
深度学习其实并不难:卷积神经网络的简单介绍
点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
转自AI中国
关于CNN,
第1部分:卷积神经网络的介绍
CNN是什么?:它们如何工作,以及如何在Python中从头开始构建一个CNN。
在过去的几年里,卷积神经网络(CNN)引起了人们的广泛关注,尤其是因为它彻底的改变了计算机视觉领域。在这篇文章中,我们将以神经网络的基本背景知识为基础,探索什么是CNN,了解它们是如何工作的,并在Python中从头开始构建一个真正的CNN(仅使用numpy)。
准备好了吗?让我们开看看吧
1. 动机
CNN的经典用例是执行图像分类,例如查看宠物的图像并判断它是猫还是狗。这看起来是一个简单的任务,那为什么不使用一个普通的神经网络呢?
好问题!
原因1:图像很大
现在用于计算机视觉问题的图像通常是224x224或更大的。想象一下,构建一个神经网络来处理224x224彩色图像:包括图像中的3个彩色通道(RGB),得到224×224×3 = 150,528个输入特征!在这样的网络中,一个典型的隐含层可能有1024个节点,因此我们必须为第一层单独训练150,528 x 1024 = 1.5 +亿个权重。我们的网络将是巨大的,几乎不可能训练的。
我们也不需要那么多权重。图像的好处是,我们知道像素在相邻的上下文中最有用。图像中的物体是由小的局部特征组成的,比如眼睛的圆形虹膜或一张纸的方角。从第一个隐藏层中的每个节点来说,查看每个像素看起来不是很浪费吗?
原因二:立场可以改变
如果你训练一个网络来检测狗,你希望它能够检测狗,不管它出现在图像的什么地方。想象一下,训练一个网络,它能很好地处理特定的狗的图像,然后为它提供相同图像的略微移位的版本。狗不会激活相同的神经元,因此网络会有完全不同的反应!
我们很快就会看到CNN如何帮助我们解决这些问题。
2.数据集
在这篇文章中,我们将解决计算机视觉的"Hello,World!":MNIST手写数字分类问题。这很简单:给定图像,将其分类为数字。

MNIST数据集中的每个图像都是28x28,并包含了一个以中心为中心的灰度数字。
说实话,一个正常的神经网络实际上可以很好地解决这个问题。你可以将每个图像视为一个28x28 = 784维的向量,将其提供给一个784-dim的输入层,堆叠几个隐藏层,最后的输出层包含10个节点,每个数字对应一个节点。
因为MNIST数据集包含小图像居中,所以我们不会遇到上述的大小或移动问题。然而,在这篇文章的整个过程中请记住,大多数现实世界中的图像分类问题并没有这么简单。
那么,现在你已经有足够的积累了。让我们正式进入CNN的世界!
3.卷积
什么是卷积神经网络?
它们基本上只是使用卷积层的神经网络,即基于卷积数学运算的Conv层。Conv图层由一组滤镜组成,你可以将其看作是数字的二维矩阵。这里有一个例子3x3过滤器:

我们可以使用一个输入图像和一个过滤器通过将过滤器与输入图像进行卷积来生成一个输出图像。这包括
将过滤器覆盖在图像的某个位置上。
在过滤器中的值与其在图像中的对应值之间执行元素级乘法。
总结所有元素产品。这个和是输出图像中目标像素的输出值。
对所有位置重复。
旁注:我们(以及许多CNN实现)实际上在技术上使用的是互相关而不是卷积,但它们做的几乎是一样的。我不会在这篇文章中详细讨论它们之间的区别,因为这并不重要。
这四步描述有点抽象,我们来做个例子。看下这个微小的4x4灰度图像和这个3x3滤镜:

图像中的数字表示像素强度,其中0为黑色,255为白色。我们将卷积输入图像和过滤器产生一个2x2输出图像:

首先,让我们将滤镜叠加在图片的左上角:
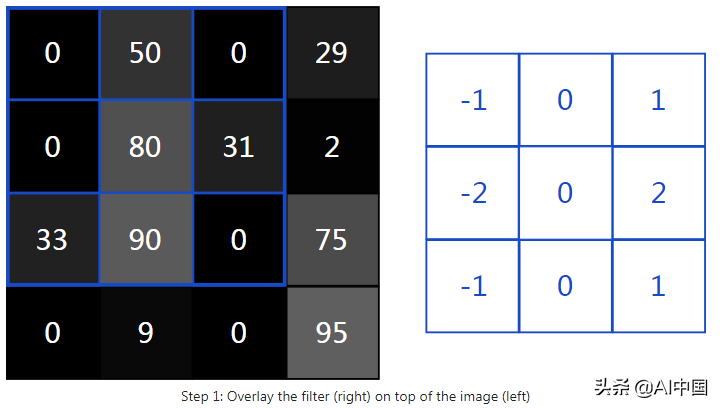
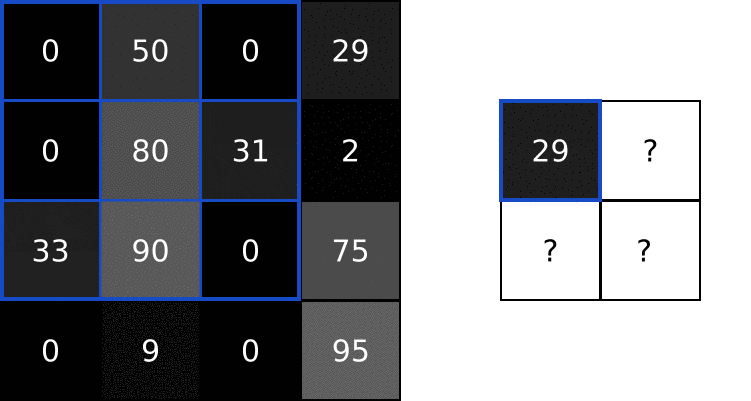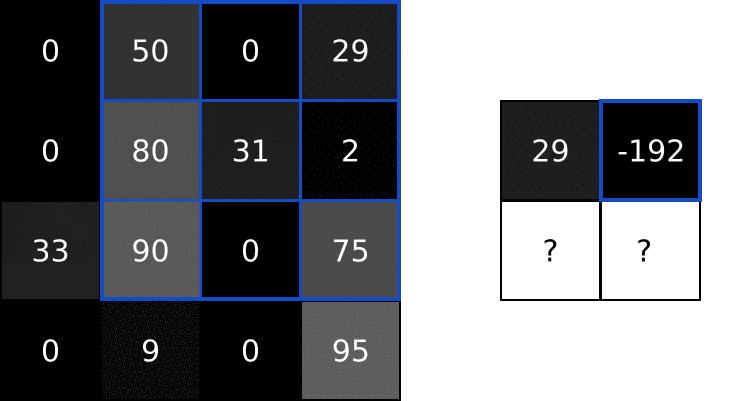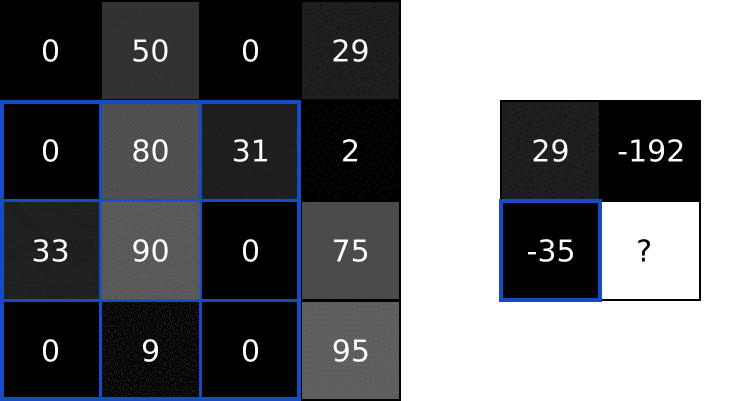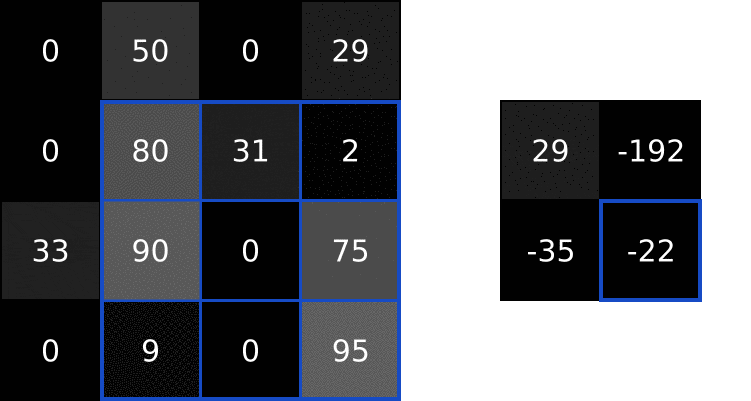
接下来,我们在重叠图像值和过滤器值之间执行逐元素乘法。以下是结果,从左上角开始向右,然后向下:

接下来,我们总结所有的结果。这是很容易:

最后,我们将结果放入输出图像的目标像素中。由于我们的过滤器覆盖在输入图像的左上角,我们的目标像素是输出图像的左上角像素:

我们做同样的事情来生成输出图像的其余部分:
3.1这有什么用?
让我们缩小一下,在更高的层次上看这个。将图像与过滤器进行卷积会做什么?我们可以从我们一直使用的例子3x3过滤器开始,它通常被称为垂直Sobel过滤器:
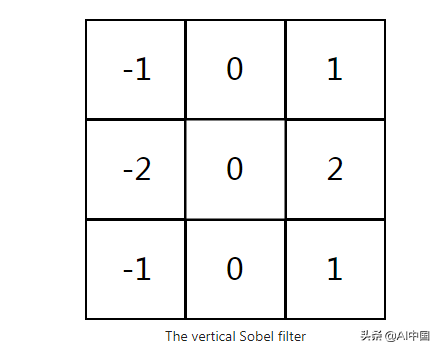
下面是一个垂直Sobel过滤器的例子:
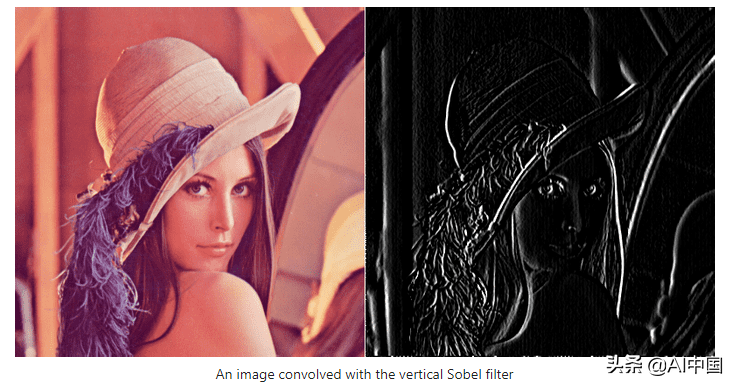
同样,还有一个水平Sobel过滤器:


看发生了什么?Sobel过滤器是一种边缘检测器。垂直Sobel过滤器检测垂直边缘,水平Sobel过滤器检测水平边缘。输出图像现在很容易解释:输出图像中的亮像素(高值像素)表示在原始图像中有一个强边缘。
你能看出为什么边缘检测图像可能比原始图像更有用吗?回想一下我们的MNIST手写数字分类问题。在MNIST上训练的CNN可以寻找数字1,例如,通过使用边缘检测过滤器并检查图像中心附近的两个突出的垂直边缘。通常,卷积有助于我们查找特定的本地化图像特征(如边缘),我们可以在以后的网络中使用。
3.2填充
还记得以前将4x4输入图像与3x3滤波器卷积得到2x2输出图像吗?通常,我们希望输出图像与输入图像的大小相同。为此,我们在图像周围添加零,这样我们就可以在更多的地方覆盖过滤器。一个3x3的过滤器需要1像素的填充:

这称为"相同"填充,因为输入和输出具有相同的尺寸。不使用任何填充,这是我们一直在做的,并将继续为这篇文章做,有时被称为"有效"填充。
3.3 Conv层(Conv Layers)
现在我们知道了图像卷积是如何工作的以及它为什么有用,让我们看看它在CNN中的实际应用。如前所述,CNN包括conv层,它使用一组过滤器将输入图像转换为输出图像。conv层的主要参数是它拥有的过滤器的数量。
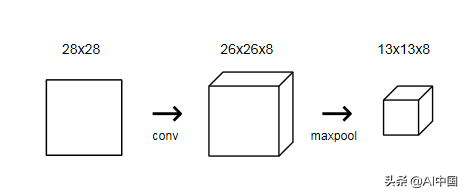
对于MNIST CNN,我们将使用一个带有8个过滤器的小conv层作为网络的初始层。这意味着它将把28x28的输入图像转换成26x26x8的容量:
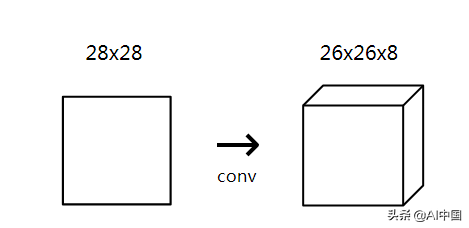
提醒:输出是26x26x8,而不是28x28x8,因为我们使用了有效的填充,这将输入的宽度和高度降低了2。
conv层中的4个过滤器每个都产生一个26x26的输出,因此它们叠加在一起构成一个26x26x8。所有这些都是因为3×3(过滤器大小)\ × 8(过滤器数量)= 72个权重!
3.4实施卷积
是时候把我们学到的东西写进代码里了!我们将实现conv层的前馈部分,它负责将过滤器与输入图像进行卷积以生成输出卷。为了简单起见,我们假设过滤器总是3x3(这并不是真的,5x5和7x7过滤器也很常见)。
让我们开始实现一个conv层类:

Conv3x3类只接受一个参数:过滤器的数量。在构造函数中,我们存储过滤器的数量,并使用NumPy的randn()方法初始化一个随机过滤器数组。
注意:如果初始值过大或过小,训练网络将无效。
接下来,实际的卷积:

iterate_regions()是一个辅助发生器的方法,收益率为我们所有有效3 x3的图像区域。这对于以后实现该类的向后部分非常有用。
上面突出显示了实际执行卷积的代码行。让我们来分解一下:
我们有im_region,一个包含相关图像区域的3x3数组。
我们有self.filters,一个3d数组。
我们做im_region * self.filters,它使用numpy的广播机制以元素方式乘以两个数组。结果是一个3d数组,其尺寸与self.filters相同。
我们np.sum()上一步的结果使用axis =(1,2),它产生一个长度为num_filters的1d数组,其中每个元素包含相应过滤器的卷积结果。
我们将结果分配给输出[i,j],其中包含输出中像素(i,j)的卷积结果。
对输出中的每个像素执行上面的序列,直到得到最终的输出卷为止!让我们测试一下我们的代码:

目前看起来不错。
注意:在Conv3x3实现中,为了简单起见,我们假设输入是一个2d numpy数组,因为MNIST图像就是这样存储的。这对我们有用,因为我们使用它作为我们网络的第一层,但大多数cnn有更多的Conv层。如果我们要构建一个更大的网络,需要多次使用Conv3x3,那么我们必须将输入设置为3d numpy数组。
4. 池化
图像中的相邻像素往往具有相似的值,因此conv层通常也会为输出中的相邻像素生成相似的值。因此,conv层输出中包含的大部分信息都是多余的。例如,如果我们使用边缘检测过滤器,并在某个位置找到一个强边缘,那么我们很可能也会在距离原始位置1像素的位置找到一个相对较强的边缘。然而,这些都是相同的边缘!我们没有发现任何新东西。
池化层解决了这个问题。他们所做的就是减少(通过猜测)在输入中汇总值的输入大小。池化层通常由一个简单的操作完成,比如max、min或average。下面是一个最大池层的例子,池的大小为2:
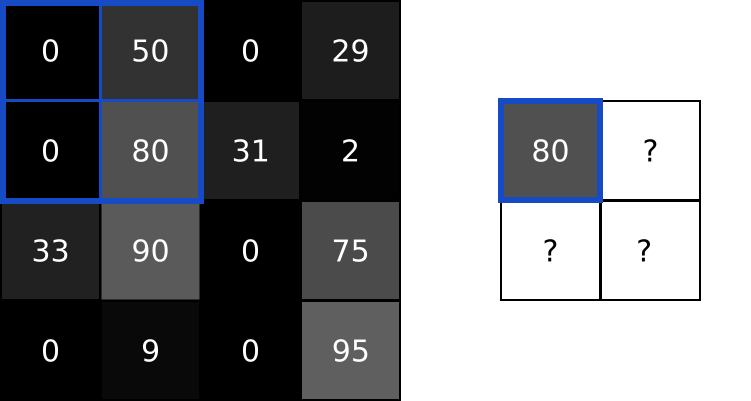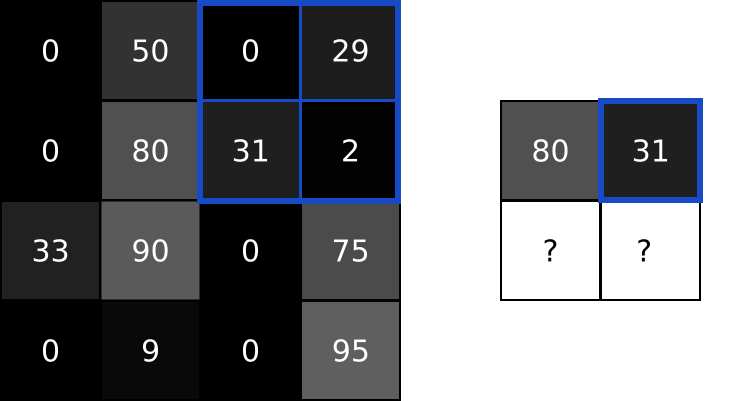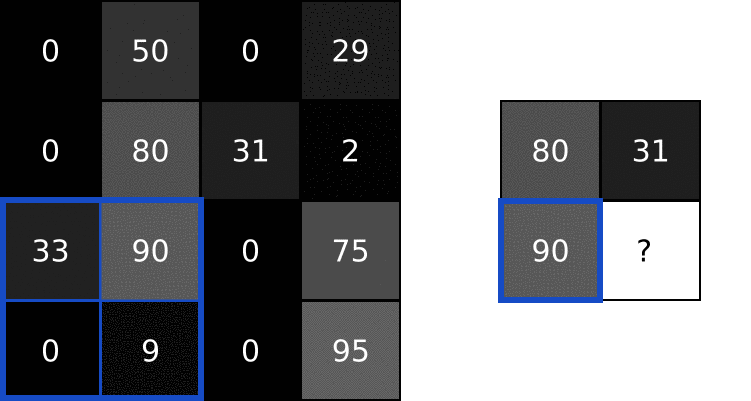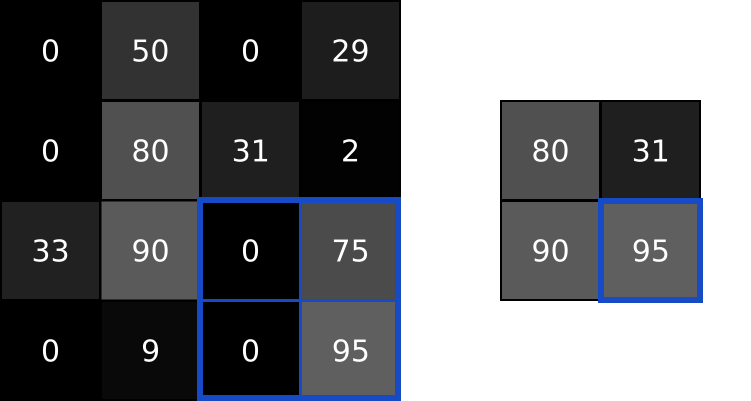
为了执行最大池化,我们在2x2块中输入了图像(因为池的大小= 2),并将最大值放入对应像素处的输出图像中。就是这样!
它将输入的宽度和高度除以它的大小。对于MNIST CNN,我们将在初始conv层之后放置一个池大小为2的最大池化层。池化层将26x26x8输入转换为13x13x8输出:
4.1 Implementing Pooling(实施池)
我们将实现一个MaxPool2类与我们的conv类相同的方法从上一节:

这个类的工作原理类似于我们之前实现的Conv3x3类。关键行再次突出显示:要从给定的图像区域找到最大值,我们使用np.amax(), numpy的array max方法。我们设置axis=(0,1),因为我们只想最大化前两个维度(高度和宽度),而不是第三个维度(num_filters)。
我们来试试吧!
我们的MNIST CNN开始走到一起了!
5. Softmax
为了完成我们的CNN,我们需要赋予它实际预测的能力。我们将通过使用一个多类分类问题的标准最终层来实现这一点:Softmax层,这是一个使用Softmax激活函数的标准全连接(密集)层。
提醒:全连接层的每个节点都连接到上一层的每个输出。如果你需要复习的话,我们在介绍神经网络时使用了全连接层图层。
Softmax将任意实值转换为概率。它背后的数学原理很简单:给定一些数字,
取e(数学常数)的每一次方。
把所有的指数(eee的幂)加起来。这个结果是分母。
用每个数的指数作为它的分子。
概率= Numerator/Denominator
写得更妙的是,Softmax对nnn数字执行以下转换X1...Xn:
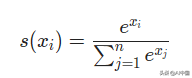
Softmax变换的输出总是在[0,1][0,1][0,1][0,1]范围内,并且加起来等于1,由此转换成概率。
下面是一个使用数字-1、0、3和5的简单例子:
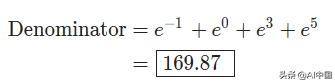

5.1使用方法
我们将使用一个包含10个节点的softmax层,每个节点代表一个数字,作为CNN的最后一层。层中的每个节点都将连接到每个输入层。应用softmax变换后,以概率最高的节点表示的数字为CNN的输出!

5.2交叉熵损失函数
你可能会想,为什么要把输出转化为概率呢?最高的产值不总是有最高的概率吗?如果你这么做了,你绝对是对的。我们实际上不需要使用softmax来预测一个数字,而我们只需要从网络中选择输出最高的数字即可!
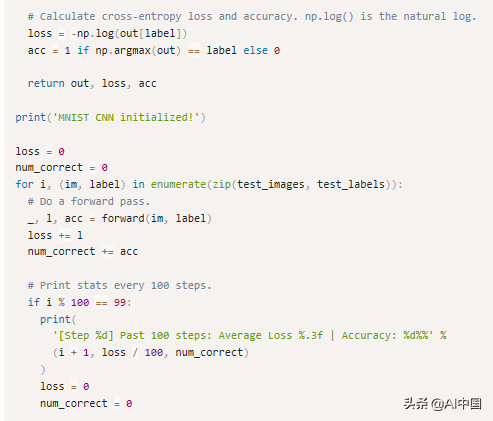
softmax真正做的是帮助我们量化我们对预测的确定程度,这在训练和评估CNN时非常有用。更具体地说,使用softmax允许我们使用交叉熵损失函数,它考虑到我们对每个预测的确定程度。下面是我们计算交叉熵损失函数的方法:

c在哪里是正确的类(在我们的例子中是正确的数字),Pc类c的预测概率,并在natural log中。一如既往的,损失越少越好。例如,在最好的情况下,我们会

在更现实的情况下,我们可能会有
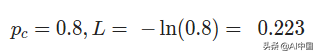
我们将在稍后的文章中再次看到交叉熵损失函数,所以请记住这一点!
5.3实施Softmax
你现在知道这个练习,让我们实现一个Softmax图层类
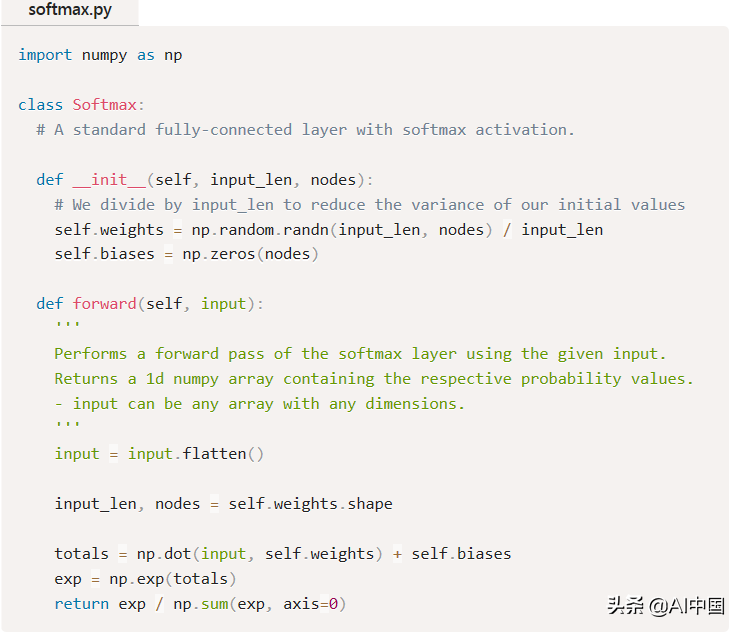
这里没有什么太复杂的。几个亮点:
我们将输入压平(),使其更容易处理,因为我们不再需要它的形状。
np.dot()将输入和self相乘。按元素加权,然后对结果求和。
np.exp()计算用于Softmax的指数。
我们现在已经完成了CNN的整个转发!放在一起:

运行cnn.py给我们输出类似于:
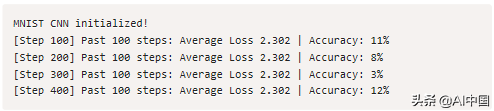
这是有道理的:使用随机权重初始化,你会期望CNN只会像随机猜测一样好。随机猜测的话,10%的准确率(因为有10类)和一个叉的损失−ln(0.1) = 2.302 {- \ ln (0.1)} = 2.302−ln(0.1) = 2.302,这是我们得到的!
想自己尝试或修改这段代码吗?在浏览器中运行CNN。它也可以在Github上使用。
6. 结论
以上就是对CNN的介绍!在这篇文章中,我们
为什么CNN在某些问题上可能更有用,比如图像分类。
介绍MNIST手写数字数据集。
了解Conv层,它将过滤器与图像进行卷积以产生更有用的输出。
谈到了池化层,它可以帮助删除除最有用的功能之外的所有功能。
实现了一个Softmax层,因此我们可以使用交叉熵损失。
还有很多东西我们还没有讲到,比如如何训练CNN。本系列的第2部分将对CNN进行深入的一个训练,包括推导梯度和实施反向传播。
—版权声明—
仅用于学术分享,版权属于原作者。
若有侵权,请联系微信号:yiyang-sy 删除或修改!