrame的行索引都是单列索引,即数值型索引或指定的某一列作为行索引。如果行索引为多重索引,在不指定参数level时,会按多重索引中的第一个行索引进行排序。
ascending: 排序默认是升序排序,ascending参数默认为True,将ascending参数设置成False则按降序排序。
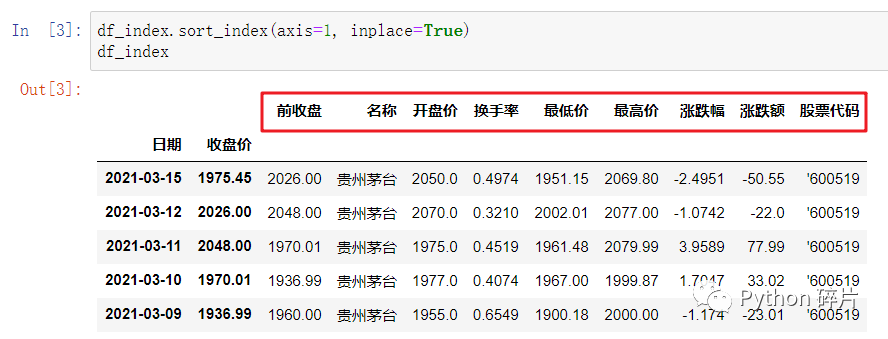
axis: 排序默认是按行索引排序(对每一行数据排序),axis参数默认为0,将axis参数设置成1则按列索引排序(对每一列数据排序)。不过,在实际应用中,对列排序的情况是极少的。
inplace: 在排序时,默认返回一个新的DataFrame,inplace参数默认为False,将inplace参数设置成True则对原DataFrame进行排序,直接修改了数据本身,无返回值。无返回值时不能链式调用,如调用head(),将inplace设置成True时要注意。
2. 按多重索引进行排序
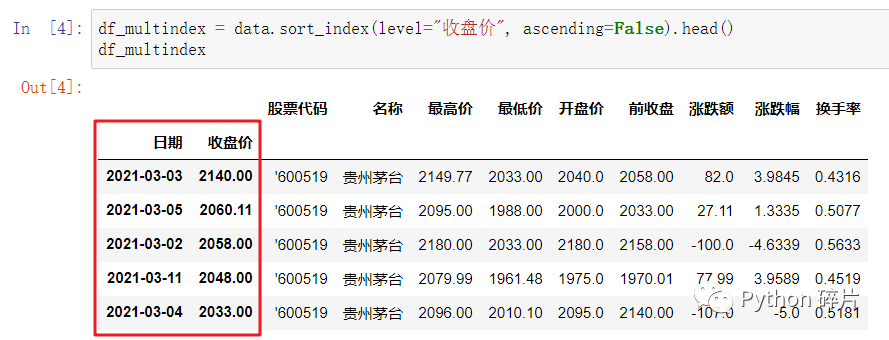
level: 当DataFrame的行索引为多重索引时,通过level参数可以指定按多重索引中的一个或多个行索引进行排序,level参数默认为None,按多重索引中的第一个行索引排序。如指定level为“收盘价”时,不再是按“日期”排序,而是按“收盘价”排序。
给level传值时,可以传入行索引的key(索引名),如:“日期”、“收盘价”,也可以传入行索引的数值索引,如:0或1,0对应“日期”,1对应“收盘价”。
如果要按多重索引内的多个行索引排序,可以给level传入一个列表,这样会先按列表中的第一个行索引排序,当第一个行索引有相等的值时,再按第二个行索引进行排序,以此类推。对应的ascending可以传入一个值,表示多个行索引都升序或都降序,如果要使多个行索引有升序有降序,可以给ascending传入一个列表,列表长度与level的列表长度必须相等。
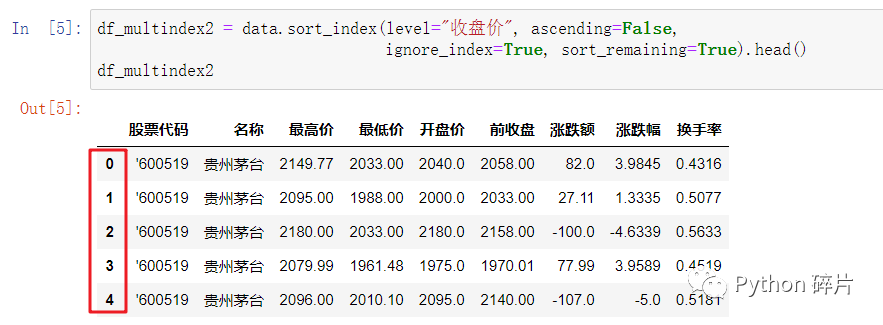
ignore_index: 如果DataFrame的行索引为多重索引,排序结果显示的索引默认是多重索引,ignore_index参数默认为False,将ignore_index参数设置成True则结果中会隐藏多重索引,显示成数值型索引(排序完成后从0开始编号)。
sort_remaining: 按多重索引排序时,按level指定的行索引排序后,默认会继续对剩余的行索引进行排序,sort_remaining参数默认为True。在上面的例子中,level指定按“收盘价”进行降序排序,如果sort_remaining为True,按“收盘价”排序后,如果“收盘价”中有相等的值,会继续按剩余的(level没有指定的)行索引“日期”进行降序排序。如果sort_remaining为False,则按“收盘价”排序后,排序就结束了,即使“收盘价”中有相等的值也不会继续排序。
当多重索引中不止两个行索引时,如果level指定的行索引排序升降不一致(有升序有降序),即使sort_remaining为True,剩余的行索引也不会继续排序。例如多重索引中有三个行索引,level指定了按前两个索引排序,一个是升序一个是降序,此时即使sort_remaining为True,也不会继续按第三个行索引排序。不过,在实际应用中,这种情况极少。
继续上面的情况,按多重索引中的第一个行索引排序后不继续排序,如果第一个行索引中有相等的值,结果的顺序是什么样的呢?是不是保持原始数据的先后顺序?
kind: 在sort_index()中默认采用的排序算法是快速排序,kind参数默认为quicksort(快速排序)。快速排序是一种不稳定的排序算法,不能保证结果中值相等的数据保持先后顺序。kind参数支持三种排序算法,另两种是mergesort(归并排序)和heapsort(堆排序),三种排序算法中只有归并排序是稳定的。但kind参数只支持单列的排序,不能用于按多重索引排序的情况。如果对每个行索引的排序都有要求,最好是通过level和ascending参数依次指定好。
3. 按指定列进行排序
在按列排序前,请特别注意:按行索引排序和按列排序都是对行进行排序,按列索引排序和按行排序都是对列进行排序。避免被绕晕了。
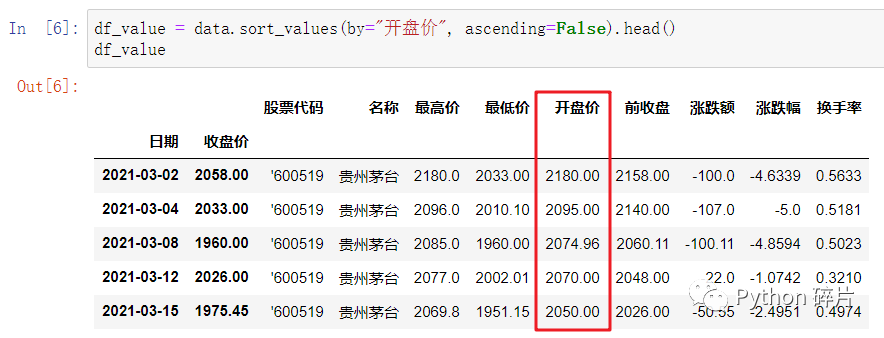
sort_values(): 对DataFrame按列排序。
by: sort_values()的第一个参数by是必传参数,传入排序指定的基准列,传参可以用位置参数的方式,也可以用关键字参数的方式。如果对行排序,by参数必须传入列索引中的值,如果对列排序,by参数必须传入行索引中的值。因为DataFrame中存储的每一列数据类型通常不一样,有些数据类型之间不支持排序,所以不一定能对列排序。
na_position: 在按指定列进行排序时,如果此列数据中有空值(NaN),空值默认排在最后面,na_position参数默认为 last ,将na_position参数设置成 first 则空值排在最前面。na_position参数只支持按单列排序时使用,在按多重索引或按多列排序时无效。
sort_values()中,axis参数、ascending参数、inplace参数、kind参数、ignore_index参数的功能与sort_index()中一样,不再赘述。
4. 按多个列进行排序
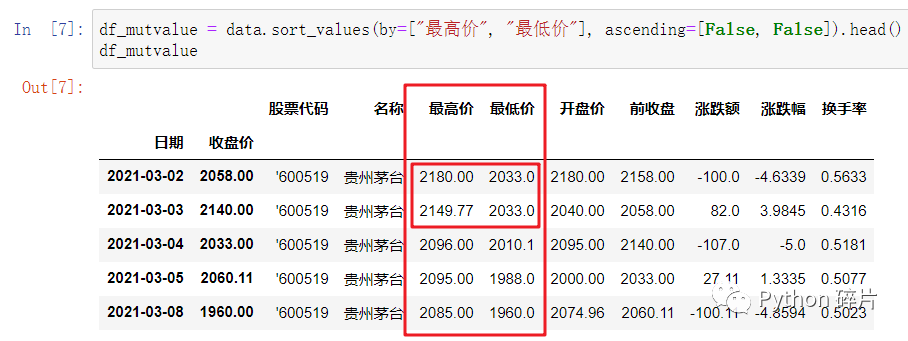
给by参数传入多个列索引值时(用列表的方式),即可以对多个列进行排序。当第一列中有相等的数据时,依次按后面的列进行排序。ascending参数的用法与按多重索引排序一样。
三、Series排序操作
1. 按行索引进行排序
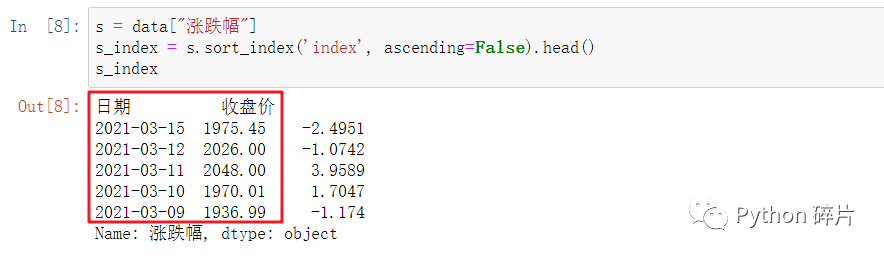
sort_index(): 对Series按行索引排序。
Series是一维数据,只有一列,不存在对列索引排序的情况,所以axis参数的值只能为0,不能设置成1,否则会报错。
多重索引的排序与DataFrame一样,不过,多重索引一般用于多维数据中,Series数据的行索引一般不会是多重索引。
对Series排序时,level参数、ascending参数、inplace参数、kind参数、na_position参数、sort_remaining参数、ignore_index参数的功能与DataFrame排序时一样。2. 按列进行排序
sort_values(): 对Series按列排序。
Series只有一列数据,所以按列排序时,不需要指定列,没有by参数,也不可以设置axis参数为1,否则会报错。当然也不存在基于多列排序的情况。
ascending参数、inplace参数、kind参数、na_position参数、ignore_index参数的功能与DataFrame排序时一样。
四、排序方法总结
不管是对DataFrame排序还是对Series排序,方法名都一样,sort_index()和sort_values()。对DataFrame排序可以对行排序(按行索引或按列),也可以对列排序(按列索引或按行),不过,对列排序会受数据类型的限制。对Series排序只能对行排序(按行索引或按列)。
axis参数用于设置对行排序还是对列排序,Series排序时只能对行排序。level参数用于设置多重索引中排序的行索引,行索引不是多重索引时没必要使用。ascending参数用于设置升序或降序排序。inplace参数用于设置是否对原数据修改,对原数据修改时没有返回值,不能链式调用。kind参数用于设置使用的排序算法,在按多重索引排序和按多个列排序时无效。na_position参数用于设置空值排在最后面或最前面,在按多重索引排序和按多个列排序时无效。如果行索引是多重索引,ignore_index参数可以设置返回结果是否忽略多重索引,行索引不是多重索引时无效。按多重索引排序时,sort_remaining参数用于设置是否继续按level没有指定的行索引排序,如果level指定的行索引排序升降不统一则无效。
以上就是Pandas中的排序操作介绍,如果需要数据和代码,可以点击关注公众号“Python碎片”,然后在后台回复“pandas04”关键字获取本文代码和数据。
点赞
评论
收藏
分享

手机扫一扫分享
举报
点赞
评论
收藏
分享
手机扫一扫分享
举报
 下载APP
下载APP