
计算机视觉"新"范式: Transformer

极市导读
近期,Transformer一改人们对其不适合计算机视觉视觉领域的印象,在几个工作所展现出来性能达CNN的SOTA。本文对Transformer在计算机视觉领域的应用进行了回顾与思考。>>加入极市CV技术交流群,走在计算机视觉的最前沿
自从Transformer出来以后,Transformer便开始在NLP领域一统江湖。而Transformer在CV领域反响平平,一度认为不适合CV领域,直到最近计算机视觉领域出来几篇Transformer文章,性能直逼CNN的SOTA,给予了计算机视觉领域新的想象空间。
本文不拘泥于Transformer原理和细节实现(知乎有很多优质的Transformer解析文章,感兴趣的可以看看),着重于Transformer对计算机视觉领域的革新。
首先简略回顾一下Transformer,然后介绍最近几篇计算机视觉领域的Transformer文章,其中ViT用于图像分类,DETR和Deformable DETR用于目标检测。从这几篇可以看出,Transformer在计算机视觉领域的范式已经初具雏形,可以大致概括为:Embedding -> Transformer -> Head
一些有趣的点写在最后~~
Transformer
Transformer详解
The Illustrated Transformer
https://jalammar.github.io/illustrated-transformer/
打不开的可以关注一下Smarter公众号,回复"Transformer详解"获取文章
下面以机器翻译为例子,简略介绍Transformer结构。
1. Encoder-Decoder
Transformer结构可以表示为Encoder和Decoder两个部分
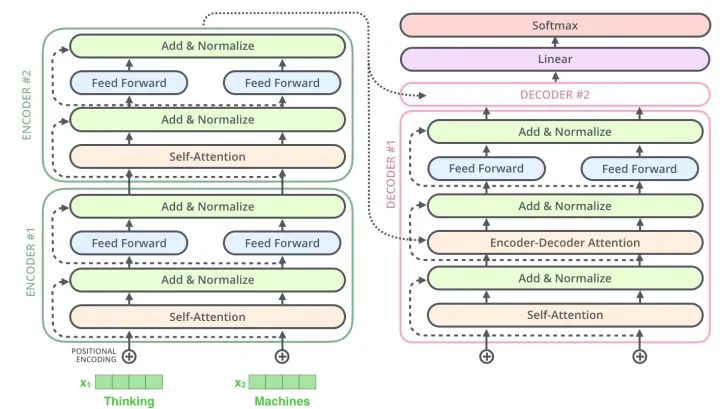
Encoder和Decoder主要由Self-Attention和Feed-Forward Network两个组件构成,Self-Attention由Scaled Dot-Product Attention和Multi-Head Attention两个组件构成。
Scaled Dot-Product Attention公式:
Multi-Head Attention公式:
Feed-Forward Network公式:
2. Positional Encoding
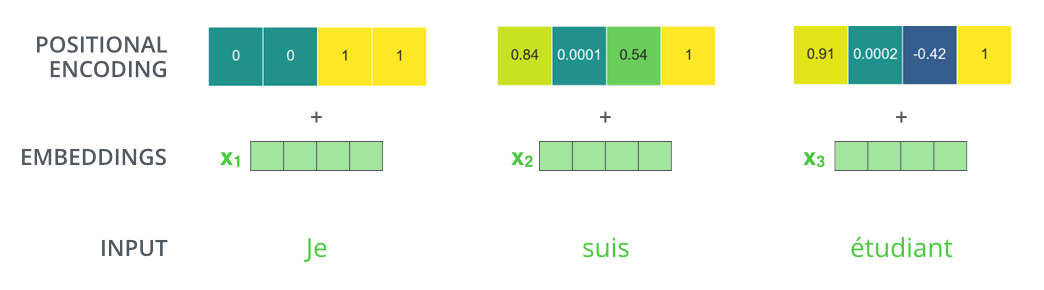
如图所示,由于机器翻译任务跟输入单词的顺序有关,Transformer在编码输入单词的嵌入向量时引入了positional encoding,这样Transformer就能够区分出输入单词的位置了。
引入positional encoding的公式为:
是位置, 是维数, 是输入单词的嵌入向量维度。
3. Self-Attention
3.1 Scaled Dot-Product Attention
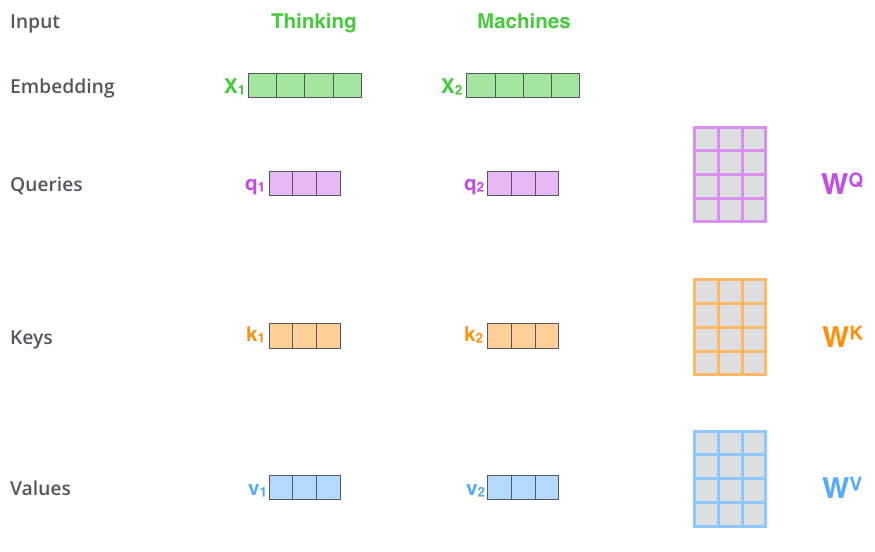
在Scaled Dot-Product Attention中,每个输入单词的嵌入向量分别通过3个矩阵,和 来分别得到Query向量(),Key向量()和Value向量()。
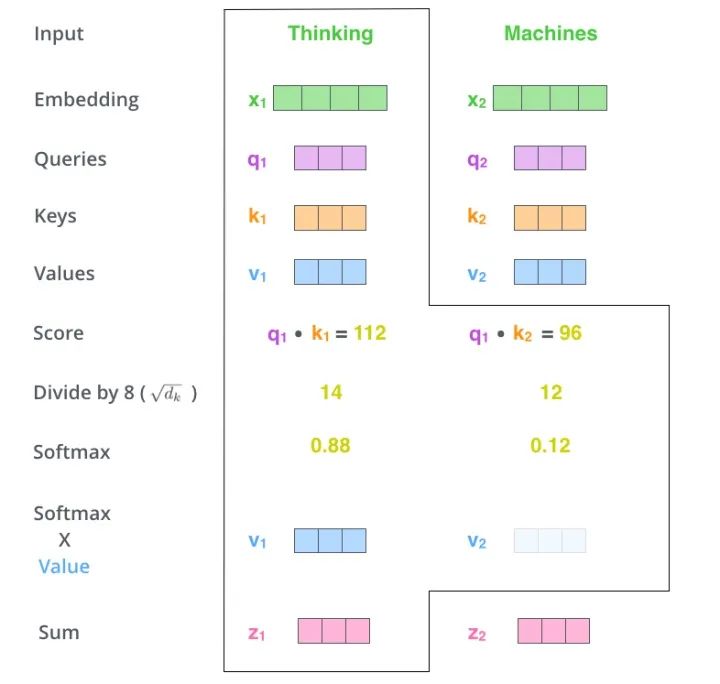
如图所示,Scaled Dot-Product Attention的计算过程可以分成7个步骤:
每个输入单词转化成嵌入向量。 根据嵌入向量得到,,三个向量。 通过向量计算 : 。 对 ,进行归一化,即除以。 通过激活函数计算。 点乘Value值,得到每个输入向量的评分。 所有输入向量的评分之和为:。
上述步骤的矩阵形式可以表示成:
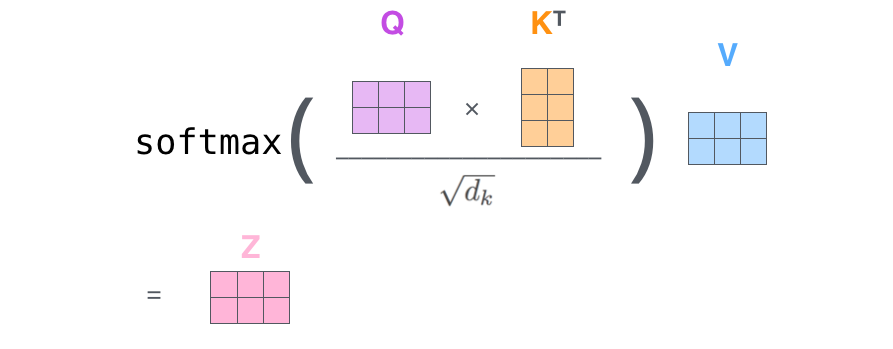
与Scaled Dot-Product Attention公式一致。
3.2 Multi-Head Attention
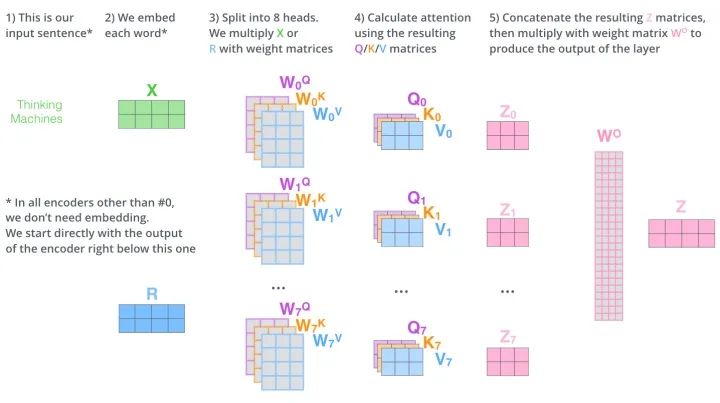
如图所示,Multi-Head Attention相当于h个不同Scaled Dot-Product Attention的集成,以h=8为例子,Multi-Head Attention步骤如下:
将数据 分别输入到8个不同的Scaled Dot-Product Attention中,得到8个加权后的特征矩阵 。 将8个 按列拼成一个大的特征矩阵。 特征矩阵经过一层全连接得到输出 。
Scaled Dot-Product Attention和Multi-Head Attention都加入了short-cut机制。
ViT
ViT将Transformer巧妙的应用于图像分类任务,更少计算量下性能跟SOTA相当。
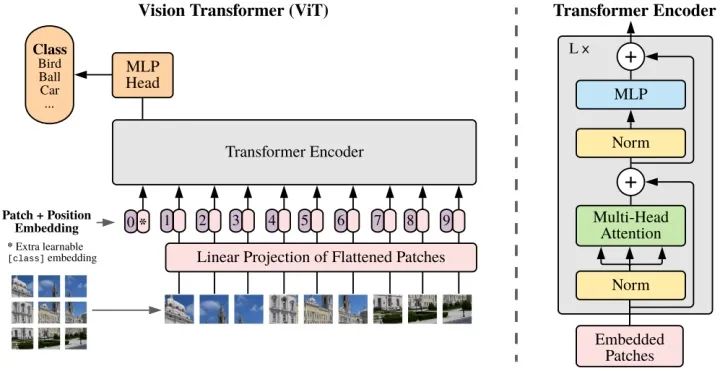
Vision Transformer(ViT)将输入图片拆分成16x16个patches,每个patch做一次线性变换降维同时嵌入位置信息,然后送入Transformer,避免了像素级attention的运算。类似BERT[class]标记位的设置,ViT在Transformer输入序列前增加了一个额外可学习的[class]标记位,并且该位置的Transformer Encoder输出作为图像特征。
其中为原图像分辨率,为每个图像patch的分辨率。为Transformer输入序列的长度。
ViT舍弃了CNN的归纳偏好问题,更加有利于在超大规模数据上学习知识,即大规模训练优归纳偏好,在众多图像分类任务上直逼SOTA。
DETR
DETR使用set loss function作为监督信号来进行端到端训练,然后同时预测所有目标,其中set loss function使用bipartite matching算法将pred目标和gt目标匹配起来。直接将目标检测任务看成set prediction问题,使训练过程变的简洁,并且避免了anchor、NMS等复杂处理。
DETR主要有两个部分:architecture和set prediction loss。
1. Architecture
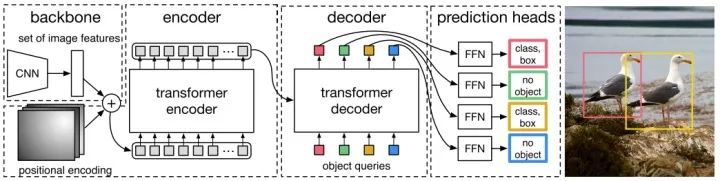
DETR先用CNN将输入图像embedding成一个二维表征,然后将二维表征转换成一维表征并结合positional encoding一起送入encoder,decoder将少量固定数量的已学习的object queries(可以理解为positional embeddings)和encoder的输出作为输入。最后将decoder得到的每个output embdding传递到一个共享的前馈网络(FFN),该网络可以预测一个检测结果(包括类和边框)或着“没有目标”的类。
1.1 Transformer
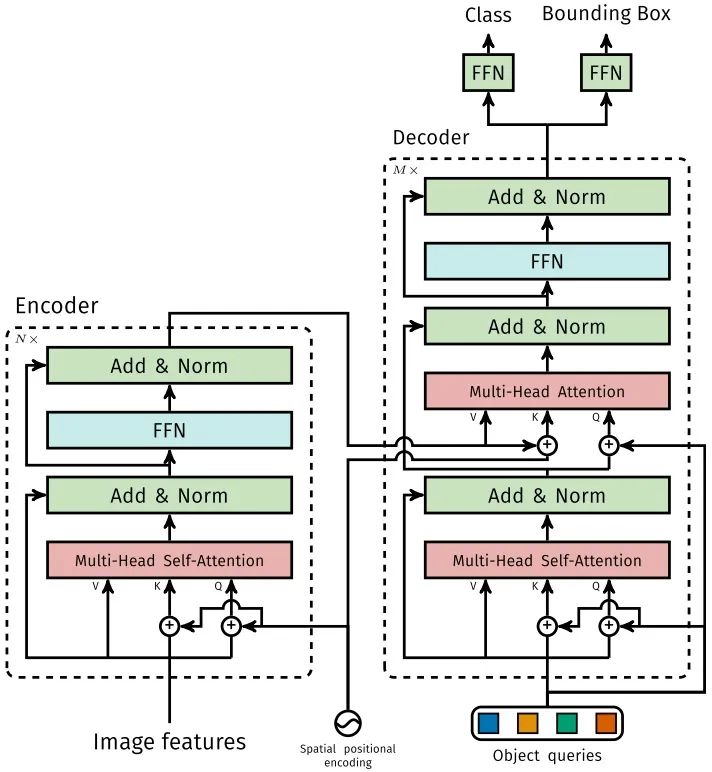
1.1.1 Encoder
将Backbone输出的feature map转换成一维表征,得到 特征图,然后结合positional encoding作为Encoder的输入。每个Encoder都由Multi-Head Self-Attention和FFN组成。
和Transformer Encoder不同的是,因为Encoder具有位置不变性,DETR将positional encoding添加到每一个Multi-Head Self-Attention中,来保证目标检测的位置敏感性。
1.1.2 Decoder
因为Decoder也具有位置不变性,Decoder的个object query(可以理解为学习不同object的positional embedding)必须是不同,以便产生不同的结果,并且同时把它们添加到每一个Multi-Head Attention中。个object queries通过Decoder转换成一个output embedding,然后output embedding通过FFN独立解码出个预测结果,包含box和class。对输入embedding同时使用Self-Attention和Encoder-Decoder Attention,模型可以利用目标的相互关系来进行全局推理。
和Transformer Decoder不同的是,DETR的每个Decoder并行输出个对象,Transformer Decoder使用的是自回归模型,串行输出个对象,每次只能预测一个输出序列的一个元素。
1.1.3 FFN
FFN由3层perceptron和一层linear projection组成。FFN预测出box的归一化中心坐标、长、宽和class。
DETR预测的是固定数量的个box的集合,并且通常比实际目标数要大的多,所以使用一个额外的空类来表示预测得到的box不存在目标。
2. Set prediction loss
DETR模型训练的主要困难是如何根据gt衡量预测结果(类别、位置、数量)。DETR提出的loss函数可以产生pred和gt的最优双边匹配(确定pred和gt的一对一关系),然后优化loss。
将 表示为gt的集合, 表示为个预测结果的集合。假设大于图片目标数, 可以认为是用空类(无目标)填充的大小为的集合。搜索两个集合个元素的不同排列顺序,使得loss尽可能的小的排列顺序即为二分图最大匹配(Bipartite Matching),公式如下:
其中表示pred和gt关于元素的匹配loss。其中二分图匹配通过匈牙利算法(Hungarian algorithm)得到。
匹配loss同时考虑了pred class和pred box的准确性。每个gt的元素可以看成,表示class label(可能是空类) 表示gt box,将元素二分图匹配指定的pred class表示为 ,pred box表示为。
第一步先找到一对一匹配的pred和gt,第二步再计算hungarian loss。
hungarian loss公式如下:
其中 结合了L1 loss和generalized IoU loss,公式如下:
ViT和DETR两篇文章的实验和可视化分析很有启发性,感兴趣的可以仔细看看~~
Deformable DETR
从DETR看,还不足以赶上CNN,因为训练时间太久了,Deformable DETR的出现,让我对Transformer有了新的期待。
Deformable DETR将DETR中的attention替换成Deformable Attention,使DETR范式的检测器更加高效,收敛速度加快10倍。
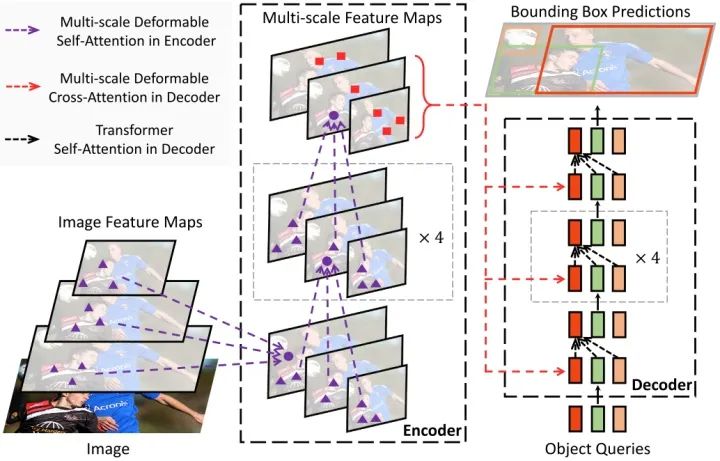
Deformable DETR提出的Deformable Attention可以可以缓解DETR的收敛速度慢和复杂度高的问题。同时结合了deformable convolution的稀疏空间采样能力和transformer的关系建模能力。Deformable Attention可以考虑小的采样位置集作为一个pre-filter突出所有feature map的关键特征,并且可以自然地扩展到融合多尺度特征,并且Multi-scale Deformable Attention本身就可以在多尺度特征图之间进行交换信息,不需要FPN操作。
1. Deformable Attention Module
给定一个query元素(如输出句子中的目标词)和一组key元素(如输入句子的源词),Multi-Head Attention能够根据query-key pairs的相关性自适应的聚合key的信息。为了让模型关注来自不同表示子空间和不同位置的信息,对multi-head的信息进行加权聚合。其中表示query元素(特征表示为),表示key元素(特征表示为),是特征维度,和 分别为和的集合。
那么Transformer 的 Multi-Head Attention公式表示为:
其中指定attention head,和是可学习参数,注意力权重并且归一化,其中是可学习参数。为了能够分辨不同空间位置,和通常会引入positional embedding。
对于DETR中的Transformer Encoder,query和key元素都是feature map中的像素。
DETR 的 Multi-Head Attention 公式表示为:
其中。
DETR主要有两个问题:需要更多的训练时间来收敛,对小目标的检测性能相对较差。本质上是因为Transfomer的Multi-Head Attention会对输入图片的所有空间位置进行计算。而Deformable DETR的Deformable Attention只关注参考点周围的一小部分关键采样点,为每个query分配少量固定数量的key,可以缓解收敛性和输入分辨率受限制的问题。
给定一个输入feature map ,表示为query元素(特征表示为),二维参考点表示为,Deformable DETR 的 Deformable Attention公式表示为:
其中指定attention head,指定采样的key,表示采样key的总数()。, 分别表示第个采样点在第个attention head的采样偏移量和注意力权重。注意力权重在[0,1]的范围内,归一化。表示为无约束范围的二维实数。因为为分数,需要采用双线性插值方法计算。
2. Multi-scale Deformable Attention Module
Deformable Attention可以很自然地扩展到多尺度的feature maps。表示为输入的多尺度feature maps,。 表示为每个query元素的参考点 的归一化坐标。Deformable DETR 的Multi-scale Deformable Attention公式表示为:
其中指定attention head,指定输入特征层,指定采样的key,表示采样key的总数( )。, 分别表示第个采样点在第特征层的第个attention head的采样偏移量和注意力权重。注意力权重在[0,1]的范围内,归一化。
3. Deformable Transformer Encoder
将DETR中所有的attention替换成multi-scale deformable attention。encoder的输入和输出都是具有相同分辨率的多尺度feature maps。Encoder从ResNet的中抽取多尺度feature maps, ( 由进行3×3 stride 2卷积得到)。
在Encoder中使用multi-scale deformable attention,输出是和输入具有相同分辨率的多尺度feature maps。query和key都来自多尺度feature maps的像素。对于每个query像素,参考点是它本身。为了判断query像素源自哪个特征层,除了positional embedding外,还添加了一个scale-level embedding,不同于positional embedding的固定编码, scale-level embedding随机初始化并且通过训练得到。
4. Deformable Transformer Decoder
Decoder中有cross-attention和self-attention两种注意力。这两种注意力的query元素都是object queries。在cross-attention中,object queries从feature maps中提取特征,而key元素是encoder输出的feature maps。在self-attention中,object queries之间相互作用,key元素也是object queries。因为Deformable Attention是用于key元素的feature maps特征提取的,所以decoder部分,deformable attention只替换cross-attention。
因为multi-scale deformable attention提取参考点周围的图像特征,让检测头预测box相对参考点的偏移量,进一步降低了优化难度。
复杂度分析
假设query和key的数量分别为、(),维度为,key采样点数为,图像的feature map大小为,卷积核尺寸为。
Convolution复杂度
为了保证输入和输出在第一个维度都相同,故需要对输入进行padding操作,因为这里kernel size为(实际kernel的形状为)。 大小为的卷积核一次运算复杂度为,一共做了次,故复杂度为。 为了保证第三个维度相等,故需要个卷积核,所以卷积操作的时间复杂度为。
Self-Attention复杂度
的计算复杂度为。 相似度计算:与运算,得到矩阵,复杂度为。 计算:对每行做 ,复杂度为,则n行的复杂度为。 加权和:与运算,得到矩阵,复杂度为。 故最后self-attention的时间复杂度为。
Transformer
Self-Attention的复杂度为。
ViT
Self-Attention的复杂度为。
DETR
Self-Attention的复杂度为。
Deformable DETR
Self-Attention的复杂度为。
分析细节看原论文
几个问题
如何理解? 为什么不使用相同的和?
1. 从点乘的物理意义上讲,两个向量的点乘表示两个向量的相似度。
2. 的物理意义是一样的,都表示同一个句子中不同token组成的矩阵。矩阵中的每一行,是表示一个token的word embedding向量。假设一个句子“Hello, how are you?”长度是6,embedding维度是300,那么都是(6,300)的矩阵。
所以和的点乘可以理解为计算一个句子中每个token相对于句子中其他token的相似度,这个相似度可以理解为attetnion score,关注度得分。虽然有了attention score矩阵,但是这个矩阵是经过各种计算后得到的,已经很难表示原来的句子了,而还代表着原来的句子,所以可以将attention score矩阵与相乘,得到的是一个加权后的结果。
经过上面的解释,我们知道和的点乘是为了得到一个attention score 矩阵,用来对进行提炼。和使用不同的, 来计算,可以理解为是在不同空间上的投影。正因为有了这种不同空间的投影,增加了表达能力,这样计算得到的attention score矩阵的泛化能力更高。这里解释下我理解的泛化能力,因为和使用了不同的, 来计算,得到的也是两个完全不同的矩阵,所以表达能力更强。但是如果不用,直接拿和点乘的话,attention score 矩阵是一个对称矩阵,所以泛化能力很差,这个矩阵对进行提炼,效果会变差。
详细分析可以看链接文章
transformer中为什么使用不同的K 和 Q, 为什么不能使用同一个值?
https://www.zhihu.com/question/319339652/answer/730848834
https://medium.com/dissecting-bert/dissecting-bert-part-1-d3c3d495cdb3
如何Position Embedding更好?
目前还是一个开放问题,知乎上有一些优质的讨论,详细分析可以看链接文章
如何理解Transformer论文中的positional encoding,和三角函数有什么关系?
https://www.zhihu.com/question/347678607/answer/864217252
Xinlong Wang:CNN是怎么学到图片内的绝对位置信息的?
https://zhuanlan.zhihu.com/p/99766566
ViT为什么要增加一个[CLS]标志位? 为什么将[CLS]标志位对应的向量作为整个序列的语义表示?
和BERT相类似,ViT在序列前添加一个可学习的[CLS]标志位。以BERT为例,BERT在第一句前添加一个[CLS]标志位,最后一层该标志位对应的向量可以作为整句话的语义表示,从而用于下游的分类任务等。
将[CLS]标志位对应的向量作为整个文本的语义表示,是因为与文本中已有的其它词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个词的语义信息,从而更好的表示整句话的语义。
归纳偏好是什么?
归纳偏置在机器学习中是一种很微妙的概念:在机器学习中,很多学习算法经常会对学习的问题做一些假设,这些假设就称为归纳偏好(Inductive Bias)。归纳偏置可以理解为,从现实生活中观察到的现象中归纳出一定的规则(heuristics),然后对模型做一定的约束,从而可以起到“模型选择”的作用,即从假设空间中选择出更符合现实规则的模型。可以把归纳偏好理解为贝叶斯学习中的“先验”。
在深度学习中,也使用了归纳偏好。在CNN中,假设特征具有局部性(Locality)的特点,即把相邻的一些特征融合到一起,会更容易得到“解”;在RNN中,假设每一时刻的计算依赖于历史计算结果;还有attention机制,也是从人的直觉、生活经验归纳得到的规则。
而Transformer可以避免CNN的局部性归纳偏好问题。举一个DETR中的例子。

训练集中没有超过13只长颈鹿的图像,DETR实验中创建了一个合成的图像来验证DETR的泛化能力,DERT可以完全找到合成的全部24只长颈鹿。这证实了DETR避免了CNN的归纳偏好问题。
如何理解Inductive bias?
https://www.zhihu.com/question/264264203/answer/830077823
二分图匹配? 匈牙利算法?
给定一个二分图G,在G的一个子图M中,M的边集{E}中的任意两条边都不依附于同一个顶点,则称M是一个匹配。求二分图最大匹配可以用匈牙利算法。
详细分析可以看链接文章
https://liam.page/2016/04/03/Hungarian-algorithm-in-the-maximum-matching-problem-of-bigraph/
ZihaoZhao:带你入门多目标跟踪(三)匈牙利算法&KM算法
https://zhuanlan.zhihu.com/p/62981901
BETR的positional embedding、object queries和slot三者之间有何关系?

DETR可视化decoder预测得到的20个slot。可以观察到每个slot学习到了特定区域的尺度大小。Object queries从这个角度看,其实有点像Faster-RCNN等目标检测器的anchor,结合encoder的positional embedding信息让每个slot往学习到的特定区域去寻找目标。
Transformer相比于CNN的优缺点?
优点:
Transformer关注全局信息,能建模更加长距离的依赖关系,而CNN关注局部信息,全局信息的捕捉能力弱。
Transformer避免了CNN中存在的归纳偏好问题。
缺点:
Transformer复杂度比CNN高,但是ViT和Deformable DETR给出了一些解决方法来降低Transformer的复杂度。
总结
Transformer给图像分类和目标检测方向带来了巨大革新,分割、跟踪、视频等方向也不远了吧
NLP和CV的关系变的越来越有趣了,虽然争议很大,但是试想一下,NLP和CV两个领域能用一种范式来表达,该有多可怕,未来图像和文字是不是可以随心所欲的转来转去?可感知可推理的强人工智能是不是不远了?(想想就好)
向着NLP和CV的统一前进
Reference
[1]Attention Is All You Need
[2]An Image is Worth 16*16 Words: Transformers for Image Recognition at Scale
[3]End-to-End Object Detection with Transformers
[4]Deformable DETR: Deformable Transformers for End-to-End Object Detection
推荐阅读
ACCV 2020国际细粒度网络图像识别竞赛正式开赛!
