
Grafana Loki 架构
Grafana Loki 是一套可以组合成一个功能齐全的日志堆栈组件,与其他日志记录系统不同,Loki 是基于仅索引有关日志元数据的想法而构建的:标签(就像 Prometheus 标签一样)。日志数据本身被压缩然后并存储在对象存储(例如 S3 或 GCS)的块中,甚至存储在本地文件系统上,轻量级的索引和高度压缩的块简化了操作,并显着降低了 Loki 的成本,Loki 更适合中小团队。
Grafana Loki 主要由 3 部分组成:
loki: 日志记录引擎,负责存储日志和处理查询 promtail: 代理,负责收集日志并将其发送给 loki grafana: UI 界面
多租户
Loki 支持多租户,以使租户之间的数据完全分离。当 Loki 在多租户模式下运行时,所有数据(包括内存和长期存储中的数据)都由租户 ID 分区,该租户 ID 是从请求中的 X-Scope-OrgID HTTP 头中提取的。当 Loki 不在多租户模式下时,将忽略 Header 头,并将租户 ID 设置为 fake,这将显示在索引和存储的块中。
运行模式
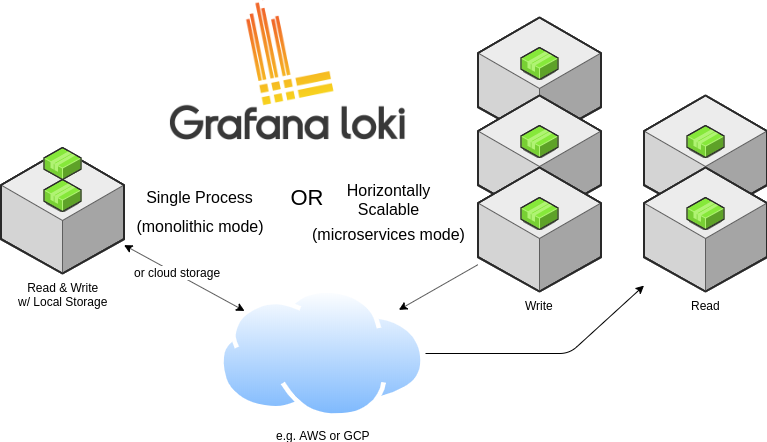
Loki 针对本地运行(或小规模运行)和水平扩展进行了优化吗,Loki 带有单一进程模式,可在一个进程中运行所有必需的微服务。单进程模式非常适合测试 Loki 或以小规模运行。为了实现水平可伸缩性,可以将 Loki 的微服务拆分为单独的组件,从而使它们彼此独立地扩展。每个组件都产生一个用于内部请求的 gRPC 服务器和一个用于外部 API 请求的 HTTP 服务,所有组件都带有 HTTP 服务器,但是大多数只暴露就绪接口、运行状况和指标端点。
Loki 运行哪个组件取决于命令行中的 -target 标志或 Loki 的配置文件中的 target:<string> 部分。当 target 的值为 all 时,Loki 将在单进程中运行其所有组件。,这称为单进程或单体模式。使用 Helm 安装 Loki 时,单单体模式是默认部署方式。
当 target 未设置为 all(即被设置为 querier、ingester、query-frontend 或 distributor),则可以说 Loki 在水平伸缩或微服务模式下运行。
Loki 的每个组件,例如 ingester 和 distributors 都使用 Loki 配置中定义的 gRPC 侦听端口通过 gRPC 相互通信。当以单体模式运行组件时,仍然是这样的:尽管每个组件都以相同的进程运行,但它们仍将通过本地网络相互连接进行组件之间的通信。
单体模式非常适合于本地开发、小规模等场景,单体模式可以通过多个进程进行扩展,但有以下限制:
当运行带有多个副本的单体模式时,当前无法使用本地索引和本地存储,因为每个副本必须能够访问相同的存储后端,并且本地存储对于并发访问并不安全。 各个组件无法独立缩放,因此读取组件的数量不能超过写入组件的数量。
组件
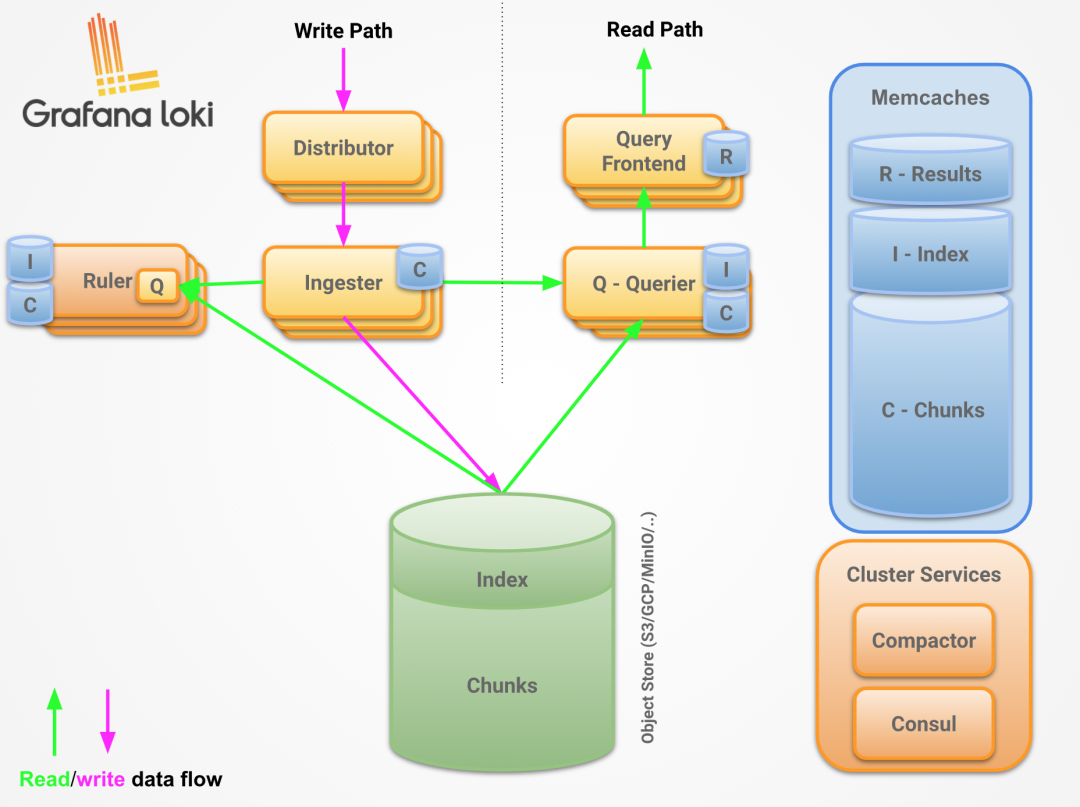
Distributor
distributor 服务负责处理客户端写入的日志,它本质上是日志数据写入路径中的第一站,一旦 distributor 收到日志数据,会将其拆分为多个批次,然后并行发送给多个 ingester。
distributor 通过 gRPC 与 ingester 通信,它们都是无状态的,可以根据需要扩大或缩小规模。
哈希
Distributors 将一致性哈希和可配置的复制因子结合使用,以确定 Ingester 服务的哪些实例应该接收指定的流。
流是一组与租户和唯一标签集关联的日志,使用租户 ID 和标签集对流进行 hash 处理,然后使用哈希查询要发送流的 Ingesters。
存储在 Consul 中的哈希环被用来实现一致性哈希,所有的 ingester 都会使用自己拥有的一组 Token 注册到哈希环中,每个 Token 是一个随机的无符号 32 位数字,与一组 Token 一起,ingester 将其状态注册到哈希环中,状态 JOINING 和 ACTIVE 都可以接收写请求,而 ACTIVE 和 LEAVING 的 ingesters 可以接收读请求。在进行哈希查询时,distributors 只使用处于请求的适当状态的 ingester 的 Token。
为了进行哈希查找,distributors 找到最小合适的 Token,其值大于日志流的哈希值,当复制因子大于 1 时,属于不同 ingesters 的下一个后续 Token(在环中顺时针方向)也将被包括在结果中。
这种哈希配置的效果是,一个 ingester 拥有的每个 Token 都负责一个范围的哈希值,如果有三个值为 0、25 和 50 的 Token,那么 3 的哈希值将被给予拥有 25 这个 Token 的 ingester,拥有 25 这个 Token 的 ingester负责1-25的哈希值范围。
Quorum(仲裁)一致性
由于所有的 distributors 共享对同一哈希环的访问权,所以写请求可以被发送到任何 distributor。
为了确保查询结果的一致性,Loki 在读和写上使用 Dynamo 式的仲裁一致性方式,这意味着 distributor 将等待至少一半加一个 ingesters 的响应,然后再对发送的客户端进行响应。
Ingester
ingester 服务负责将日志数据写入长期存储后端(DynamoDB、S3、Cassandra 等)。此外 ingester 会验证摄取的日志行是按照时间戳递增的顺序接收的(即每条日志的时间戳都比前面的日志晚一些),当 ingester 收到不符合这个顺序的日志时,该日志行会被拒绝并返回一个错误。
如果传入的行与之前收到的行完全匹配(与之前的时间戳和日志文本都匹配),传入的行将被视为完全重复并被忽略。 如果传入的行与前一行的时间戳相同,但内容不同,则接受该日志行。这意味着同一时间戳有两个不同的日志行是可能的。
来自每个唯一标签集的日志在内存中被建立成 chunks(块),然后可以根据配置的时间间隔刷新到支持的后端存储。在下列情况下,块被压缩并标记为只读:
当前块容量已满(该值可配置) 过了太长时间没有更新当前块的内容 刷新了
每当一个数据块被压缩并标记为只读时,一个可写的数据块就会取代它。如果一个 ingester 进程崩溃或突然退出,所有尚未刷新的数据都会丢失。Loki 通常配置为多个副本(通常是 3 个)来降低这种风险。
当向持久存储刷新时,该块将根据其租户、标签和内容进行哈希处理,这意味着具有相同数据副本的多个 ingesters 实例不会将相同的数据两次写入备份存储中,但如果对其中一个副本的写入失败,则会在备份存储中创建多个不同的块对象。有关如何对数据进行重复数据删除,请参阅 Querier。
WAL
上面我们也提到了 ingesters 将数据临时存储在内存中,如果发生了崩溃,可能会导致数据丢失,而 WAL 就可以帮助我们来提高这方面的可靠性。
在计算机领域,WAL(Write-ahead logging,预写式日志)是数据库系统提供原子性和持久化的一系列技术。
在使用 WAL 的系统中,所有的修改都先被写入到日志中,然后再被应用到系统状态中。通常包含 redo 和 undo 两部分信息。为什么需要使用 WAL,然后包含 redo 和 undo 信息呢?举个例子,如果一个系统直接将变更应用到系统状态中,那么在机器断电重启之后系统需要知道操作是成功了,还是只有部分成功或者是失败了(为了恢复状态)。如果使用了 WAL,那么在重启之后系统可以通过比较日志和系统状态来决定是继续完成操作还是撤销操作。
redo log 称为重做日志,每当有操作时,在数据变更之前将操作写入 redo log,这样当发生断电之类的情况时系统可以在重启后继续操作。undo log 称为撤销日志,当一些变更执行到一半无法完成时,可以根据撤销日志恢复到变更之间的状态。
Loki 中的 WAL 记录了传入的数据,并将其存储在本地文件系统中,以保证在进程崩溃的情况下持久保存已确认的数据。重新启动后,Loki 将重放日志中的所有数据,然后将自身注册,准备进行后续写操作。这使得 Loki 能够保持在内存中缓冲数据的性能和成本优势,以及持久性优势(一旦写被确认,它就不会丢失数据)。
查询前端
查询前端是一个可选的服务,提供 querier 的 API 端点,可以用来加速读取路径。当查询前端就位时,应将传入的查询请求定向到查询前端,而不是 querier, 为了执行实际的查询,群集中仍需要 querier 服务。
查询前端在内部执行一些查询调整,并在内部队列中保存查询。querier 作为 workers 从队列中提取作业,执行它们,并将它们返回到查询前端进行汇总。querier 需要配置查询前端地址(通过-querier.frontend-address CLI 标志),以便允许它们连接到查询前端。
查询前端是无状态的,然而,由于内部队列的工作方式,建议运行几个查询前台的副本,以获得公平调度的好处,在大多数情况下,两个副本应该足够了。
队列
查询前端的排队机制用于:
确保可能导致 querier出现内存不足(OOM)错误的查询在失败时被重试。这允许管理员可以为查询提供不足的内存,或者并行运行更多的小型查询,这有助于降低总成本。通过使用先进先出队列(FIFO)将多个大型请求分配到所有 querier上,以防止在单个querier中传送多个大型请求。通过在租户之间公平调度查询。
分割
查询前端将较大的查询分割成多个较小的查询,在下游 querier 上并行执行这些查询,并将结果再次拼接起来。这可以防止大型查询在单个查询器中造成内存不足的问题,并有助于更快地执行这些查询。
缓存
查询前端支持缓存指标查询结果,并在后续查询中重复使用。如果缓存的结果不完整,查询前端会计算所需的子查询,并在下游 querier 上并行执行这些子查询。查询前端可以选择将查询与其 step 参数对齐,以提高查询结果的可缓存性。结果缓存与任何 loki 缓存后端(当前为 memcached、redis 和内存缓存)兼容。
Querier
Querier 查询器服务使用 LogQL 查询语言处理查询,从 ingesters 和长期存储中获取日志。
查询器查询所有 ingesters 的内存数据,然后再到后端存储运行相同的查询。由于复制因子,查询器有可能会收到重复的数据。为了解决这个问题,查询器在内部对具有相同纳秒时间戳、标签集和日志信息的数据进行重复数据删除。
Chunk 格式
-------------------------------------------------------------------
| | |
| MagicNumber(4b) | version(1b) |
| | |
-------------------------------------------------------------------
| block-1 bytes | checksum (4b) |
-------------------------------------------------------------------
| block-2 bytes | checksum (4b) |
-------------------------------------------------------------------
| block-n bytes | checksum (4b) |
-------------------------------------------------------------------
| #blocks (uvarint) |
-------------------------------------------------------------------
| #entries(uvarint) | mint, maxt (varint) | offset, len (uvarint) |
-------------------------------------------------------------------
| #entries(uvarint) | mint, maxt (varint) | offset, len (uvarint) |
-------------------------------------------------------------------
| #entries(uvarint) | mint, maxt (varint) | offset, len (uvarint) |
-------------------------------------------------------------------
| #entries(uvarint) | mint, maxt (varint) | offset, len (uvarint) |
-------------------------------------------------------------------
| checksum(from #blocks) |
-------------------------------------------------------------------
| #blocks section byte offset |
-------------------------------------------------------------------
mint 和 maxt分别描述了最小和最大的 Unix 纳秒时间戳。
Block 格式
一个 block 由一系列日志 entries 组成,每个 entry 都是一个单独的日志行。
请注意,一个 block 的字节是用 Gzip 压缩存储的。以下是它们未压缩时的形式。
-------------------------------------------------------------------
| ts (varint) | len (uvarint) | log-1 bytes |
-------------------------------------------------------------------
| ts (varint) | len (uvarint) | log-2 bytes |
-------------------------------------------------------------------
| ts (varint) | len (uvarint) | log-3 bytes |
-------------------------------------------------------------------
| ts (varint) | len (uvarint) | log-n bytes |
-------------------------------------------------------------------
ts 是日志的 Unix 纳秒时间戳,而 len 是日志条目的字节长度。
Chunk 存储
Chunk 存储是 Loki 的长期数据存储,旨在支持交互式查询和持续写入,不需要后台维护任务。它由以下部分组成:
一个 chunks 索引,这个索引可以通过以下方式支持:Amazon DynamoDB、Google Bigtable、Apache Cassandra。 一个用于 chunk 数据本身的键值(KV)存储,可以是:Amazon DynamoDB、Google Bigtable、Apache Cassandra、Amazon S3、Google Cloud Storage。
与 Loki 的其他核心组件不同,块存储不是一个单独的服务、任务或进程,而是嵌入到需要访问 Loki 数据的
ingester和querier服务中的一个库。
块存储依赖于一个统一的接口,用于支持块存储索引的 NoSQL 存储(DynamoDB、Bigtable 和 Cassandra)。这个接口假定索引是由以下项构成的键的条目集合。
一个哈希 key,对所有的读和写都是必需的。 一个范围 key,写入时需要,读取时可以省略,可以通过前缀或范围进行查询。
该接口在支持的数据库中的工作方式有些不同:
DynamoDB原生支持范围和哈希键,因此,索引条目被直接建模为 DynamoDB 条目,哈希键作为分布键,范围作为 DynamoDB 范围键。对于 Bigtable和Cassandra,索引条目被建模为单个列值。哈希键成为行键,范围键成为列键。
一组模式集合被用来将读取和写入块存储时使用的匹配器和标签集映射到索引上的操作。随着 Loki 的发展,Schemas 模式也被添加进来,主要是为了更好地平衡写操作和提高查询性能。
读取路径
日志读取路径的流程如下所示:
查询器收到一个对数据的 HTTP 请求。 查询器将查询传递给所有 ingesters以获取内存数据。ingesters收到读取请求,并返回与查询相匹配的数据(如果有的话)。如果没有 ingesters返回数据,查询器会从后端存储加载数据,并对其运行查询。查询器对所有收到的数据进行迭代和重复计算,通过 HTTP 连接返回最后一组数据。
写入路径

整体的日志写入路径如下所示:
distributor收到一个 HTTP 请求,以存储流的数据。每个流都使用哈希环进行哈希操作。 distributor将每个流发送到合适的ingester和他们的副本(基于配置的复制因子)。每个 ingester将为日志流数据创建一个块或附加到一个现有的块上。每个租户和每个标签集的块是唯一的。distributor通过 HTTP 连接响应一个成功代码。