
详解Batch Normalization及其反向传播

极市导读
本文介绍了Batch Normalization的过程及其实现,它能帮助解决深度神经网络中输入不稳定的问题,并使得神经网络的梯度大小相对固定。
1. Internal Covariate Shift
统计学习中的一个很重要的假设就是输入的分布是相对稳定的。如果这个假设不满足,则模型的收敛会很慢,甚至无法收敛。所以,对于一般的统计学习问题,在训练前将数据进行归一化或者白化(whitening)是一个很常用的trick。
但这个问题在深度神经网络中变得更加难以解决。在神经网络中,网络是分层的,可以把每一层视为一个单独的分类器,将一个网络看成分类器的串联。这就意味着,在训练过程中,随着某一层分类器的参数的改变,其输出的分布也会改变,这就导致下一层的输入的分布不稳定。分类器需要不断适应新的分布,这就使得模型难以收敛。
对数据的预处理可以解决第一层的输入分布问题,而对于隐藏层的问题无能为力,这个问题就是Internal Covariate Shift。而Batch Normalization其实主要就是在解决这个问题。
除此之外,一般的神经网络的梯度大小往往会与参数的大小相关(仿射变换),且随着训练的过程,会产生较大的波动,这就导致学习率不宜设置的太大。Batch Normalization使得梯度大小相对固定,一定程度上允许我们使用更高的学习率。
2. Batch Normalization
Batch Normalization的过程很简单。我们假定我们的输入是一个大小为 的mini-batch ,通过下面的四个式子计算得到的 就是Batch Normalization(BN)的值。
首先,由(2.1)和(2.2)得到mini-batch的均值和方差,之后进行(2.3)的归一化操作,在分母加上一个小的常数是为了避免出现除0操作。最后的(2.4)再对 进行一次线性变换得到BN的结果。整个过程中,只有最后的(2.4)引入了额外参数γ和β,他们的size都为特征长度,与 相同。
BN层通常添加在隐藏层的激活函数之前,线性变换之后。如果我们把(2.4)和之后的激活函数放在一起看,可以将他们视为一层完整的神经网络(线性+激活)。(注意BN的线性变换和一般隐藏层的线性变换仍有区别,前者是element-wise的,后者是矩阵乘法。)
此时, 可以视为这一层网络的输入,而 是拥有固定均值和方差的。这就解决了Covariate Shift.
另外, 还具有保证数据表达能力的作用。 在normalization的过程中,不可避免的会改变自身的分布,而这会导致学习到的特征的表达能力有一定程度的丢失。通过引入参数γ和β,极端情况下,网络可以将γ和β训练为原分布的标准差和均值来恢复数据的原始分布。这样保证了引入BN,不会使效果更差。
在训练过程中,还需要维护一个移动平均的均值和方差,这两个移动平均会用于推断过程。
3. 反向传播
再来用反向传播求梯度。我们先画出BN的计算图,由于节点的文本不支持Tex,其中x_即为 。
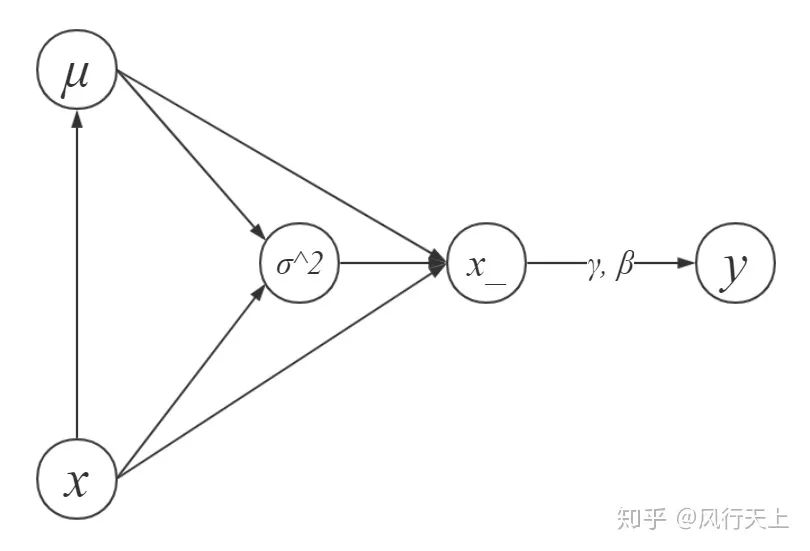
Batch Normalization的计算图
假定损失函数为L,已知L相对于 的偏导 ,求 , , 。
前两个比较直观,求 需要用到 ,也很简单,这里直接列出。
从计算图和(2.3)中可以看出,要求 ,要分成 , , 三部分来求。
我们还需要求 。
(3.6)可以由式(2.1)直接得到,(3.7)是运用链式法则的结果。
算 还需要 。
(3.8)可以由式(2.2)直接得到。
最后我们还需要方差的导数。
至此,(3.4)所需要的偏导都已求出,组合起来,我们得到最终的式子。
这个式子仍然具有进一步化简的空间。在展开之后,由式(2.3),通过拼凑,可以将 和 凑成 _。_再提取公因式 ,可以将式(3.10)化简成:
4. 实现
参考cs231n的assignment2,我们将Batch Normalization分成正向(只包括训练)和反向两个过程。
正向过程的参数x是一个mini-batch的数据,gamma和beta是BN层的参数,bn_param是一个字典,包括 的取值和用于inference的 和 的移动平均值,最后返回BN层的输出y,会在反向过程中用到的中间变量cache,以及更新后的移动平均。
反向过程的参数是来自上一层的误差信号dout,以及正向过程中存储的中间变量cache,最后返回 , , 的偏导数。
实现与推导的不同在于,实现是对整个batch的操作。
import numpy as npdef batchnorm_forward(x, gamma, beta, bn_param):# read some useful parameterN, D = x.shapeeps = bn_param.get('eps', 1e-5)momentum = bn_param.get('momentum', 0.9)running_mean = bn_param.get('running_mean', np.zeros(D, dtype=x.dtype))running_var = bn_param.get('running_var', np.zeros(D, dtype=x.dtype))# BN forward passsample_mean = x.mean(axis=0)sample_var = x.var(axis=0)x_ = (x - sample_mean) / np.sqrt(sample_var + eps)out = gamma * x_ + beta# update moving averagerunning_mean = momentum * running_mean + (1-momentum) * sample_meanrunning_var = momentum * running_var + (1-momentum) * sample_varbn_param['running_mean'] = running_meanbn_param['running_var'] = running_var# storage variables for backward passcache = (x_, gamma, x - sample_mean, sample_var + eps)return out, cachedef batchnorm_backward(dout, cache):# extract variablesN, D = dout.shapex_, gamma, x_minus_mean, var_plus_eps = cache# calculate gradientsdgamma = np.sum(x_ * dout, axis=0)dbeta = np.sum(dout, axis=0)dx_ = np.matmul(np.ones((N,1)), gamma.reshape((1, -1))) * doutdx = N * dx_ - np.sum(dx_, axis=0) - x_ * np.sum(dx_ * x_, axis=0)dx *= (1.0/N) / np.sqrt(var_plus_eps)return dx, dgamma, dbeta
参考文献
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift Deriving the Gradient for the Backward Pass of Batch Normalization CS231n Convolutional Neural Networks for Visual Recognition
推荐阅读
