
AI自动生成prompt媲美人类,网友:工程师刚被聘用,又要淘汰了
水木人工智能学堂
共 2462字,需浏览 5分钟
·
2022-11-15 02:39


论文地址:https://arxiv.org/pdf/2211.01910.pdf 论文主页:https://sites.google.com/view/automatic-prompt-engineer
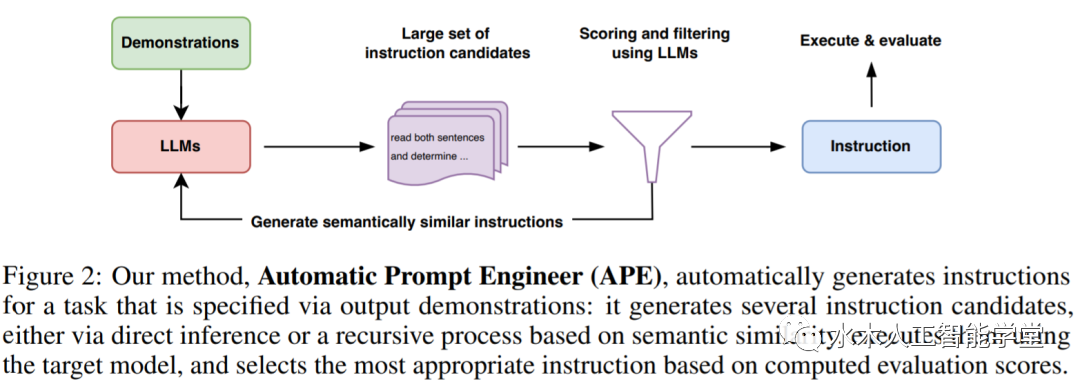
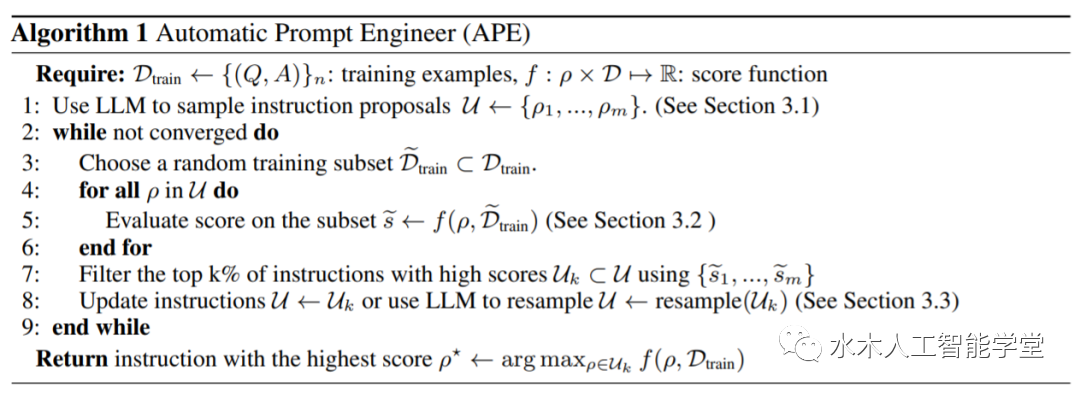
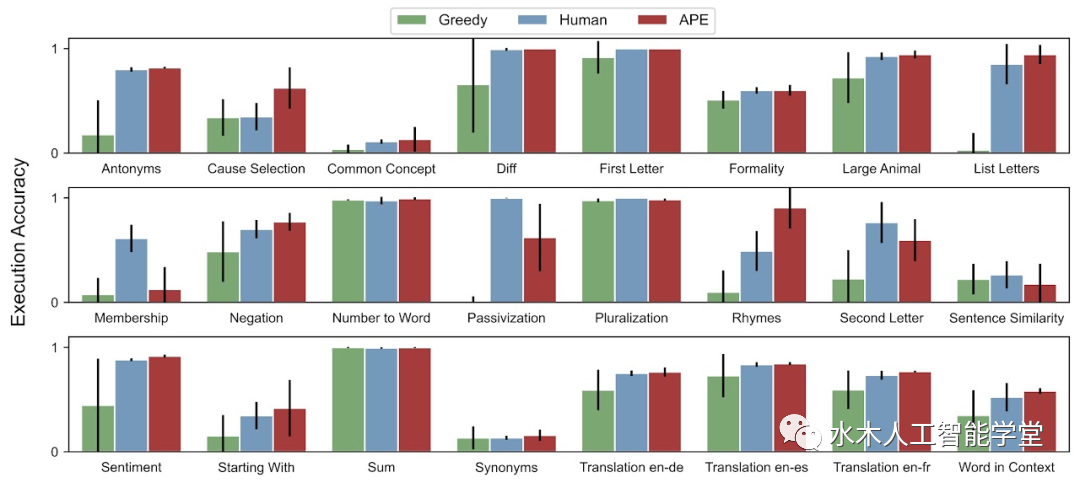
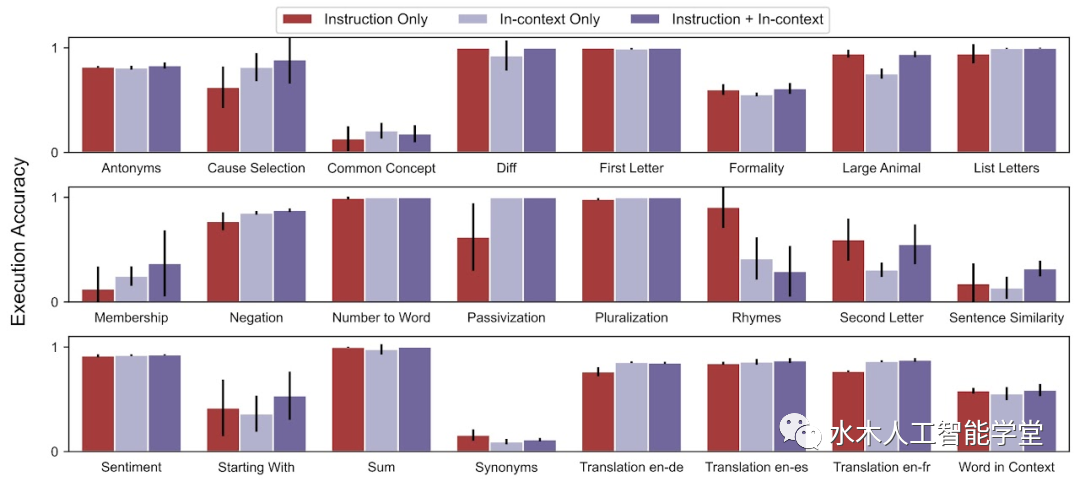
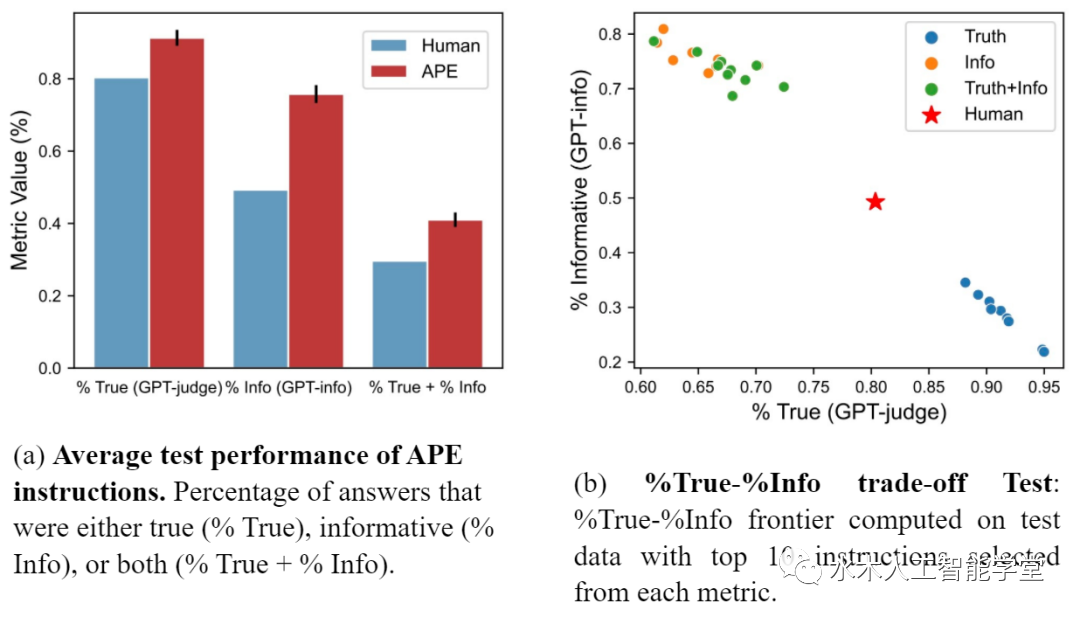
研究者将指令生成作为自然语言程序合成,将其表述为一个由LLM引导的黑盒优化问题,并提出迭代蒙特卡罗搜索方法来近似求解; APE 方法在19/24任务中实现了比人工注释器生成的指令更好或相当的性能。




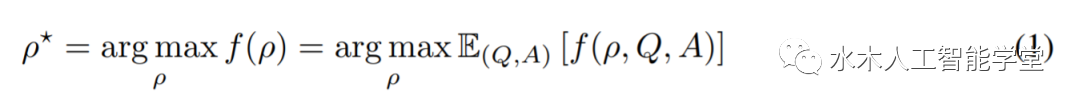
评论