
一次线上JVM GC 长暂停排查,加班搞了好久
大家好,我是小富,可以叫我靓仔。
给大家分享一篇我在知乎上看到的,针对长时间 GC 问题排查定位过程的文章。
最终原因定位到 swap 空间上,是我未曾设想过的角度,因为常规的 GC 问题,相当大一部分原因最终定位出来都是代码相关、流量相关、配置相关的,所以这个是让我耳目一新的。
也算是提供了一种问题排查的新方向和新思路,我是有所收获的,也分享给你,希望你也能有所收获。
作者:京东科技 徐传乐
原文链接:https://zhuanlan.zhihu.com/p/597891369
背景
在高并发下,Java程序的GC问题属于很典型的一类问题,带来的影响往往会被进一步放大。不管是「GC频率过快」还是「GC耗时太长」,由于GC期间都存在Stop The World问题,因此很容易导致服务超时,引发性能问题。
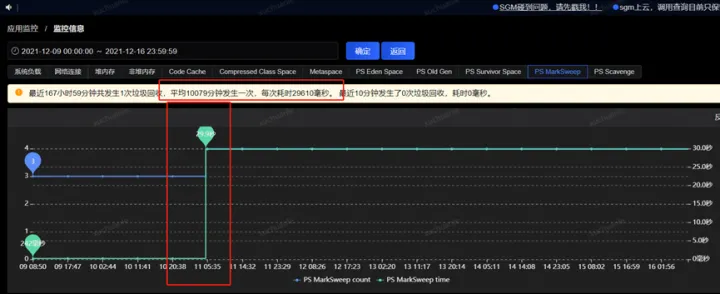
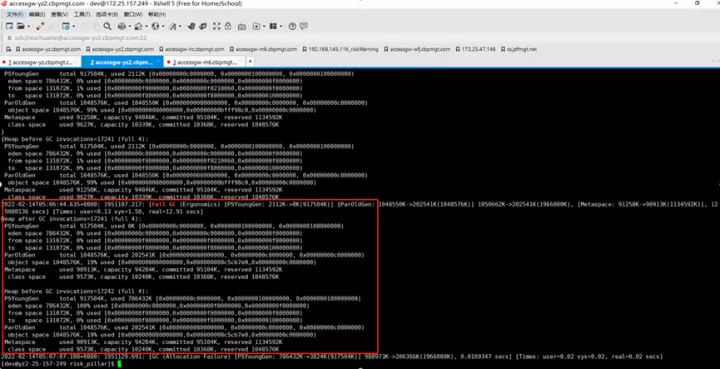
事情最初是线上某应用垃圾收集出现Full GC异常的现象,应用中个别实例Full GC时间特别长,持续时间约为15~30秒,平均每2周左右触发一次;
JVM参数配置:
-Xms2048M –Xmx2048M –Xmn1024M –XX:MaxPermSize=512M
排查过程
分析 GC 日志
GC 日志它记录了每一次的 GC 的执行时间和执行结果,通过分析 GC 日志可以调优堆设置和 GC 设置,或者改进应用程序的对象分配模式。
这里Full GC的reason是Ergonomics,是因为开启了UseAdaptiveSizePolicy,jvm自己进行自适应调整引发的Full GC。
这份日志主要体现GC前后的变化,目前为止看不出个所以然来。
开启GC日志,需要添加如下 JVM 启动参数:
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/export/log/risk_pillar/gc.log
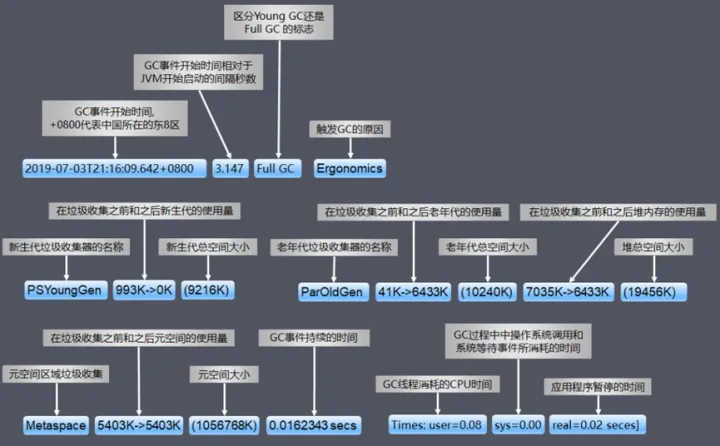
常见的 Young GC、Full GC 日志含义如下:
进一步查看服务器性能指标
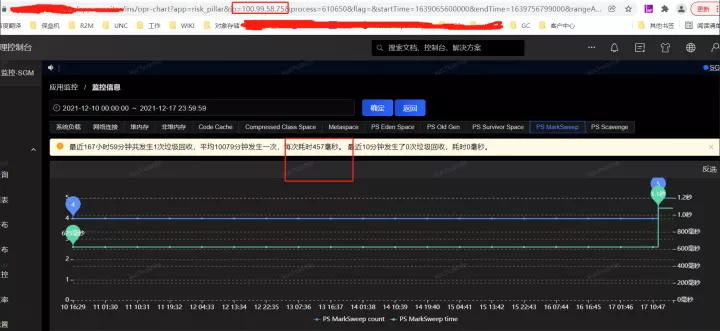
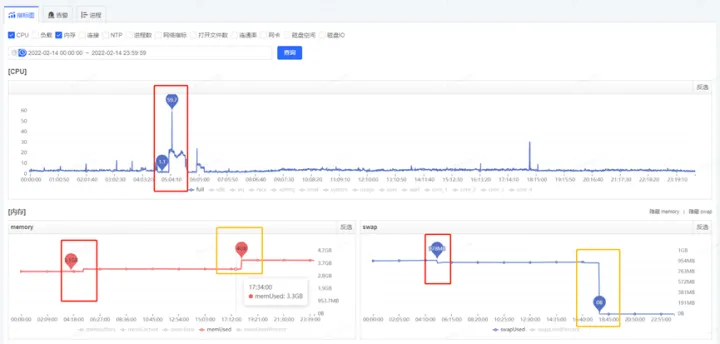
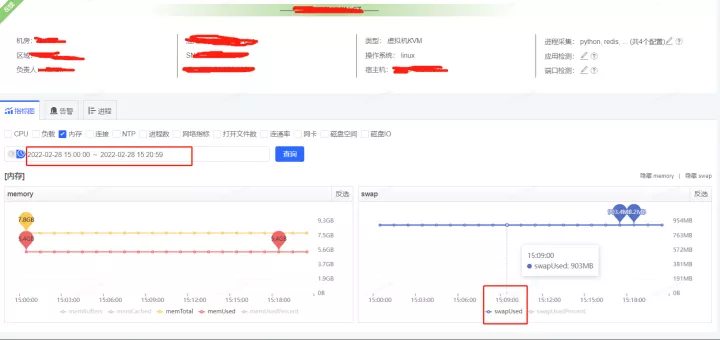
获取到了GC耗时的时间后,通过监控平台获取到各个监控项,开始排查这个时点有异常的指标,最终分析发现,在5.06分左右(GC的时点),CPU占用显著提升,而SWAP出现了释放资源、memory资源增长出现拐点的情况(详见下图红色框,橙色框中的变化是因修改配置导致,后面会介绍,暂且可忽略)
JVM用到了swap?
是因为GC导致的CPU突然飙升,并且释放了swap交换区这部分内存到memory?
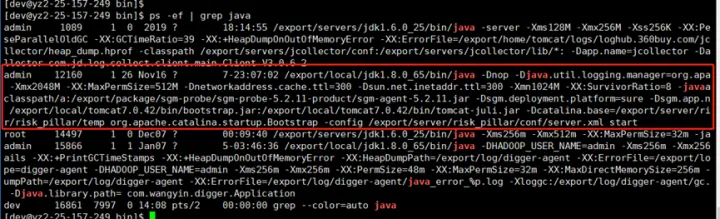
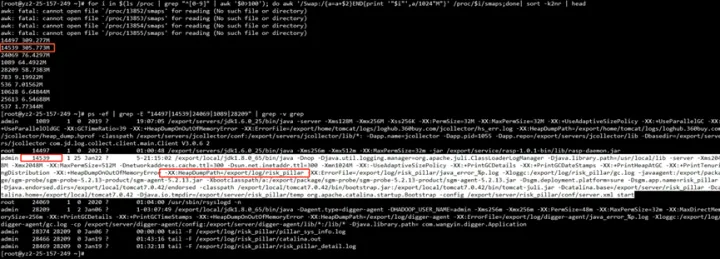
为了验证JVM是否用到swap,我们通过检查proc下的进程内存资源占用情况
for i in (cd/proc;ls∣grep"[0−9]"∣awk′0 >100');
do awk '/Swap:/{a=a+2}END{print '"i"',a/1024"M"}' /proc/$i/smaps 2>/dev/null;
done | sort -k2nr | head -10
# head -10 表示 取出 前10个内存占用高的进程
# 取出的第一列为进程的id 第二列进程占用swap大小
看到确实有用到305MB的swap
这里简单介绍下什么是swap?
swap指的是一个交换分区或文件,主要是在内存使用存在压力时,触发内存回收,这时可能会将部分内存的数据交换到swap空间,以便让系统不会因为内存不够用而导致oom或者更致命的情况出现。
当某进程向OS请求内存发现不足时,OS会把内存中暂时不用的数据交换出去,放在swap分区中,这个过程称为swap out。
当某进程又需要这些数据且OS发现还有空闲物理内存时,又会把swap分区中的数据交换回物理内存中,这个过程称为swap in。
为了验证GC耗时与swap操作有必然关系,我抽查了十几台机器,重点关注耗时长的GC日志,通过时间点确认到GC耗时的时间点与swap操作的时间点确实是一致的。
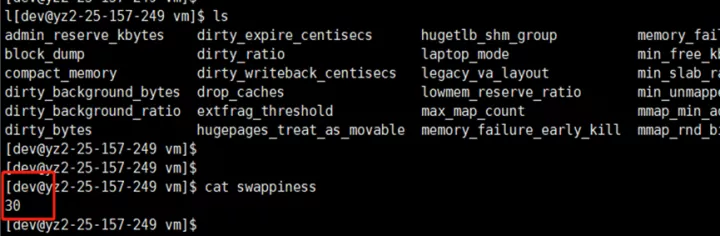
进一步查看虚拟机各实例 swappiness 参数,一个普遍现象是,凡是发生较长Full GC的实例都配置了参数 vm.swappiness = 30(值越大表示越倾向于使用swap);而GC时间相对正常的实例配置参数 vm.swappiness = 0(最大限度地降低使用swap)。
swappiness 可以设置为 0 到 100 之间的值,它是Linux的一个内核参数,控制系统在进 行swap时,内存使用的相对权重。
- swappiness=0: 表示最大限度使用物理内存,然后才是 swap空间
- swappiness=100: 表示积极的使用swap分区,并且把内存上的数据及时的交换到swap空间里面
对应的物理内存使用率和swap使用情况如下

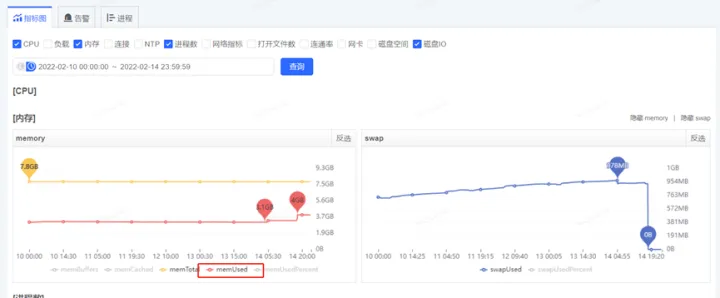
至此,矛头似乎都指向了swap。
问题分析
当内存使用率达到水位线(vm.swappiness)时,linux会把一部分暂时不使用的内存数据放到磁盘swap去,以便腾出更多可用内存空间;
当需要使用位于swap区的数据时,再将其换回内存中,当JVM进行GC时,需要对相应堆分区的已用内存进行遍历;
假如GC的时候,有堆的一部分内容被交换到swap空间中,遍历到这部分的时候就需要将其交换回内存,由于需要访问磁盘,所以相比物理内存,它的速度肯定慢的令人发指,GC停顿的时间一定会非常非常恐怖;
进而导致Linux对swap分区的回收滞后(内存到磁盘换入换出操作十分占用CPU与系统IO),在高并发/QPS服务中,这种滞后带来的结果是致命的(STW)。
问题解决
至此,答案似乎很清晰,我们只需尝试把swap关闭或释放掉,看看能否解决问题?
如何释放swap?
设置vm.swappiness=0(重启应用释放swap后生效),表示尽可能不使用交换内存
方案 a:临时设置方案,重启后不生效
- 设置vm.swappiness为0,sysctl vm.swappiness=0
- 查看swappiness值,cat /proc/sys/vm/swappiness
方案b:永久设置方案,重启后仍然生效
- vi /etc/sysctl.conf
- 关闭交换分区swapoff –a(前提:首先要保证内存剩余要大于等于swap使用量,否则会报Cannot allocate memory!swap分区一旦释放,所有存放在swap分区的文件都会转存到物理内存上,可能会引发系统IO或者其他问题。)
查看当前swap分区挂载在哪:

关停分区:

关闭swap交换区后的内存变化见下图橙色框,此时swap分区的文件都转存到了物理内存上
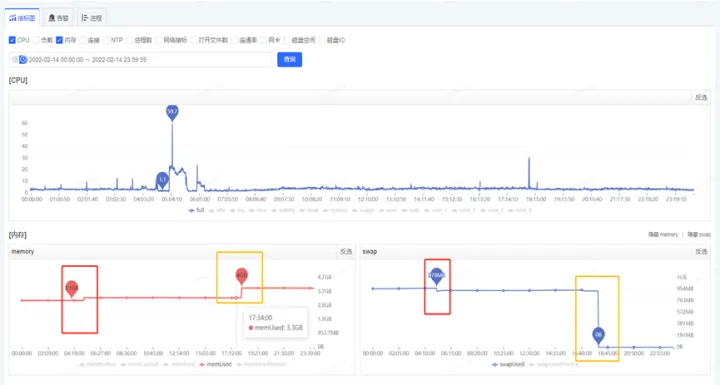
关闭Swap交换区后,于2.23再次发生Full GC,耗时190ms,问题得到解决。
疑惑
- 是不是只要开启了swap交换区的JVM,在GC的时候都会耗时较长呢?
- 既然JVM对swap如此不待见,为何JVM不明令禁止使用呢?
- swap工作机制是怎样的?这台物理内存为8g的server,使用了交换区内存(swap),说明物理内存不够使用了,但是通过free命令查看内存使用情况,实际物理内存似乎并没有占用那么多,反而Swap已占近1G?

free:除了buff/cache剩余了多少内存
shared:共享内存
buff/cache:缓冲、缓存区内存数(使用过高通常是程序频繁存取文件)
available:真实剩余的可用内存数
进一步思考
大家可以想想,关闭交换磁盘缓存意味着什么?
其实大可不必如此激进,要知道这个世界永远不是非0即1的,大家都会或多或少选择走在中间,不过有些偏向0,有些偏向1而已。
很显然,在swap这个问题上,JVM可以选择偏向尽量少用,从而降低swap影响,要降低swap影响有必要弄清楚Linux内存回收是怎么工作的,这样才能不遗漏任何可能的疑点。
先来看看swap是如何触发的?
Linux会在两种场景下触发内存回收,一种是在内存分配时发现没有足够空闲内存时会立刻触发内存回收;另一种是开启了一个守护进程(kswapd进程)周期性对系统内存进行检查,在可用内存降低到特定阈值之后主动触发内存回收。
通过如下图示可以很容易理解,详细信息参见:
http://hbasefly.com/2017/05/24/hbase-linux/
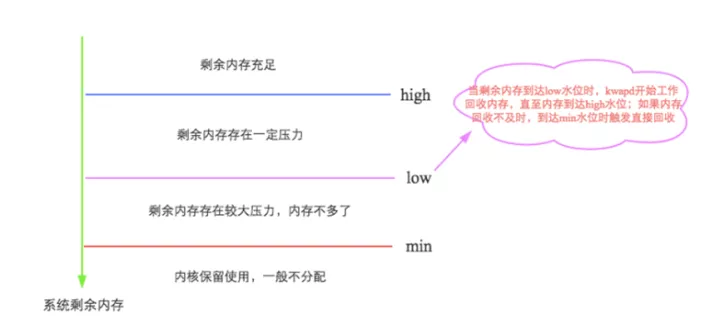
是不是只要开启了swap交换区的JVM,在GC的时候都会耗时较长?
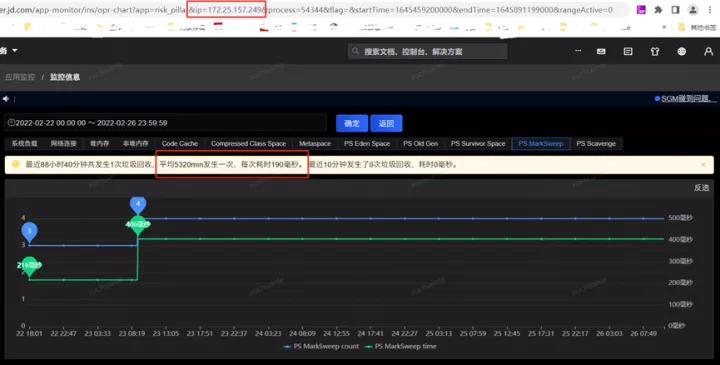
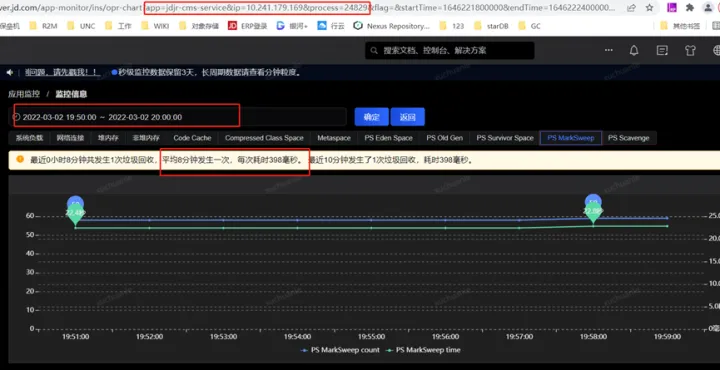
笔者去查了一下另外的一个应用,相关指标信息请见下图。
实名服务的QPS是非常高的,同样能看到应用了swap,GC平均耗时 576ms,这是为什么呢?
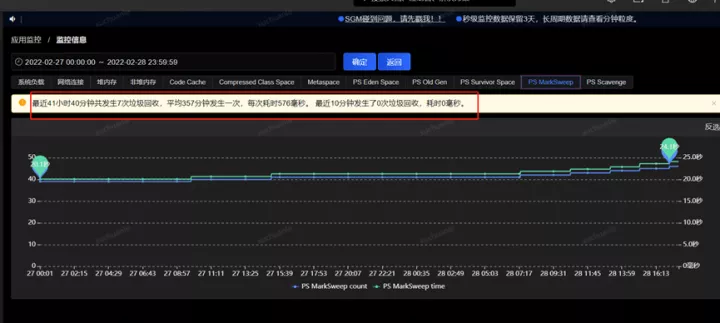
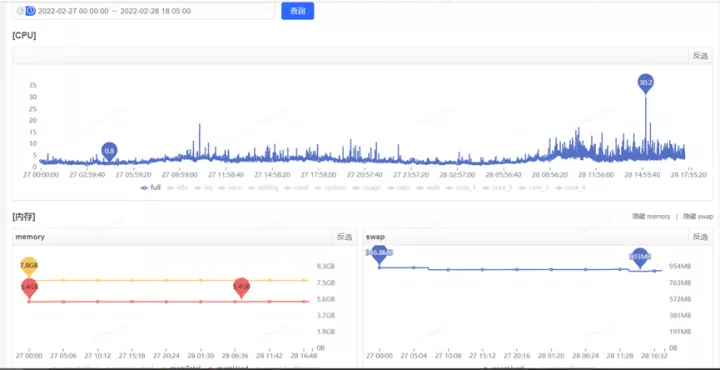
通过把时间范围聚焦到发生GC的某一时间段,从监控指标图可以看到swapUsed没有任何变化,也就是说没有swap活动,进而没有影响到垃级回收的总耗时。
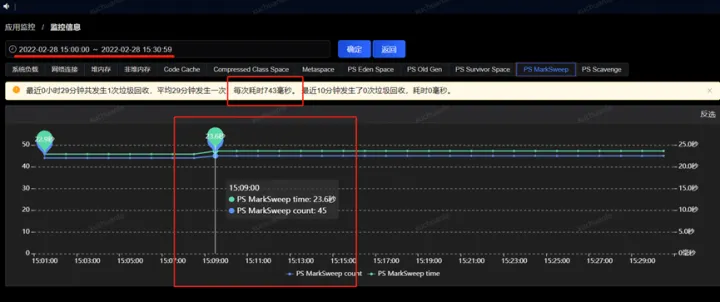
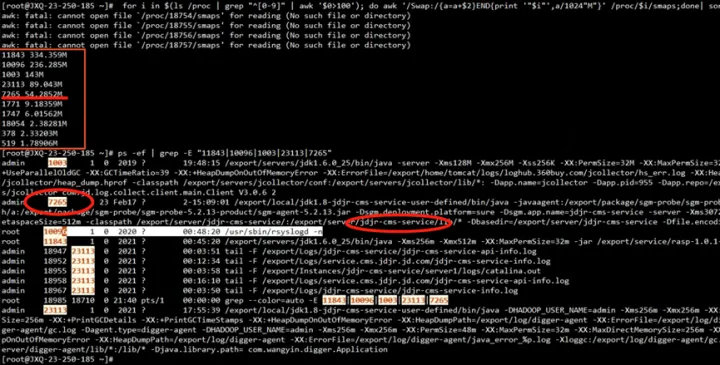
通过如下命令列举出各进程swap空间占用情况,很清楚的看到实名这个服务swap空间占用的较少(仅54.2MB)
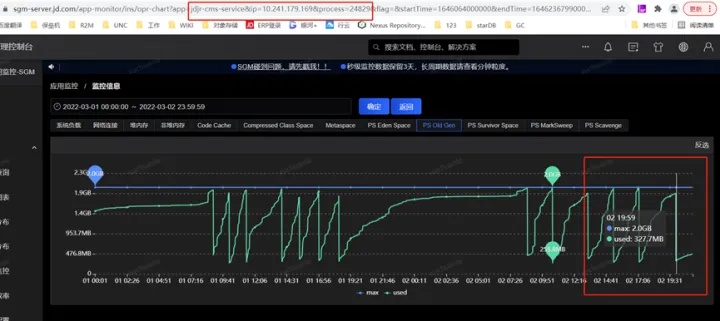
另一个显著的现象是实名服务Full GC间隔较短(几个小时一次),而我的服务平均间隔2周一次Full GC
基于以上推测
- 实名服务由于 GC 间隔较短,内存中的东西根本没有机会置换到swap中就被回收了,GC的时候不需要将swap分区中的数据交换回物理内存中,完全基于内存计算,所以要快很多
- 将哪些内存数据置换进swap交换区的筛选策略应该是类似于LRU算法(最近最少使用原则)
为了证实上述猜测,我们只需跟踪swap变更日志,监控数据变化即可得到答案,这里采用一段shell 脚本实现
#!/bin/bash
echo -e `date +%y%m%d%H%M%S`
echo -e "PID\t\tSwap\t\tProc_Name"
#拿出/proc目录下所有以数字为名的目录(进程名是数字才是进程,其他如sys,net等存放的是其他信息)
for pid in `ls -l /proc | grep ^d | awk '{ print $9 }'| grep -v [^0-9]`
do
if [ $pid -eq 1 ];then continue;fi
grep -q "Swap" /proc/$pid/smaps 2>/dev/null
if [ $? -eq 0 ];then
swap=$(gawk '/Swap/{ sum+=$2;} END{ print sum }' /proc/$pid/smaps) #统计占用的swap分区的 大小 单位是KB
proc_name=$(ps aux | grep -w "$pid" | awk '!/grep/{ for(i=11;i<=NF;i++){ printf("%s ",$i); }}') #取出进程的名字
if [ $swap -gt 0 ];then #判断是否占用swap 只有占用才会输出
echo -e "${pid}\t${swap}\t${proc_name:0:100}"
fi
fi
done | sort -k2nr | head -10 | gawk -F'\t' '{ #排序取前 10
pid[NR]=$1;
size[NR]=$2;
name[NR]=$3;
}
END{
for(id=1;id<=length(pid);id++)
{
if(size[id]<1024)
printf("%-10s\t%15sKB\t%s\n",pid[id],size[id],name[id]);
else if(size[id]<1048576)
printf("%-10s\t%15.2fMB\t%s\n",pid[id],size[id]/1024,name[id]);
else
printf("%-10s\t%15.2fGB\t%s\n",pid[id],size[id]/1048576,name[id]);
}
}
由于上面图中 2022.3.2 19:57:00 至 2022.3.2 19:58:00 发生了一次Full GC,我们重点关注下这一分钟内swap交换区的变化即可,我这里每10s做一次信息采集,可以看到在GC时点前后,swap确实没有变化

通过上述分析,回归本文核心问题上,现在看来我的处理方式过于激进了,其实也可以不用关闭swap,通过适当降低堆大小,也是能够解决问题的。
这也侧面的说明,部署Java服务的Linux系统,在内存分配上并不是无脑大而全,需要综合考虑不同场景下JVM对Java永久代 、Java堆(新生代和老年代)、线程栈、Java NIO所使用内存的需求。
总结
综上,我们得出结论,swap和GC同一时候发生会导致GC时间非常长,JVM严重卡顿,极端的情况下会导致服务崩溃。
主要原因是:JVM进行GC时,需要对对应堆分区的已用内存进行遍历,假如GC的时候,有堆的一部分内容被交换到swap中,遍历到这部分的时候就须要将其交换回内存;更极端情况同一时刻因为内存空间不足,就需要把内存中堆的另外一部分换到SWAP中去,于是在遍历堆分区的过程中,会把整个堆分区轮流往SWAP写一遍,导致GC时间超长。线上应该限制swap区的大小,如果swap占用比例较高应该进行排查和解决,适当的时候可以通过降低堆大小,或者添加物理内存。
因此,部署Java服务的Linux系统,在内存分配上要慎重。
以上内容希望可以起到抛转引玉的作用,如有理解不到位的地方烦请指出。
好了,本文的技术部分就到这里啦。
·············· END ··············
