
我的 百度搜索记录 被同事用Python监控,我哭了!
来源 | python数据分析之禅
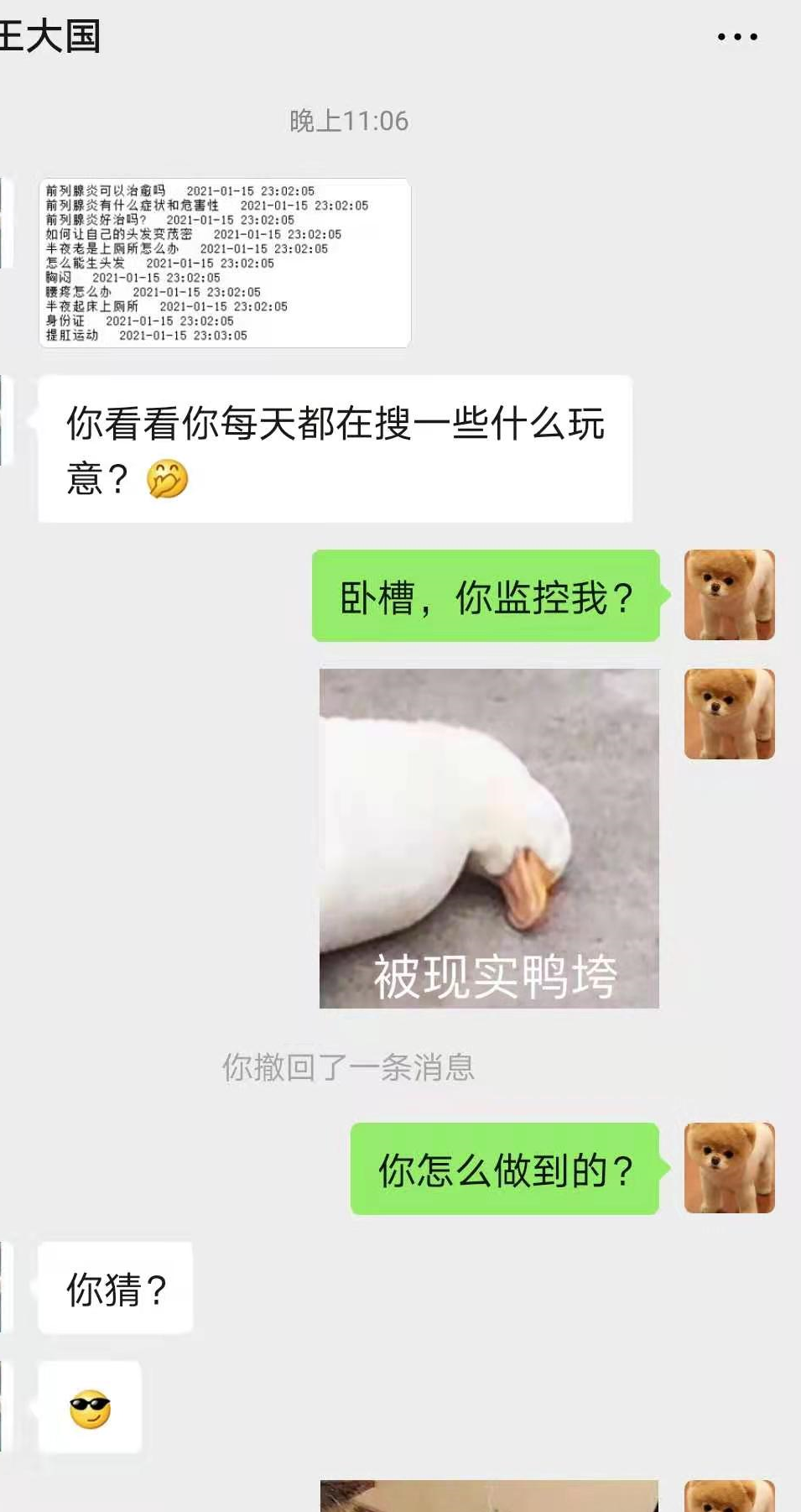
尴尬的想找个地缝钻进去
经过一番询问,他终于道出了实情,原来百度的账号会自动同步。
例如,在登录了网页版的百度地图、百度API等账号后,浏览器会自动保持,你的所有百度账号就自动登上了。
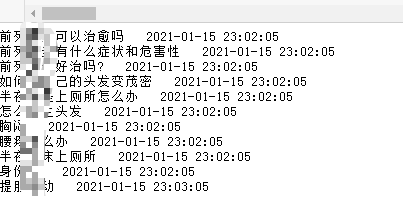
当你使用已登录百度账号手机或电脑的百度搜索框时,他那里就会自动弹出历史搜索记录,如下图:

然后可以用python爬虫定时获取搜索记录
首先抓包获取数据接口:
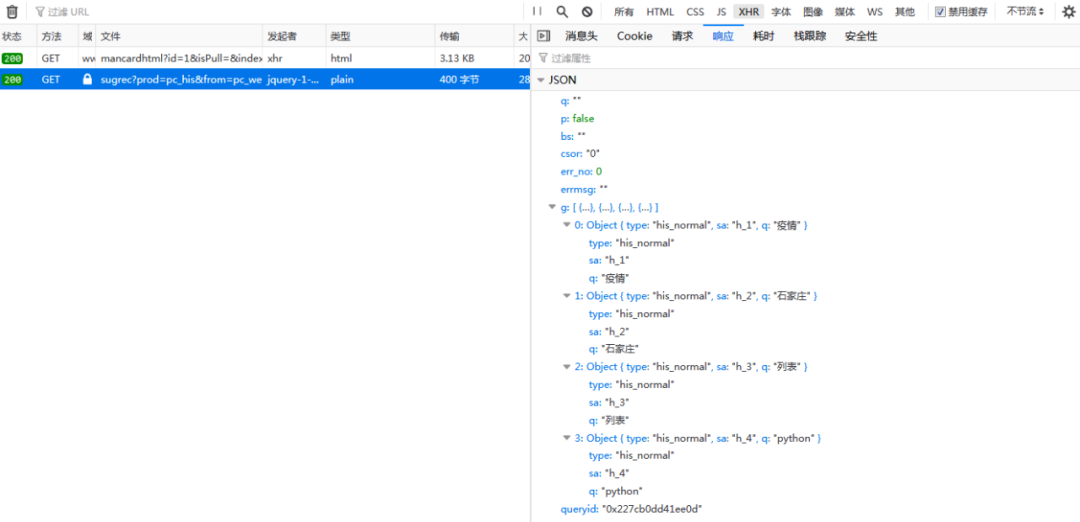
然后写个小爬虫,因为要有账号信息,所以要带上cookie:
import requests
header={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0',
"Cookie":'',
url='https://www.baidu.com/sugrec?prod=pc_his&from=pc_web&json=1'
response=requests.get(url,headers=header)
print(response.text)
UnicodeEncodeError: 'latin-1' codec can't encode character '\u2026' in position 518: ordinal not in range(256)但是你可能会遇到上面这种情况,报编码错误
我去网上查了一下,以为是编码的问题,然后给cookie加了“utf-8”编码方式,如下:
import requests
header={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0',
"Cookie":''.encode("utf-8"),
url='https://www.baidu.com/sugrec?prod=pc_his&from=pc_web&json=1'
response=requests.get(url,headers=header)
print(response.text)
{"err_no":0,"errmsg":"","queryid":"0x21a1c8a90872b8"}又报错了。。。。。
就在我认为百度是不是有什么高端的反爬措施时,突然发现cookie的“BDUSS”参数有点问题,如下:
BDUSS=JkRjIyUFR2T01Yd3QxcTZ…AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAP4Gzl~-Bs5fZX中间多了省略号,这是因为字符太长了,被自动省略了,于是我赶紧把该参数补全,重新尝试了一下:
import requests
header={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0',
"Cookie":'',
}
url='https://www.baidu.com/sugrec?prod=pc_his&from=pc_web&json=1'
response=requests.get(url,headers=header)
print(response.text)
大功告成
最后加个循环程序:
import requests
import json
import datetime,time
header={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0',
"Cookie":'',
}
url='https://www.baidu.com/sugrec?prod=pc_his&from=pc_web&json=1'
result=[]
while True:
dt = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S') #时间戳
response=requests.get(url,headers=header)
datas=json.loads(response.text)['g']
for data in datas:
if data['q'] not in result:
print(data['q']+' '+dt)
result.append(data['q'])
time.sleep(60)
以自己的亲身经历告诉大家,千万不要在被人电脑上乱登账号,小则丢人、大则丢金,切记切记!

评论