
简单的方式创建分布式应用程序
共 4601字,需浏览 10分钟
·
2021-09-03 23:09
面对计算密集型的任务,除了多进程,就是分布式计算,如何用 Python 实现分布式计算呢?今天分享一个很简单的方法,那就是借助于 Ray。
什么是 Ray
Ray 是基于 Python 的分布式计算框架,采用动态图计算模型,提供简单、通用的 API 来创建分布式应用。使用起来很方便,你可以通过装饰器的方式,仅需修改极少的的代码,让原本运行在单机的 Python 代码轻松实现分布式计算,目前多用于机器学习。
Ray 的特色:
1、提供用于构建和运行分布式应用程序的简单原语。
2、使用户能够并行化单机代码,代码更改很少甚至为零。
3、Ray Core 包括一个由应用程序、库和工具组成的大型生态系统,以支持复杂的应用程序。比如 Tune、RLlib、RaySGD、Serve、Datasets、Workflows。
安装 Ray
最简单的安装官方版本的方式:
pip install -U ray
pip install 'ray[default]'
如果是 Windows 系统,要求必须安装 Visual C++ runtime
其他安装方式见官方文档。
使用 Ray
一个装饰器就搞定分布式计算:
import ray
ray.init()
@ray.remote
def f(x):
return x * x
futures = [f.remote(i) for i in range(4)]
print(ray.get(futures)) # [0, 1, 4, 9]
先执行 ray.init(),然后在要执行分布式任务的函数前加一个装饰器 @ray.remote 就实现了分布式计算。装饰器 @ray.remote 也可以装饰一个类:
import ray
ray.init()
@ray.remote
class Counter(object):
def __init__(self):
self.n = 0
def increment(self):
self.n += 1
def read(self):
return self.n
counters = [Counter.remote() for i in range(4)]
tmp1 = [c.increment.remote() for c in counters]
tmp2 = [c.increment.remote() for c in counters]
tmp3 = [c.increment.remote() for c in counters]
futures = [c.read.remote() for c in counters]
print(ray.get(futures)) # [3, 3, 3, 3]
当然了,上述的分布式计算依然是在自己的电脑上进行的,只不过是以分布式的形式。程序执行的过程中,你可以输入 http://127.0.0.1:8265/#/ 查看分布式任务的执行情况:
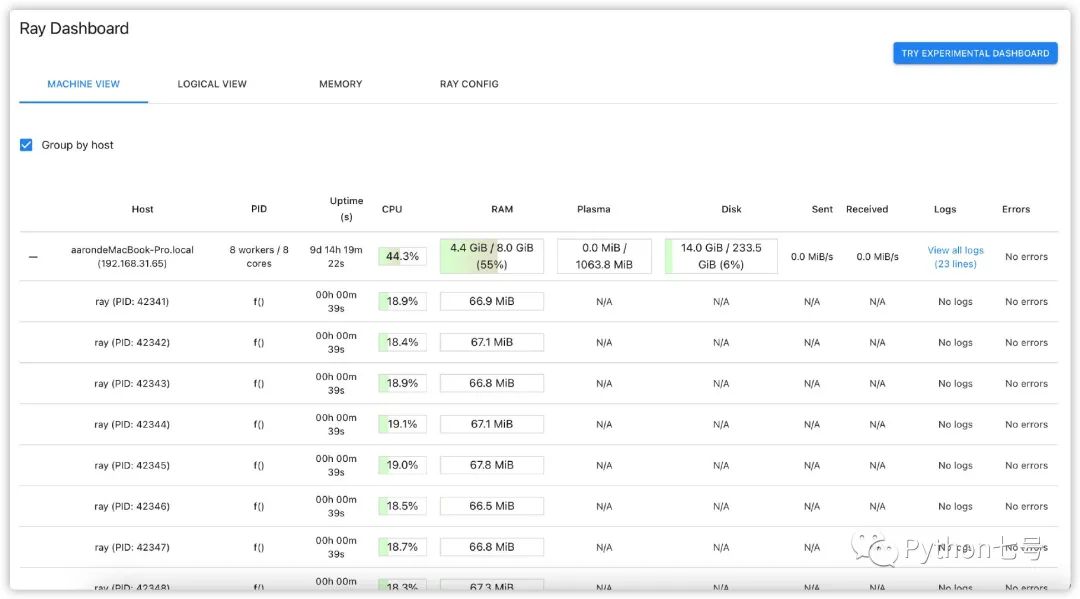
那么如何实现 Ray 集群计算呢?接着往下看。
使用 Ray 集群
Ray 的优势之一是能够在同一程序中利用多台机器。当然,Ray 可以在一台机器上运行,因为通常情况下,你只有一台机器。但真正的力量是在一组机器上使用 Ray。
Ray 集群由一个头节点和一组工作节点组成。需要先启动头节点,给 worker 节点赋予头节点地址,组成集群:
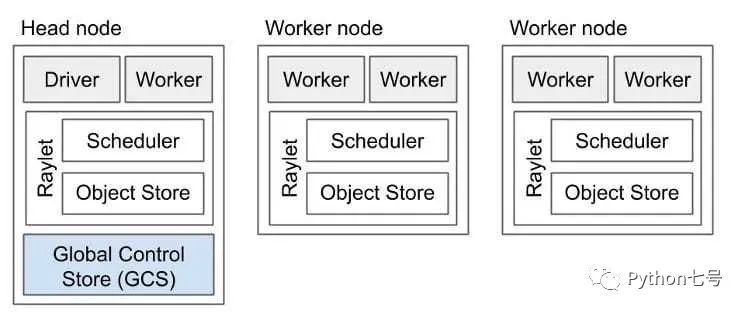
你可以使用 Ray Cluster Launcher 来配置机器并启动多节点 Ray 集群。你可以在 AWS、GCP、Azure、Kubernetes、阿里云、内部部署和 Staroid 上甚至在你的自定义节点提供商上使用集群启动器。
Ray 集群还可以利用 Ray Autoscaler,它允许 Ray 与云提供商交互,以根据规范和应用程序工作负载请求或发布实例。
现在,我们来快速演示下 Ray 集群的功能,这里是用 Docker 来启动两个 Ubuntu 容器来模拟集群:
环境 1: 172.17.0.2 作为 head 节点 环境 2: 172.17.0.3 作为 worker 节点,可以有多个 worker 节点
具体步骤:
1. 下载 ubuntu 镜像
docker pull ubuntu
2. 启动 ubuntu 容器,安装依赖
启动第一个
docker run -it --name ubuntu-01 ubuntu bash
启动第二个
docker run -it --name ubuntu-02 ubuntu bash
检查下它们的 IP 地址:
$ docker inspect -f "{{ .NetworkSettings.IPAddress }}" ubuntu-01
172.17.0.2
$ docker inspect -f "{{ .NetworkSettings.IPAddress }}" ubuntu-02
172.17.0.3
然后分别在容器内部安装 python、pip、ray
apt update && apt install python3
apt install python3-pip
pip3 install ray
3. 启动 head 节点和 worker 节点
选择在其中一个容器作为 head 节点,这里选择 172.17.0.2,执行:
ray start --head --node-ip-address 172.17.0.2
默认端口是 6379,你可以使用 --port 参数来修改默认端口,启动后的结果如下:
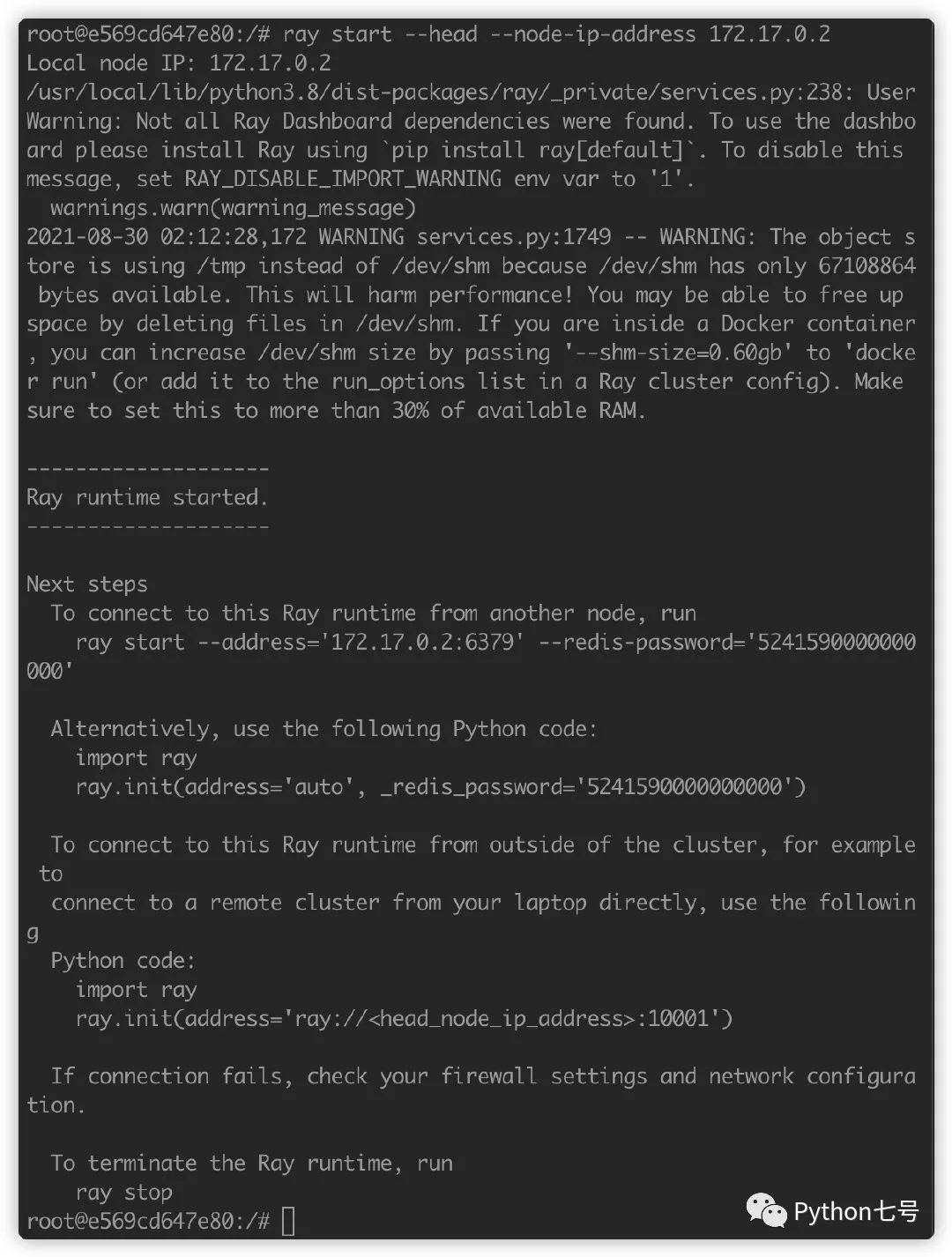
忽略掉警告,可以看到给出了一个提示,如果要把其他节点绑定到该 head,可以这样:
ray start --address='172.17.0.2:6379' --redis-password='5241590000000000'
在另一个节点执行上述命令,即可启动 worker 节点:
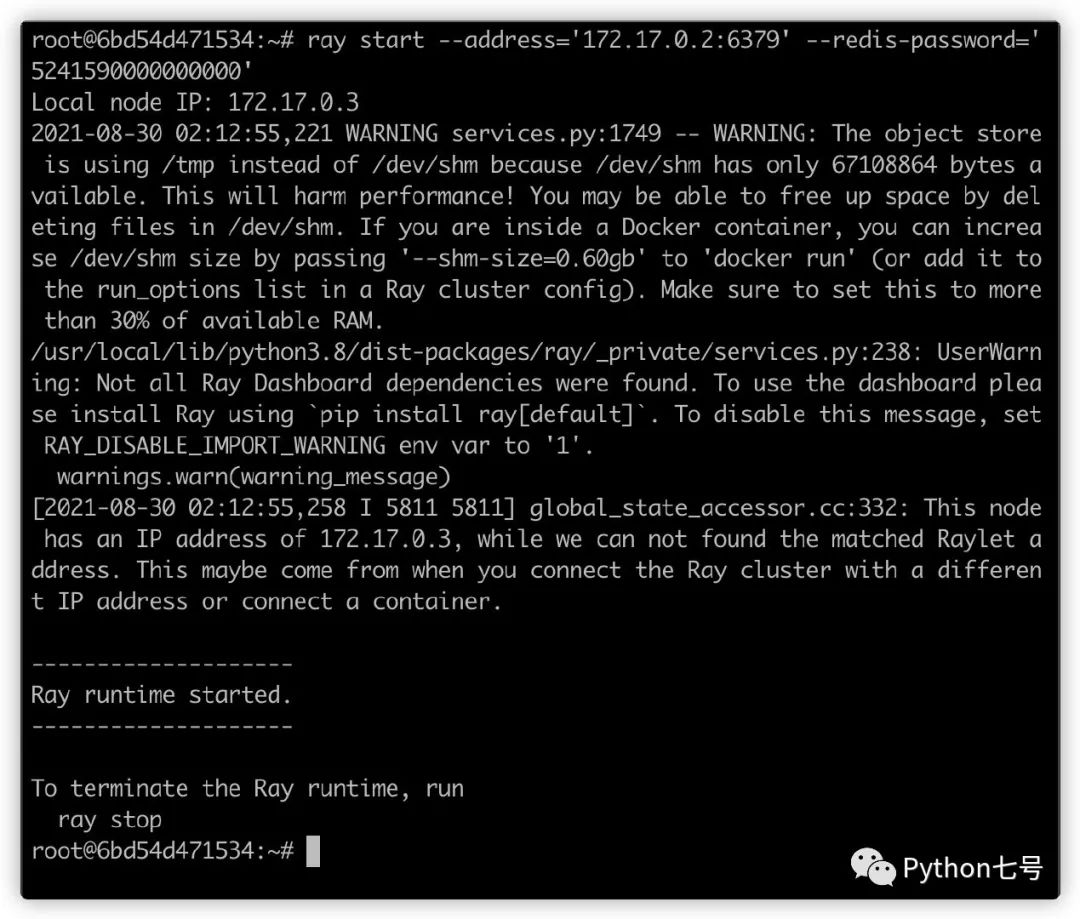
如果要关闭,执行:
ray stop
4、执行任务
随便选择一个节点,执行下面的脚本,修改下 ray.init() 函数的参数:
from collections import Counter
import socket
import time
import ray
ray.init(address='172.17.0.2:6379', _redis_password='5241590000000000')
print('''This cluster consists o f
{} nodes in total
{} CPU resources in total
'''.format(len(ray.nodes()), ray.cluster_resources()['CPU']))
@ray.remote
def f():
time.sleep(0.001)
# Return IP address.
return socket.gethostbyname(socket.gethostname())
object_ids = [f.remote() for _ in range(10000)]
ip_addresses = ray.get(object_ids)
print('Tasks executed')
for ip_address, num_tasks in Counter(ip_addresses).items():
print(' {} tasks on {}'.format(num_tasks, ip_address))
执行结果如下:
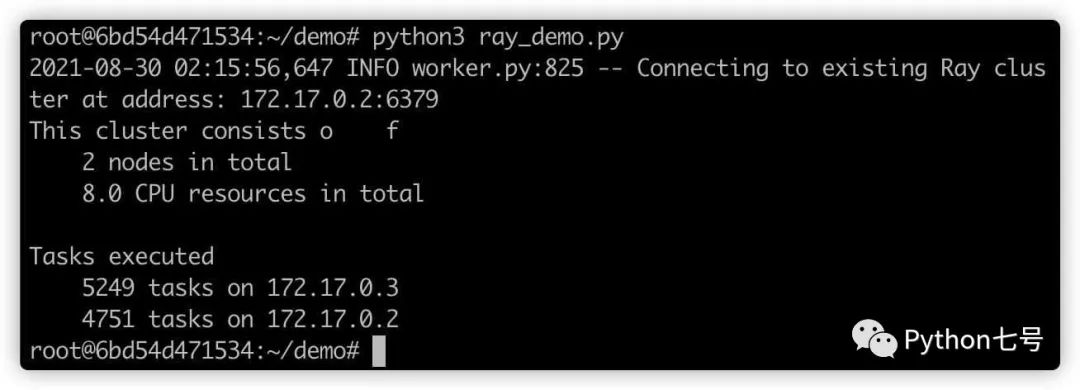
可以看到 172.17.0.2 执行了 4751 个任务,172.17.0.3 执行了 5249 个任务,实现了分布式计算的效果。
最后的话
有了 Ray,你可以不使用 Python 的多进程就可以实现并行计算。今天的机器学习主要就是计算密集型任务,不借助分布式计算速度会非常慢,Ray 提供了简单实现分布式计算的解决方案。官方文档提供了很详细的教程和样例,感兴趣的可以去了解下。
如果有帮助,不妨随手一个关注,每天学点 Python 技术。有问题也可以留言讨论。