
突发流量洪峰应对之道——疫情期间京东口罩预约抢购系统优化
共 6330字,需浏览 13分钟
·
2021-01-27 12:29


突如其来的疫情,让口罩成为全国人民争相抢购的必需品。在疫情最严重的2020年2月份,京东组织力量采购了一批口罩,面向全国人民发售。由于库存十分有限,运营采用了预约+秒杀的营销模式,也就是用户先预约,到了指定时间才能通过秒杀系统抢购。
由于大家对口罩的需求太过强烈,2月14日活动一上线就遭到用户热捧,在社交媒体上的热度急速上升,甚至都上了微博热搜,造成了一定的社会影响。而在京东内部也升级为红色飓风事件,客服、公关等部门也都介入,为此次活动保驾护航。
强烈的用户需求带来了海量的用户流量,对相关系统形成了一定的挑战。可能有人会问,京东经历了这么多次618、11.11大促的考验,交易系统经历千锤百炼早就坚若磐石了,这次怎么还会存在挑战呢?这有两方面的原因:
1. 用户行为与大促不同。618、11.11大促虽然流量大,但流量分布在几百万sku上;而这次口罩抢购则不同,所有用户都只有一个目标,那就是抢口罩,所有流量都集中在特定sku上,形成了超级爆品。所有人都在浏览同一个sku,然后进行预约、加购物车、最后提交订单抢购;而整个交易流程链条非常长,上下游几十个系统,很容易出现薄弱环节造成事故。
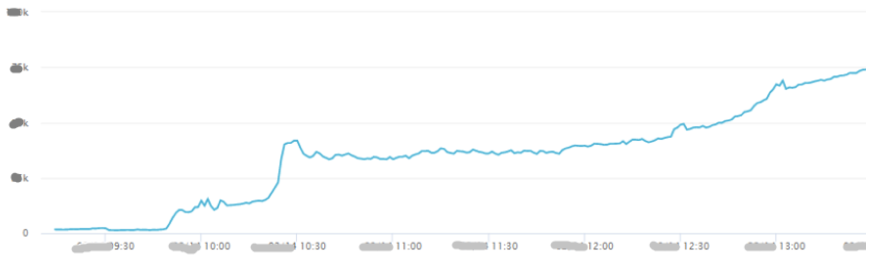
2. 用户流量远超大促。由于用户行为发生变化,导致部分接口TPS远超历史极限值。以预约系统为例:
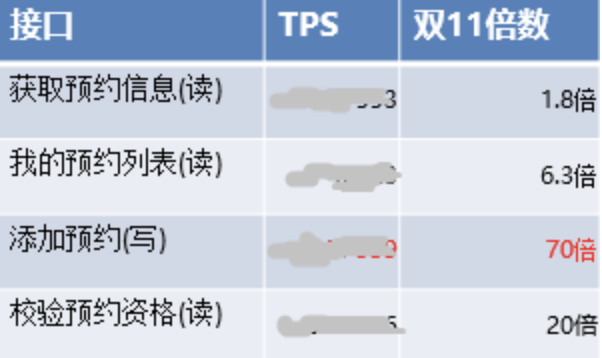
我们可以看到,单个sku读写TPS均远超历史峰值,而写TPS则是历史峰值的70倍。
由于这两点原因,交易系统虽然总体平稳,但仍存在着不小的挑战。
从2020年2月份到4月份期间,我们通过京东主站、京东健康、京喜等渠道共进行了上千场口罩预约活动,超过1亿人次进行了预约。为了适应新的用户场景、保障交易系统的平稳,我们紧急对相关系统进行了改造,期间遇到了各种突发状况和技术难点,所幸的是我们迅速对系统进行了改造,增强了应对突发流量洪峰的能力,保障了口罩预约的顺利进行。在这里以预约系统为例向大家做一下分享。
先简单介绍一下预约系统。预约活动分为预约期和抢购期,用户在预约期进行预约,抢购期开始后才能购买。

在预约期,用户打开商品详情页,就会调用预约系统“获取预约信息”接口获取预约活动详情,比如预约开始时间、抢购开始时间、预约人数等,展示在商品详情页:

用户点击“立即预约”按钮,就会调用预约系统的“添加预约资格”接口,记录用户的预约信息。
而到了抢购期,用户在结算页点击“提交订单”时,会调用预约系统的“校验预约资格”接口,查看用户是否进行了预约,如果没有预约就返回错误不让用户下单。
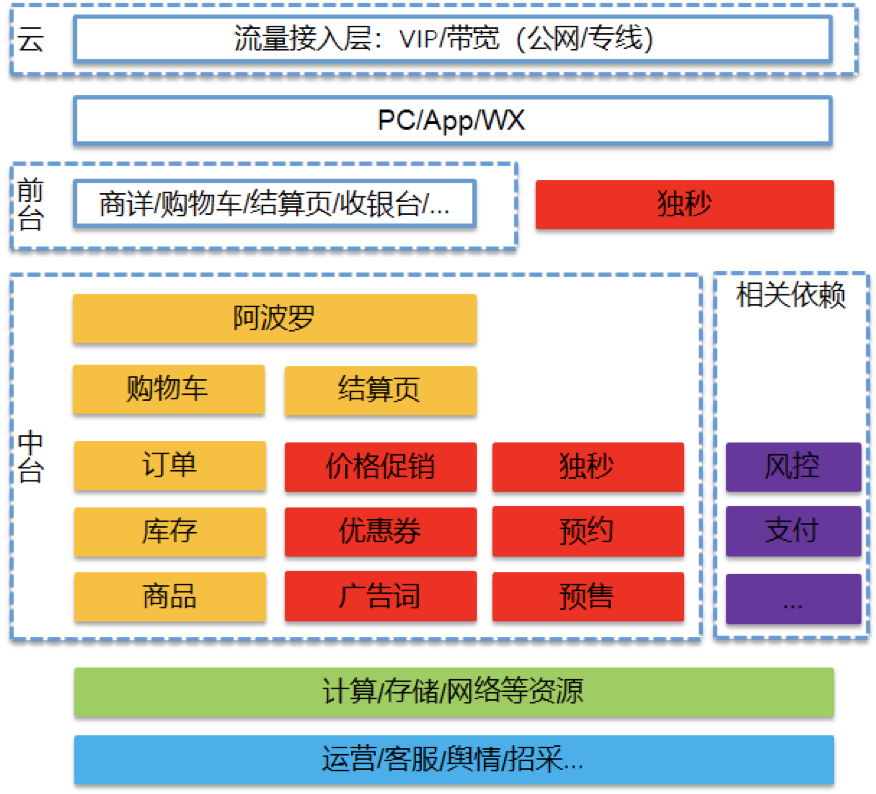
我们可以看到预约业务相对简单,只有一个写操作(添加预约资格)+N个读操作,其上下游主要有商详、购物车、结算页等。
预约系统在整个交易系统中的位置:
最后从技术角度介绍一下预约系统整体架构。
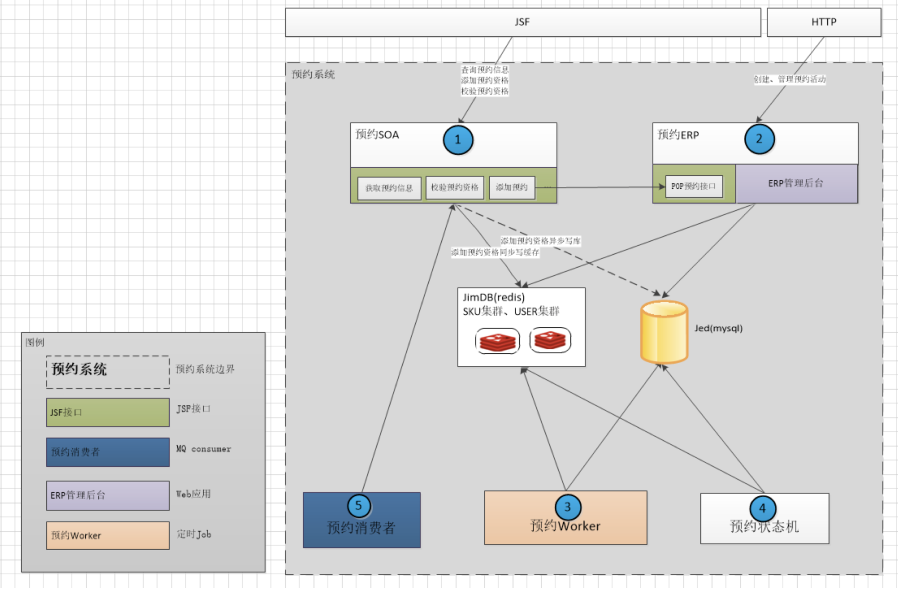
其中“预约SOA”模块提供接口给下游系统,承接所有的前端流量,在本次活动中被重点考验。主要接口有:获取预约信息、添加预约资格、校验预约资格。存储用到了缓存jimdb(redis集群)和mysql,redis存储预约活动信息和用户的预约信息,供预约SOA使用;mysql主要用于数据的持久化落地,并不直接提供服务。我们可以看到,redis作为存储层,其表现将直接决定预约系统的性能。
由于运营人员没有预料到会有如此之大的流量,未提前向产品和研发报备,只是在活动开始前通知有一个口罩预约活动,未能引起大家的重视,导致没有提前进行备战值班。
预约活动开始后,研发侧进行例行检查时,发现口罩预约活动流量异常:每分钟有数万人进行预约,而且速度非常稳定甚至有加速的趋势(随着消息的传播,越来越多的用户进行了预约)。
这个数字意味着什么呢?每小时有几百万用户预约了口罩,此时距活动结束还有数小时,如果不采取措施的话,将会有数千万人来预约这个口罩!这意味着单个sku的流量将接近11.11所有预约sku流量的总和!
这里暴露出了存在的第一个问题:缺乏对爆品sku的有效监控。虽然我们已经对主要接口的调用量设置了监控告警,但由于此次活动用户行为与大促不同,并未触发系统告警。研发侧虽然通过例行检查及时发现了问题,但仍存在较大风险,后面我们将会对此进行改进。
由于事先未演练过如此极端的场景,如此巨大的流量将会对预约系统带来怎样的挑战,大家心里都没有底;对上下游(商详、购物车、结算页)会造成怎样的冲击,更是茫然。此时我们已经看到,流量洪峰即将到来,将对整个交易系统带来巨大的冲击。而要想减小冲击,唯一的办法就是:提前终止预约活动,将流量挡在交易系统之前。
发现问题的严重性后,研发侧立即将问题升级上报,迅速联系产品、上下游系统和业务方,提出预约系统的建议:立即结束预约活动。经过紧急沟通后,业务方考虑到口罩库存有限,最终同意了我们的建议,但要求已预约的所有用户能正常参与抢购。
在按下“关闭预约”按钮的那一刻,看着新增预约人数断崖式下滑,所有人都松了一口气。但大家来不及放松,因为此时整个交易系统面临着一系列棘手问题:
1. 预约系统:上一场预约活动已经提前结束,已经预约的数百万用户必须让他们正常抢购口罩。如果到了时间不能购买,必将引起这数百万用户的集中投诉,将会是P0级别的严重事故。
2. 购物车:预约活动有个选项叫“自动加购物车”,用户预约成功后会自动将sku添加到购物车,方便下单购买。运营人员没有预计到会有如此多的用户进行预约,在创建预约活动时配置了该选项,导致这数百万用户都将口罩添加到了购物车。在抢购开始前,大量用户将从购物车入口提交订单进行抢购,对购物车系统将会造成非常大的冲击。
3. 商品详情:除了从购物车入口进行抢购外,还有大量用户直接从商详页提交订单,如此大的流量访问同一个sku将会造成严重的热点key问题,在用户端的表现就是商详页面卡、白屏等,严重影响用户体验。
4. 结算页:有两套下单系统,主流程(日常下单系统)和独立秒杀系统(应对突发流量的抢购系统)。运营人员没有为口罩sku创建独立秒杀活动,用户下单时将会走主流程提交订单,将会严重影响主流程的性能。
此时距抢购开始时间只有几小时,研发侧必须在抢购开始前解决以上问题。
考虑到时间的紧迫性,研发侧最终采取了如下措施应对紧急情况,确保用户能正常抢购:
1. 预约系统:启用了应急方案,同一个口罩sku新建一个只有抢购期预约活动,然后将上一场预约活动的数百万用户导入进来(相当于替这数百万用户预约了新建的这一场预约活动,用户侧无感知),到了抢购时间这些用户就能正常参与抢购了。这样既能让这批用户参与抢购,又不让新用户继续预约,达到了保护交易系统的目的。

但在导入用户时,我们遇到了第二个问题:查询Mysql用户表遍历数百万用户,Mysql分页查询速度越来越慢,导致用户导入速度越来越慢。这是Mysql经常遇到的经典问题,虽然我们已经做了常规的SQL优化,但查询速度仍然达不到要求。我们查询SQL如下:
SELECT ...FROM MEMBER_TABLE ainner join (SELECT id as id1FROM MEMBER_TABLEWHERE ...LIMIT #{page.beginIndex},#{page.step}) b ON a.id=b.id1
所幸的是,虽然查询速度较慢,但仍在抢购开始前将所有预约用户成功导入到下一场预约活动了,让他们可以正常参与抢购。关于这个问题的最终解决方案,我们将在后面做介绍。
2. 购物车:进行紧急处理避免了问题。
3. 商品详情:服务降级+缓存扩容解决热点key问题。
4. 结算页:为口罩sku创建独立秒杀活动,用户提交订单时走独立秒杀系统,保护了下单主流程。
经过各系统的一系列应急处理,我们终于在抢购开始前做好了准备工作,在抢购开始的那一刻看着蜂拥而来的用户请求,所有人悬着的心终于暂时放了下来。
虽然第一天的预约活动顺利进行了,但暴露出了第三个问题:预约系统缺乏熔断机制。在之前多年的营销活动中,都没有出现过上百万人预约同一个sku的场景,因此并未对预约人数设置上限。但是在当前场景下,我们急需限制预约人数上限,因此需要增加熔断机制。按照正常的方案沟通、开发、测试、上线流程,至少需要一个礼拜才能完成上述功能,而此时距下场预约活动开始,只剩不到12个小时的时间。
所谓的熔断机制,就是在用户点击“立即预约”时,检查预约人数是否达到指定上限,如果到了就立即结束预约期不让新用户进行预约,预约活动进入“等待抢购”状态,已预约的用户等抢购开始后可以正常参与抢购。也就是图4中,将预约结束时间提前。
简化版流程图如下:
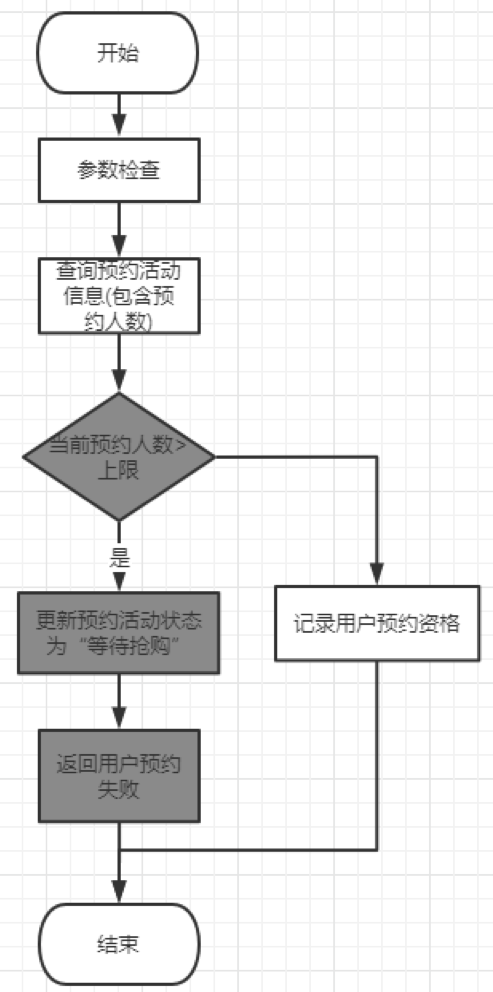
方案看起来相对简单,但实际开发时有诸多细节需要考虑,这里就不一一讲解了。
熔断机制上线后,每场活动的预约人数基本都控制在固定数字,爆品流量得到了控制,有效的保护了整个交易系统。但又引发了意料之外的第四个问题:热key问题。
意想不到的是,熔断机制上线后用户的行为发生了很大的变化:所有用户都在预约期开始的第一秒进行预约,因为所有用户都知道预约人数达到上限后,就不能再预约了。这无形之中起到了流量聚集的作用,本来用户点“立即预约”的流量分布比较均匀,现在都抢在第一秒点击,于是就造成预约系统“添加预约资格”接口TPS飙升,达到了历史峰值的70倍(某种意义上来说,预约系统已经变成了秒杀系统,用户点击“立即预约”实际就是在进行秒杀抢购)。
而“添加预约资格”接口需要多次写redis缓存,如此高的TPS带来了严重的问题:热key问题。
预约系统经历多年618、11.11大促的考验,常规场景下的热key问题早就解决了。但是很不幸,新场景下还是出现了新的热key问题。下面详细讲解为啥会出现热key问题,以及我们的解决方案。
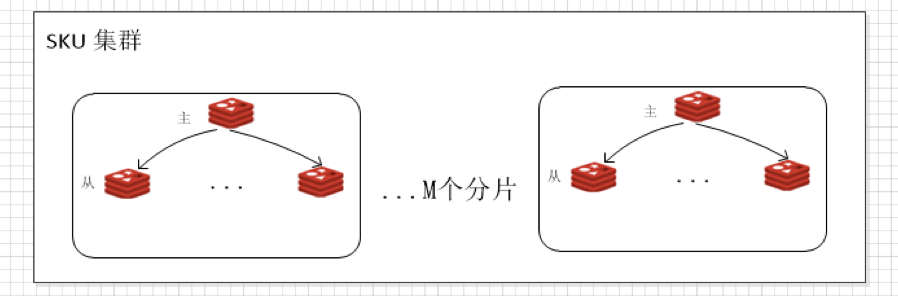
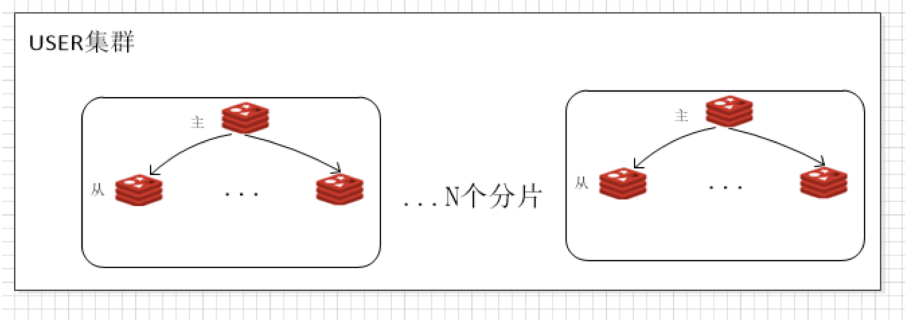
预约系统使用了2个redis集群(实际部署情况更复杂,这里简化处理了):
1. SKU集群:存放预约活动信息,M个分片,1主多从,写操作主实例,读操作从实例。
2. USER集群:存放用户的预约记录,N个分片,1主多从,写操作主实例,读操作从实例。
“添加预约资格”接口流程图如下:
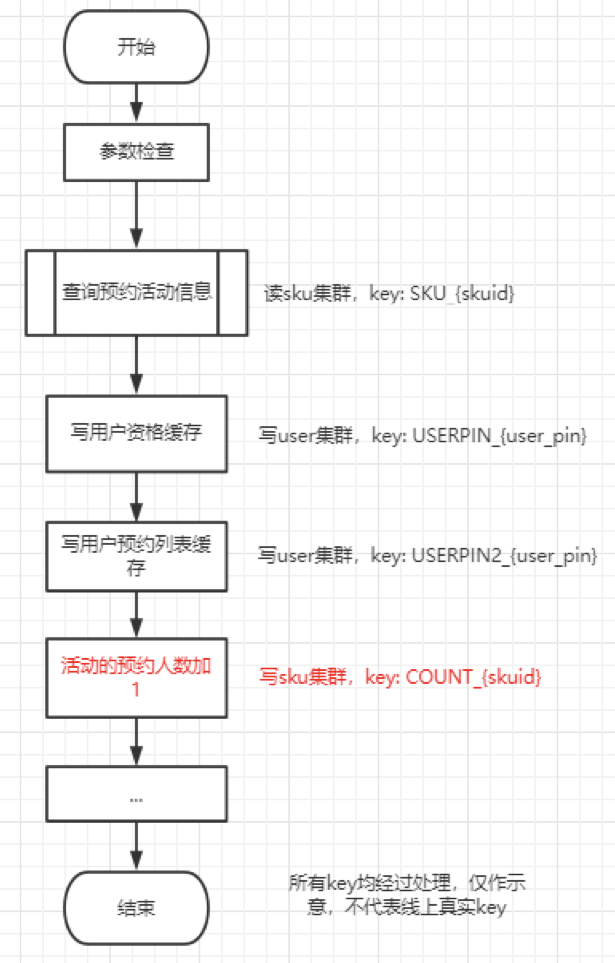
从上面的流程图可以看到,用户在“立即预约”时,将要对USER集群进行2次写操作,对SKU集群进行1次读操作+1次写操作。下面我们一一分析:
1. 查询预约活动信息时读SKU集群,key为SKU_{skuid}。在爆品sku的情况下可能形成热点key,但实际上并未发生,因为进行了如下优化:
1. 本地JVM缓存。因为SKU活动信息很少发生变化,于是使用了guava进行了本次缓存,只有在guava缓存失效的情况下才会读取redis集群。根据线上监控数据,爆品活动的缓存命中率在99%以上,因此极大的降低了读redis集群的OPS。
2. SKU集群1主多从,读操作流量由个从库平均分摊,也能应付很高的TPS。
2. 写用户资格缓存时写USER集群,key为USERPIN{userpin},用户维度的key分布在多个redis分片上,理论上能承受很高的OPS,也足以应付本场景。
3. 写用户预约列表缓存,同上。
4. 更新预约活动的预约人数,写SKU集群,key为COUNT_{skuid}。本操作主要是更新预约人数计数器,就是用户在商品详情页面看到当前有多少人预约了这个sku。该计数器是实时更新的,每一个新用户预约成功,该计数器就会+1;假设添加预约资格TPS为X万,那么写redis的OPS就为X万,所有写操作都打到一个分片的主库上,于是就形成了热点key。
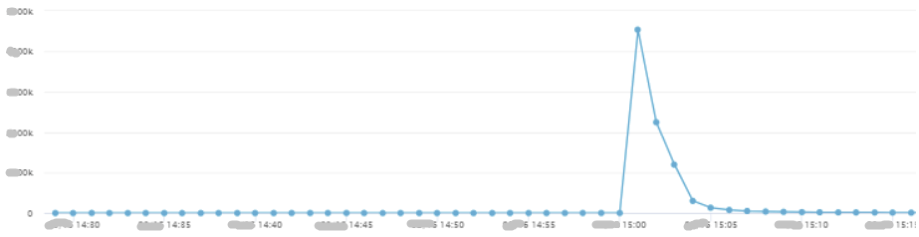
热点key直接将USER集群一个主库的CPU打到100%,造成大量写操作超时,进而导致“添加预约资格”接口TP飙升,可用率下降。反映在用户端就是,大量用户点击“立即预约”时,会收到预约失败的提示,严重影响用户体验。
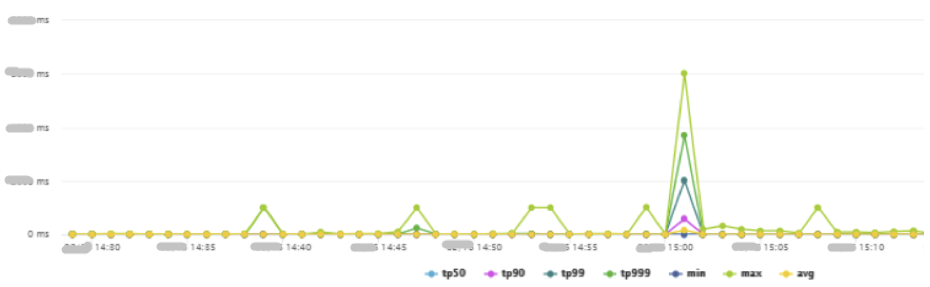
图14:热key问题发生时,添加预约资格接口TP,分钟级
找到了热key发生的原因,解决方案就在眼前了:减少写USER集群的次数,把OPS降下来问题自然就迎刃而解了。
我们采取的方案是:不再实时更新预约人数,而是在JVM中先缓存预约人数,达到一定阈值后再批量更新预约人数计数器。原来是每次加1,改为每次加N,自然就把写操作的OPS降下来了。
本方案通过牺牲预约人数计数器的精确性,来保证接口的整体性能,得到了业务方的认可。具体流程图如下:
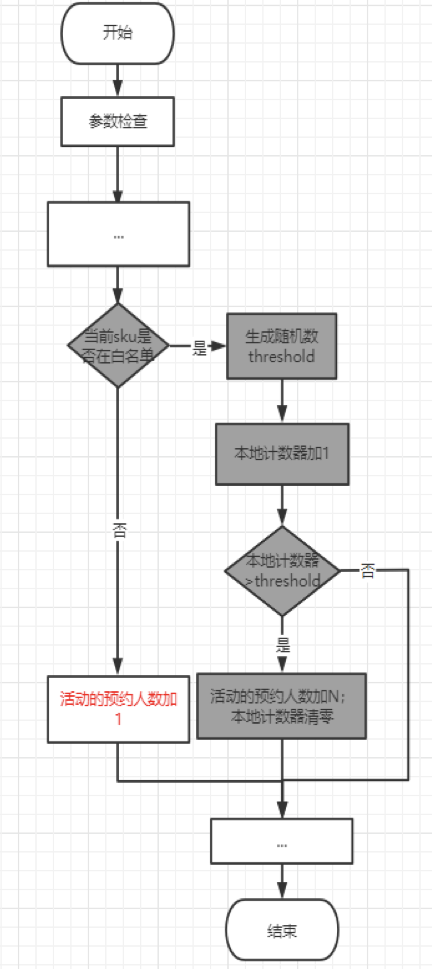
经过本次优化,终于解决了热点key问题,USER集群OPS降低到原来的2%, cpu使用率从100%降低了13%,接口TP999提升了500倍。
然后再启用JSF限流,限制“添加预约资格”接口的TPS,有效的解决了此问题。
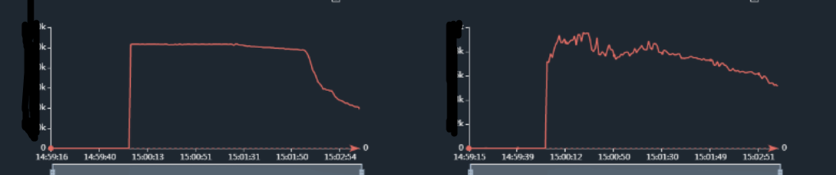
最后,简单总结一下在此期间遇到的典型问题以及解决方案:
1. 爆品sku缺乏监控:预约系统新增了监控机制,定期扫描每个活动的预约人数,发现爆品sku通过邮件发送上下游系统,提醒他们做好值班保障;同时还通过电话语音告警,通知预约系统值班人员。
2. mysql查询慢:从mysql迁移到弹性数据库JED,同时对部分场景进行改造:预约人数较多的活动,查询redis集群获取所有用户pin,不再从数据库中查询。
3. 预约人数过多:熔断机制。
4. 热key问题:批量更新预约人数计数器,减少写redis集群的OPS。
5. 公平性问题:由于口罩库存有限,大量预约用户抢购失败,严重影响用户体验。针对此类稀缺爆品,我们开发了预约抽签模式:用户先预约,然后系统进行抽签摇号,只有中签用户才能购买,这里就先不介绍了。
通过如上一系列紧急改造,预约系统具备了应对突发流量洪峰的能力,达到了平稳运行、有效保护交易系统的目的。不仅顺利进行了上千场口罩预约抢购活动,为部分用户送去了他们急需的口罩;这些改造还直接应用在了2020年下半年的茅台预约抢购、京东PLUS盛典等重大活动中,有力的支撑了业务发展。
作为的亲历此次备战的一线研发人员,能用实际行动在疫情期间为全国人民做出一点微小的贡献,我们内心感到无比的高兴和光荣。
此次口罩预约抢购活动,预约中台保障人员:架构师王晓烽、佘志东、王曦晨、产品童春斐、工程师饶正锋
后台回复 学习资料 领取学习视频
如有收获,点个在看,诚挚感谢