
elasticsearch集群扩容和容灾


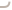
点击上方蓝色“迈莫coding”,选择“设为星标”
一、集群健康
Elasticsearch 的集群监控信息中包含了许多的统计数据,其中最为重要的一项就是集群健康,它在 status 字段中展示为 green 、 yellow 或者 red。
在kibana中执行:GET /_cat/health?v
1 epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent2 1568794410 08:13:30 my-application yellow 1 1 47 47 0 0 40 0 - 54.0%
其中我们可以看到当前我本地的集群健康状态是yellow ,但这里问题来了,集群的健康状况是如何进行判断的呢?
green(很健康)所有的主分片和副本分片都正常运行。yellow(亚健康)所有的主分片都正常运行,但不是所有的副本分片都正常运行。red(不健康)有主分片没能正常运行。
注意:
我本地只配置了一个单节点的elasticsearch,因为primary shard和replica shard是不能分配到一个节点上的所以,在我本地的elasticsearch中是不存在replica shard的,所以健康状况为yellow。
二、shard和replica
为了将数据添加到Elasticsearch,我们需要索引(index)——一个存储关联数据的地方。实际 上,索引只是一个用来指向一个或多个分片(shards)的“逻辑命名空间(logical namespace)”. 一个分片(shard)是一个最小级别“工作单元(worker unit)”,它只是保存了索引中所有数据的一 部分。
道分片就是一个Lucene实例,并且它本身就是一个完整的搜索引擎。我们的文档存储在分片中,并且在分片中被索引,但是我们的应用程序不会直接与它们通信,取而代之的是,直接与索引通信。分片是Elasticsearch在集群中分发数据的关键。把分片想象成数据的容器。文档存储在分片中,然后分片分配到你集群中的节点上。当你的集群扩容或缩小,Elasticsearch将会自动在你的节点间迁移分片,以使集群保持平衡。分片可以是主分片(primary shard)或者是复制分片(replica shard)。
你索引中的每个文档属于一个单独的主分片,所以主分片的数量决定了索引最多能存储多少数据。理论上主分片能存储的数据大小是没有限制的,限制取决于你实际的使用情况。分片的最大容量完全取决于你的使用状况:硬件存储的大小、文档的大小和复杂度、如何索引 和查询你的文档,以及你期望的响应时间。
复制分片只是主分片的一个副本,它可以防止硬件故障导致的数据丢失,同时可以提供读请 求,比如搜索或者从别的shard取回文档。当索引创建完成的时候,主分片的数量就固定了,但是复制分片的数量可以随时调整。让我们在集群中唯一一个空节点上创建一个叫做 blogs 的索引。默认情况下,一个索引被分配5个主分片,一个主分片默认只有一个复制分片。
重点:
shard分为两种:1,primary shard --- 主分片2,replica shard --- 复制分片(或者称为备份分片或者副本分片)
需要注意的是,在业界有一个约定俗称的东西,单说一个单词shard一般指的是primary shard,而单说一个单词replica就是指的replica shard。
另外一个需要注意的是replica shard是相对于索引而言的,如果说当前index有一个复制分片,那么相对于主分片来说就是每一个主分片都有一个复制分片,即如果有5个主分片就有5个复制分片,并且主分片和复制分片之间是一一对应的关系。
很重要的一点:primary shard不能和replica shard在同一个节点上。重要的事情说三遍:
primary shard不能和replica shard在同一个节点上
primary shard不能和replica shard在同一个节点上
primary shard不能和replica shard在同一个节点上
所以es最小的高可用配置为两台服务器。
三、master节点、协调节点和节点对等特性
elasticsearch同大多数的分布式架构,也会进行主节点的选举,elasticsearch选举出来的主节点主要承担一下工作:
1 集群层面的设置2 集群内的节点维护3 集群内的索引、映射(mapping)、分词器的维护4 集群内的分片维护
不同于hadoop、mysql等的主节点,elasticsearch的master将不会成为整个集群环境的流量入口,即其并不独自承担文档级别的变更和搜索(curd),也就意味着当流量暴增,主节点的性能将不会成为整个集群环境的性能瓶颈。这就是elasticsearch的节点对等特性。
节点对等:
所谓的节点对等就是在集群中每个节点扮演的角色都是平等的,也就意味着每个节点都能成为集群的流量入口,当请求进入到某个节点,该节点就会暂时充当协调节点的角色,对请求进行路由和处理。这是一个区别于其他分布式中间件的很重要的特性。节点对等的特性让elasticsearch具备了负载均衡的特性。在后面对document的写入和搜索会详细介绍该牛叉的特性。
协调节点:
通过上面的分析,我们可以得出一个结论,协调节点其实就是请求命中的那个节点。该节点将承担当前请求的路由工作。
四、扩容
一般的扩容模式分为两种,一种是水平扩容,一种是垂直扩容。
所谓的垂直扩容就是升级服务器,买性能更好的,更贵的然后替换原来的服务器,这种扩容方式不推荐使用。因为单台服务器的性能总是有瓶颈的。
水平扩容也称为横向扩展,很简单就是增加服务器的数量,这种扩容方式可持续性强,将众多普通服务器组织到一起就能形成强大的计算能力。水平扩容 VS 垂直扩容用一句俗语来说再合适不过了:三个臭皮匠赛过诸葛亮。
上面我们详细介绍了分片,master和协调节点,接下来我们通过画图的方式一步步带大家看看横向扩容的过程。
首先呢需要铺垫一点关于自定义索引shard数量的操作
PUT /student{: {: 3,: 1}}
以上代码意味着我们创建的索引student将会分配三个primary shard和三个replica shard(至于上面为什么是1,那是相对于索引来说的,前面解释过)。
4.3.1、一台服务器
当我们只有一台服务器的时候,shard是怎么分布的呢?

注:P代表primary shard, R代表replica shard。明确一点在后面的描述中默认一个es节点在一台服务器上。
分析一下上面的过程,首先需要明确的两点:
primary shard和replica shard不能再同一台机器上,因为replica和shard在同一个节点上就起不到副本的作用了。
当集群中只有一个节点的时候,node1节点将成为主节点。它将临时管理集群级别的一些变更,例如新建或 删除索引、增加或移除节点等。
明确了上面两点也就很简单了,因为集群中只有一个节点,该节点将直接被选举为master节点。其次我们为student索引分配了三个shard,由于只有一个节点,所以三个primary shard都被分配到该节点,replica shard将不会被分配。此时集群的健康状况为yellow。
4.3.2、增加一台服务器
接着上面继续,我们增加一台服务器,此时shard是如何分配的呢?

Rebalance(再平衡),当集群中节点数量发生变化时,将会触发es集群的rebalance,即重新分配shard。Rebalance的原则就是尽量使shard在节点中分布均匀,达到负载均衡的目的。
原先node1节点上有p0、p1、p2三个primary shard,另外三个replica shard还未分配,当集群新增节点node2,触发集群的Rebalance,另外三个replica shard将被分配到node2上,即如上图所示。
此时集群中所有的primary shard和replica shard都是active(可用)状态的所以此时集群的健康状况为yellow。可见es集群的最小高可用配置就是两太服务器。
4.3.3、继续新增服务器
继续新增服务器,集群将再次进行Rebalance,在primary shard和replica shard不能分配到一个节点上的原则,这次rebalance同样本着使shard均匀分布的原则,将会从node1上将P1,P2两个primary shard分配到node1,node2上面,然后将node2在primary shard和replica shard不能分配到一台机器上的原则上将另外两个replica shard分配到node1和node2上面。
注意:具体的分配方式上,可能是P0在node2上面也有可能在node3上面,但是只要本着Rebalance的原则将shard均匀分布达到负载均衡即可。
五、集群容灾
分布式的集群是一定要具备容灾能力的,对于es集群同样如此,那es集群是如何进行容灾的呢?接下来听我娓娓道来。
在前文我们详细讲解了primary shard和replica shard。replica shard作为primary shard的副本当集群中的节点发生故障,replica shard将被提升为primary shard。具体的演示如下
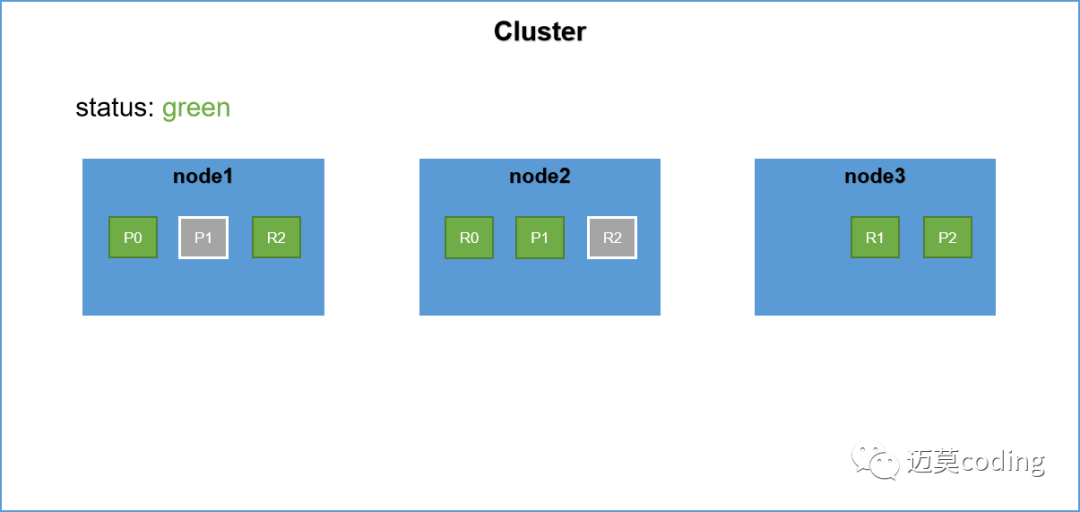
集群中有三台服务器,其中node1节点为master节点,primary shard 和 replica shard的分布如上图所示。此时假设node1发生宕机,也就是master节点发生宕机。此时集群的健康状态为red,为什么呢?因为不是所有的primary shard都是active的。
具体的容灾过程如下:
重新选举master节点,当es集群中的master节点发生故障,此时es集群将再次进行master的选举,选举出一个新的master节点。假设此时新的主节点为node2。
node2被选举为新的master节点,node2将作为master行驶其分片分配的任务。
replica shard升级,此时master节点会寻找node1节点上的P0分片的replica shard,发现其副本在node2节点上,然后将R0提升为primary shard。这个升级过程是瞬间完成的,就像按下一个开关一样。因为每一个shard其实都是lucene的实例。此时集群如下所示,集群的健康状态为yellow,因为不是每一个replica shard都是active的。

容灾的过程如上所示,其实这也是一般分布式中间件容灾备份的一般手段。如果你很了解kafka的话,这个就很容易理解了。
分割线
原文地址:https://www.cnblogs.com/hello-shf/p/11543468.html
往期推荐
文章也会持续更新,可以微信搜索「 迈莫coding 」第一时间阅读。每天分享优质文章、大厂经验、大厂面经,助力面试,是每个程序员值得关注的平台。
你点的每个赞,我都认真当成了喜欢