
what? 还不知道布隆过滤器吗?
共 2147字,需浏览 5分钟
·
2021-12-15 10:32

前言
在好早之前,我在看面试宝典的时候,关于预防缓存雪崩,其中有一个解决方案就是在缓存前面增加布隆过滤器,时至今日,我依然清晰地记着布隆过滤器,但是却不曾深入的了解它,所以今天我想花一点时间来详细了解下布隆过滤器。
布隆过滤器
什么是布隆过滤器?
简单来说,布隆过滤器是一种算法,用于判断某个值是否在一个集合中。
通常来说,我们要判断一个值是否存在集合中,我们是需要将目标值和集合中的每个值进行比较,最终确定是否包含,这样的缺点也很明显,如果数据量本身很庞大的话,我们需要存储的数据量会很多,而且比较的时候也会比较耗时。
相比而言,布隆过滤器的设计就独特了很多,它通过一个Hash函数将一个元素映射成一个位阵列(Bit array)中的一个点。这样一来,我们只要看看这个点是不是1就可以知道集合中有没有它了,这就是布隆过滤器的基本思想。
但是Hash面临的最大问题就是hash冲突。假设Hash函数是良好的,如果我们的位阵列长度为m个点,那么如果我们想将冲突率降低到例如 1%,这个散列表就只能容纳m / 100个元素。显然这就不叫空间效率了(Space-efficient)了。解决方法也简单,就是使用多个Hash,如果它们有一个说元素不在集合中,那肯定就不在。如果它们都说在,虽然也有一定可能性它们在说谎,不过直觉上判断这种事情的概率是比较低的,这个概率我们通常称之为误差率。
所以,简单总结下,布隆过滤器其实就是通过hash来描述一个数据,然后保存该数据的hash值,从而实现数据的判断,但是由于hash的冲突(具体取决于hash表的大小),会导致数据的误判,所以本质上我们布隆过滤器的误判是由于hash表的有限性。
关于hash
hash算法我这里不打算展开(目前我也不是很熟悉i😂),但是我这里想要通过一个简单的示例,来解释下什么是hash。
我们小学二年级的时候,学过平面上两个坐标可以确定唯一一个点(坐标),而我们判断两个点是否是同一个点,是可以通过坐标对比来实现,而hash算法其实本身就相当于一套坐标系,通过这套坐标系理论上我们是可以描述所有数据,且可以确定数据的唯一性(当然具体取决于hash表大小)。
另外一种hash的典型应用就是我们的身份证,每个人的身份证号就是我们每个人的hash code,通过这个hash code就可以在14亿人中确定唯一的你,所以身份证号算法就是一种类似于hash的算法。
博隆过滤器的应用
上面其实我们已经列举了博隆过滤器的典型应用场景——校验某个数据是否存在,所以我们经常把他用在一些需要进行数据否存在的校验上,最典型的就是用在缓存的key的判断上,作为缓存系统最后的屏障。
在通常的系统开发中,我们经常要用到缓存组件,而缓存中最核心的一个场景就是查询,而缓存查询中操作频次最高就是判断某个key是否存在,正常情况下简单的业务判断是没有问题的,就算批量很大,也不会出现大批量key不存在的情况,但是如果遇到恶意攻击时,一切都变得不那么确定了,比如有人发送大量恶意请求专门查询不存在的key,这时候就会导致redis服务不可用,从而导致缓存雪崩。
这时候如果我们用了布隆过滤器这样的组件,这样的问题就不会影响如此严重,因为布隆过滤器可以帮我们屏蔽到绝大多数的请求,从而降低redis雪崩的风险。
关于布隆过滤器的实现,网上其实有很多实现,但最典型的当属guava包中提供的BloomFilter。要说guava真是个好用的工具包,提供了各种各样好用的工具,比如限流组件、容器组件以及今天我们分享的布隆过滤器,下面我们看下如何使用BloomFilter:
由于BloomFilter的构造方案是私有的,所以我们没有办法通过new的方式实例化BloomFilter,但是官方提供了实例化的方式——create方法:
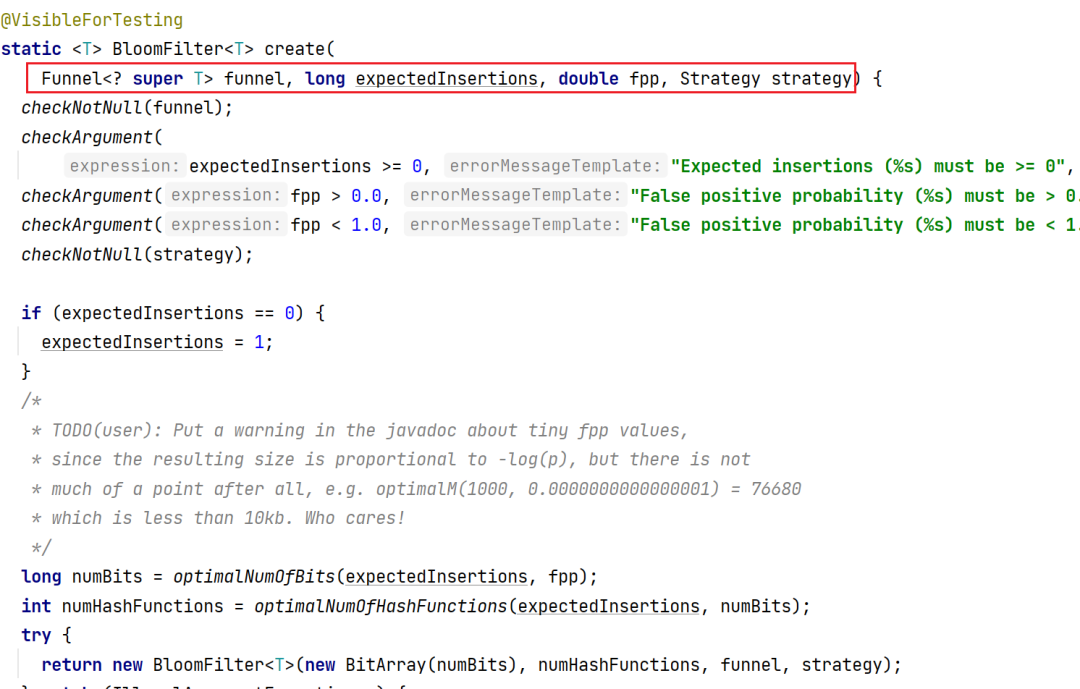
其他的create方法都是在此基础上做的封装,所以我们只简单分析上面这个方法。
这个方案有四个参数:
Funnel表示我们要过滤的数据类别,它相当于我们的漏斗,也算是容器,用于判断数据是否存在,目前在Funnels类中提供了六种实现,应该可以满足我们绝大多数场景;
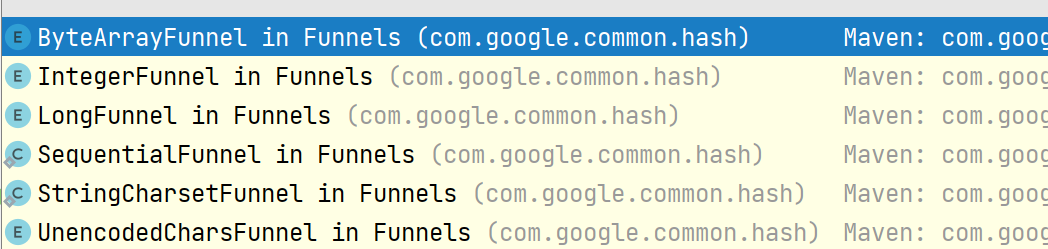
expectedInsertions表示预期样本,也就类似于我们前面说的hash表的大小,如果该数据太小,误差率会很大,原则上来说,这个数要大于等于我们要判断的样本数量,否则没有办法保证准确度,当然也不能太大,过大会有性能问题fpp表示误差率,默认是0.003
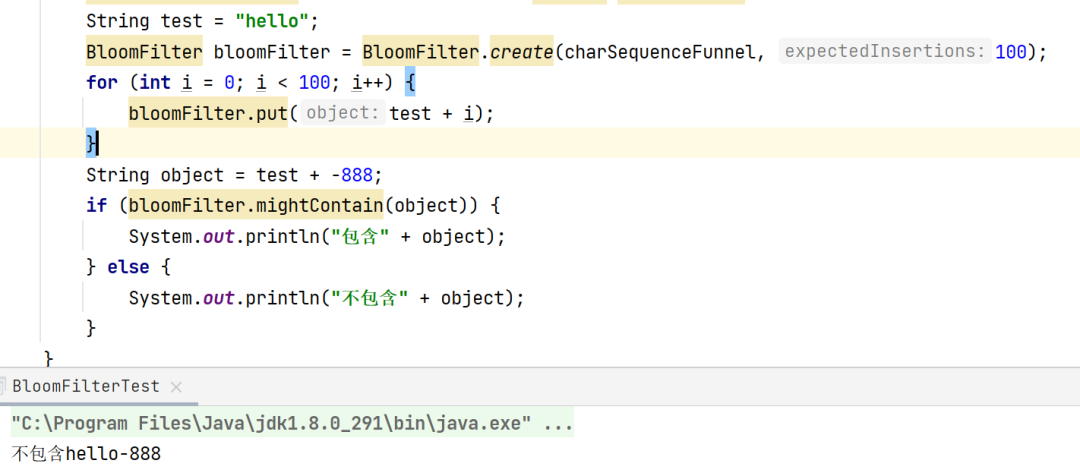
下面是一个简单的示例
public class BloomFilterTest {
public static void main(String[] args) {
Funnel charSequenceFunnel = Funnels.stringFunnel(Charset.defaultCharset());
String test = "hello";
BloomFilter bloomFilter = BloomFilter.create(charSequenceFunnel, 100);
for (int i = 0; i < 100; i++) {
bloomFilter.put(test + i);
}
String object = test + -888;
if (bloomFilter.mightContain(object)) {
System.out.println("包含" + object);
} else {
System.out.println("不包含" + object);
}
}
}
正常情况下,会打印输入不包含hello-888:
但是如果我将样本数量变小或者将数据量变大,这时候就会出现误判的情况。
比如这里我判断的是hello-888,bloomFilter中保存的应该是hello0到hello999,应该是不存在才对,但是由于hash表(代称)不够大,所以会出现数据描述精度丢失问题:
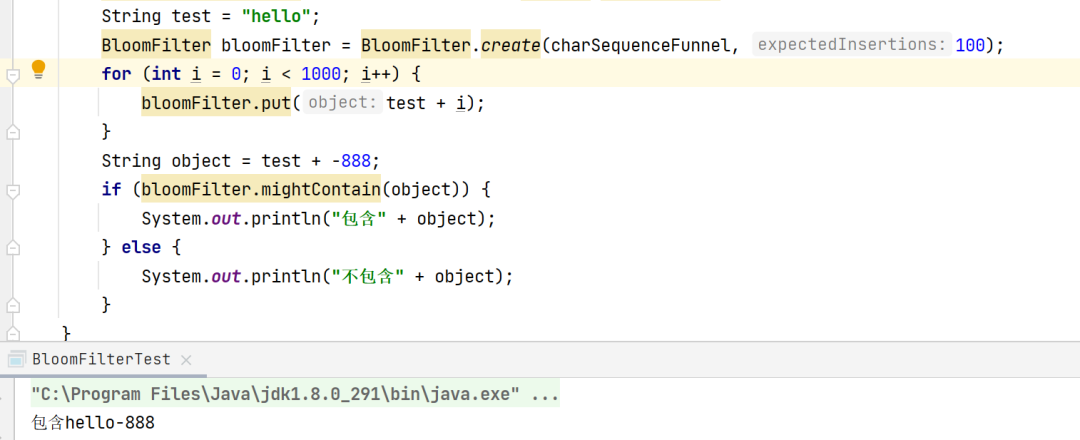
但是如果样本数量和数据本身数量差别不大时,则不会出现这种情况。
扩展
Redis v4.0 之后的版本有了 Module(模块/插件) 功能,Redis Modules 可以让 Redis 通过使用外部模块扩展其功能 ,而布隆过滤器就是其中的 Module。详情可以查看 Redis 官方对 Redis Modules 的介绍 :
https://redis.io/modules
另外,官网推荐了一个RedisBloom 作为 Redis 布隆过滤器的Module,地址:
https://github.com/RedisBloom/RedisBloom
另外,redis客户端工具Redisson也提供了布隆过滤器的实现,其底层使用数据结构是bitMap,有兴趣的小伙伴可以去了解下。
结语
布隆过滤器这个东东,已经在我心头萦绕了很久了,但是一直都没有花时间探索过,对它只能算知道有这么个组件,知道它的大概用途,但是对于它的原理和实现逻辑,却不曾了解。今天抽时间做一次简单的探索,也算是搞清楚了布隆过滤器的应用场景和简单的实现原理,当然也清楚了自己在数据底层的短板,比如数据结构——散列,说明我也该好好补下数据结构这块的知识了,数据结构那本书该翻一翻了😂,好了,今天就到这里吧,各位小伙伴,晚安吧!
- END -