
姿态估计:人体骨骼关键点检测综述(2016-2020)
极市平台
共 9855字,需浏览 20分钟
·
2020-08-06 00:14
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
目录
一、前言
二、相关数据集
三、Ground Truth的构建
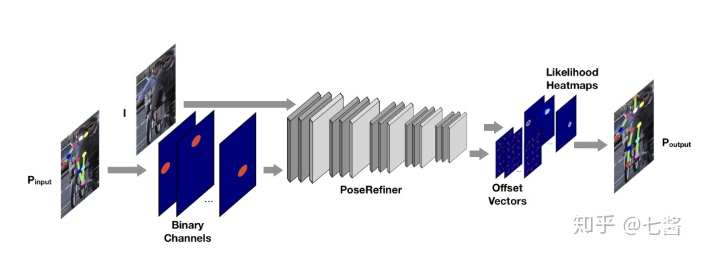
四、单人关键点检测的发展(2016-2019)
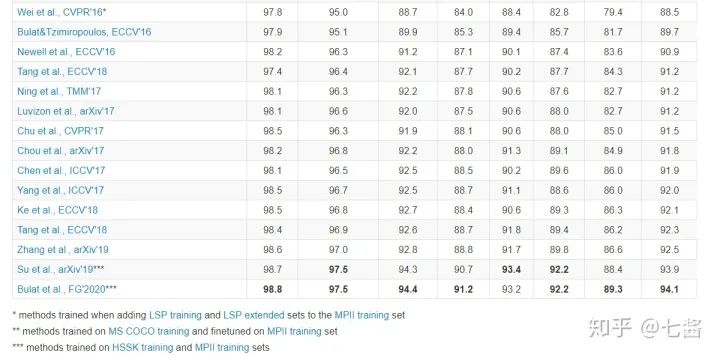
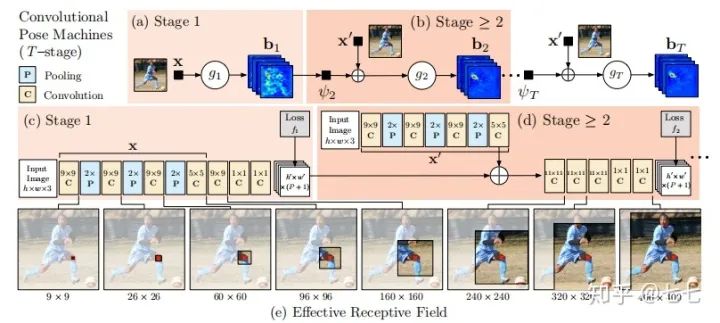
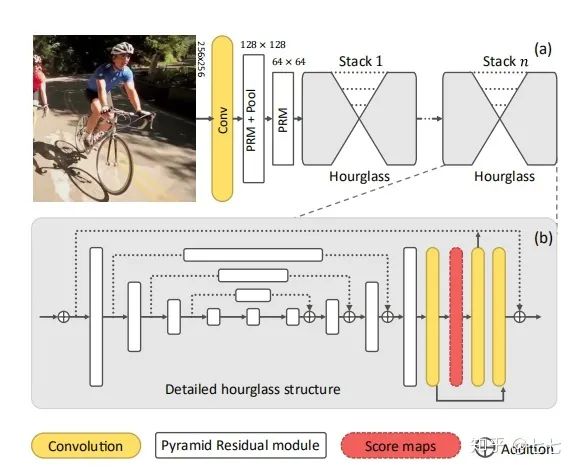
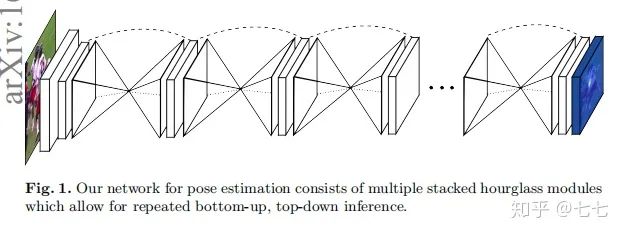

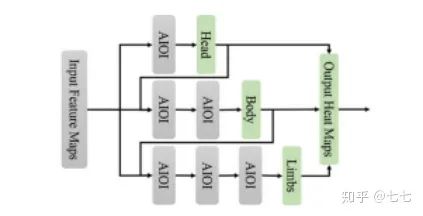
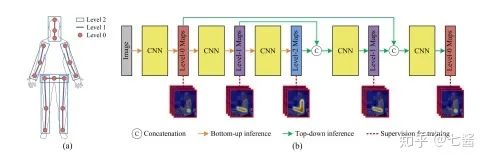
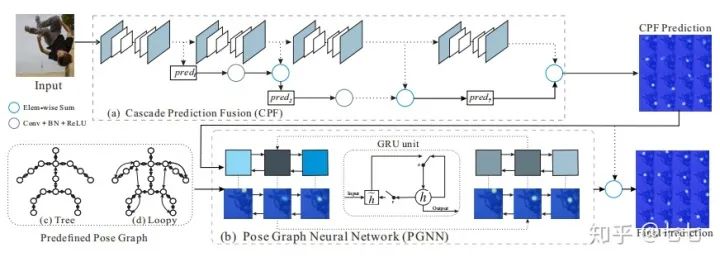
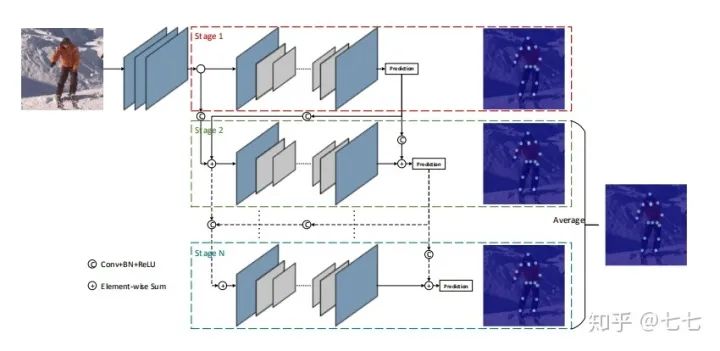
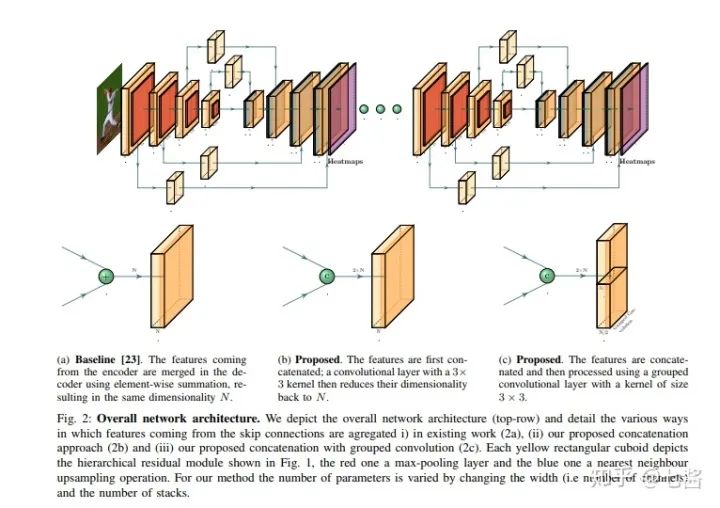
五、多人关键点检测
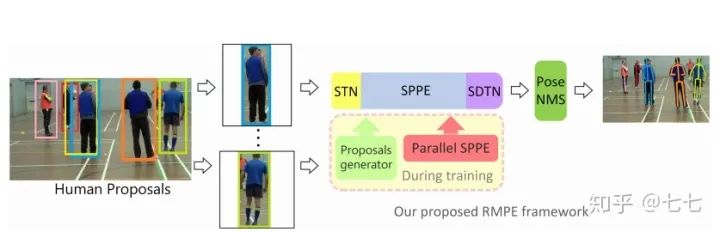
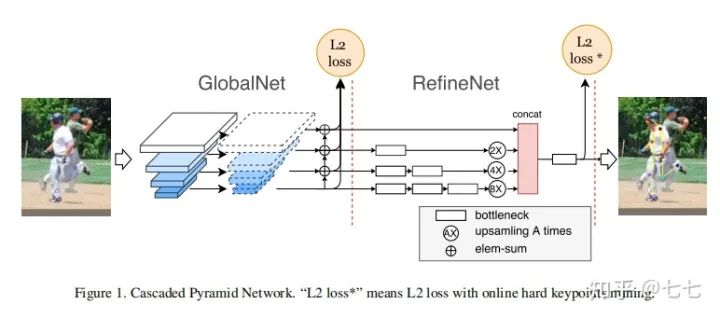
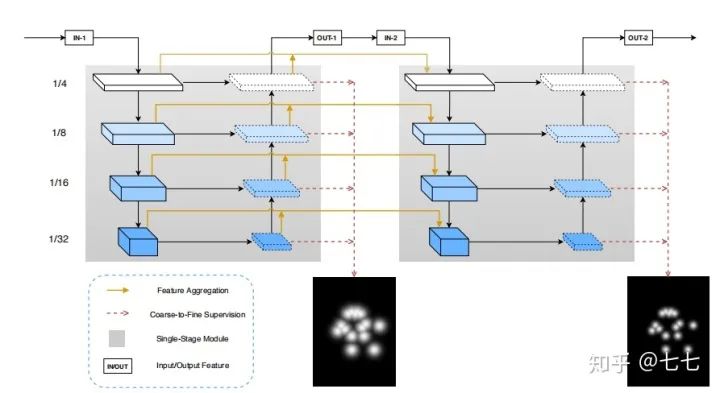
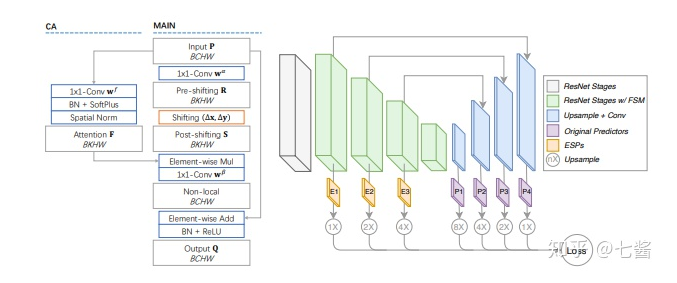
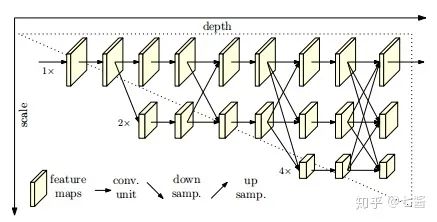
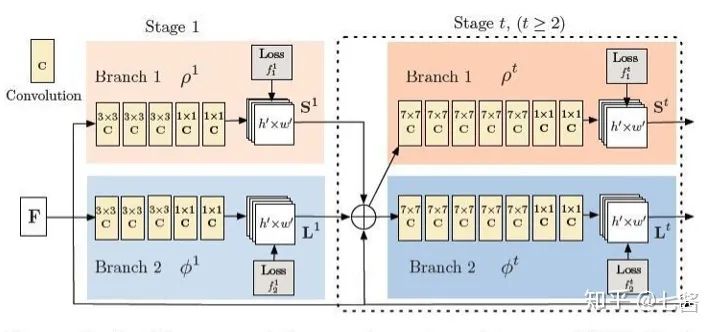
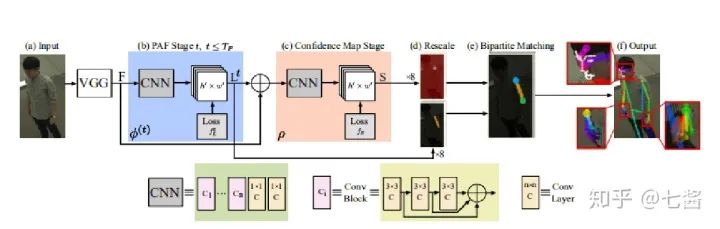
六、3D关键点检测的算法
七、2020CVPR姿态估计相关文章跟新
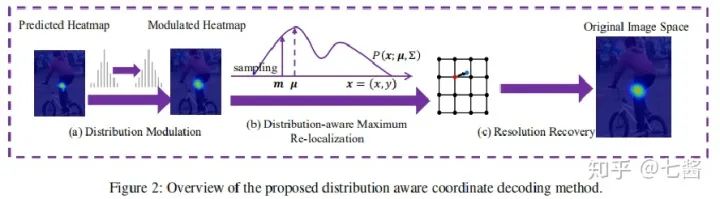
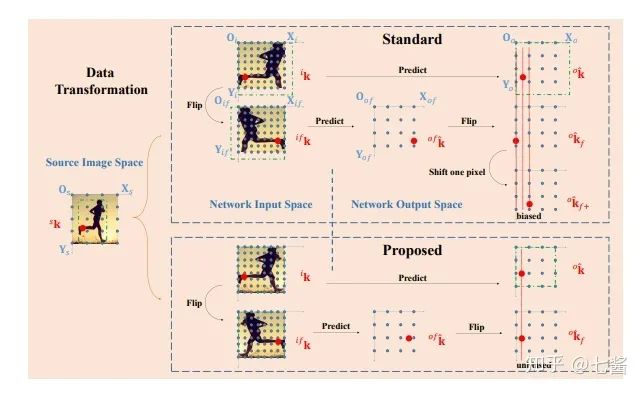
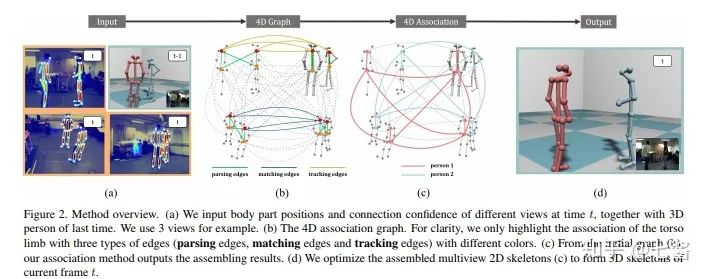

评论