NeurIPS 2022 |前沿研究探索既有创造力又负责任的人工智能
共 4156字,需浏览 9分钟
·
2022-12-02 23:31
作为目前全球最负盛名的人工智能盛会之一,NeurIPS (Conference on Neural Information Processing Systems) 在每年年末都是计算机科学领域瞩目的焦点。被 NeurIPS 接收的论文,代表着当今神经科学和人工智能研究的最高水平。今年的 NeurIPS 大会将于11月28日至12月9日举行,本届大会共收到10411篇有效投稿,其中2672篇获接收,最终接收率为25.6%。相比去年,投稿数量继续增加。
在本届大会中,微软亚洲研究院也有诸多论文入选,内容主要涵盖人工智能五大热点话题:人工智能走向大一统、计算机理论、赋能产业界的人工智能、负责任的人工智能、人工智能赋能内容与设计生成。前两期我们已经和大家分享了人工智能大一统、理论研究,与赋能产业界的人工智能的研究最前沿。那么人工智能的研究将在哪些方面继续上推动内容与设计生成?负责任的人工智能领域又有了什么新的发现?阅读今天的文章,你或许能找到这些问题的答案!
人工智能赋能内容与设计生成
AI Empowered Content and Design Generation
BinauralGrad: 面向双声道音频合成的两阶段去噪扩散概率模型

论文链接:
https://arxiv.org/abs/2205.14807
代码链接:
https://github.com/microsoft/NeuralSpeech
Demo链接:
https://speechresearch.github.io/binauralgrad/
空间音频可以给人身临其境的体验,在沉浸式游戏、虚拟现实和元宇宙中都有着很大的应用前景,如何准确的生成高质量的空间音频是一个重要的研究问题。因此,微软亚洲研究院的研究员们提出了 BinauralGrad,使用单声道音频以及声源和听者的动态相对位置作为输入,生成具有空间感的双声道音频。
考虑到声音产生的具体物理过程,研究员们提出了一个两阶段模型,来更准确的建模空间音频(如图1):第一阶段模型建模同时影响左右声道的因素,比如房间混响以及声源和听者的距离;第二阶段模型建模左右声道不同的部分,比如左右耳离声源微小的距离差和角度差。具体来说,第一阶段模型的优化目标是双声道音频左右声道的平均值,这个平均值和输入的单声道音频的差异反映了同时影响左右声道的因素,第二阶段模型的优化目标是双声道音频。BinauralGrad 的两阶段结构符合空间音频的产生过程,降低了模型训练难度,从而提升了生成的空间音频的位置准确性。

图1:BinauralGrad 的两阶段模型
在空间音频数据集中对比 BinauralGrad 和基线系统,基线系统包括基于信号处理(DSP)的空间音频合成系统和基于神经网络的空间音频合成系统(WaveNet、WarpNet),实验表明,相比于以前的空间音频生成工作,BinauralGrad生成的结果:1)在波形上跟真实空间音频误差更小(Wave L2);2)在感知分数上更高(PESQ);3)在频谱上更相似(Amplitude L2、Phase L2、MRSTFT)。消融实验和主观测试也进一步验证了两阶段模型的有效性和 BinauralGrad 生成的空间音频的准确性。

表1:BinauralGrad 和基线系统的对比
Museformer: 结合粗/细粒度注意力机制的音乐生成模型

论文链接:
https://arxiv.org/abs/2210.10349
代码链接:
https://github.com/microsoft/muzic
Demo链接:
https://ai-muzic.github.io/museformer/
近年来,音乐生成受到越来越多的关注,将 Transformer 应用于该任务也成为新的趋势。然而,不同于文本生成,音乐生成面临两大挑战:1)长序列建模:音乐序列通常很长(超过10000个token),传统全注意力(full attention)的复杂度很高,很难处理如此长的序列。2)音乐结构建模:音乐具有重复结构,通常相隔一定时间后会重复之前的乐句,现有的长序列 Transformer 模型在建模这种音乐结构上存在不足。
为了更好地建模音乐长序列,本文提出了 Museformer,它包含一种新颖的细粒度和粗粒度相结合的注意力机制,更加切合音乐序列的特点。为了针对性学习重复结构,细粒度注意力中每个 token 都能直接看到结构相关小节(structure-related bar)内的所有 token,从而能够精确地捕捉结构关系;此外,为了保留其他重要信息,对于其他小节使用粗粒度注意力,每个 token 只能看到聚合了局部信息的 summary token。本文使用了相似度统计来确定结构相关小节,统计结果显示音乐普遍具有以4或4的倍数个小节为距离进行重复的模式。通过将细粒度和粗粒度注意力相结合,Museformer 既能精准编码音乐结构的相关信息,又能以较小代价保留其他重要信息。
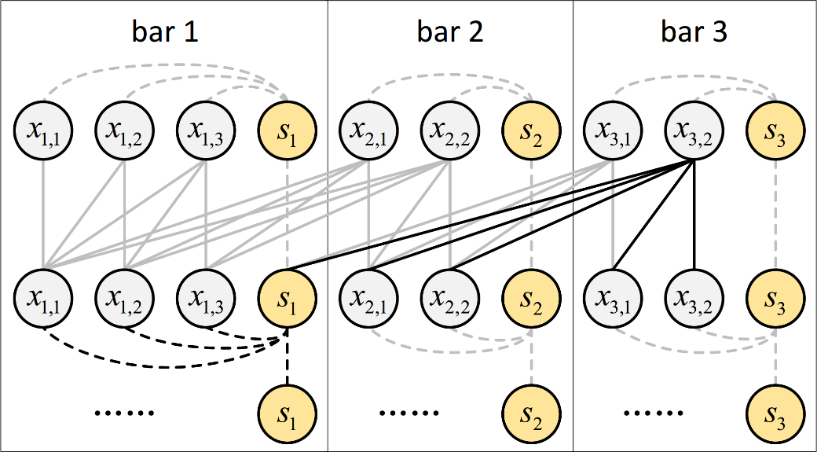
客观实验证明,相较于几个有代表性的 Transformer 衍生模型,Museformer 能够取得最好的困惑度(perplexity),并且生成的音乐也和训练集的音乐具有最相似的结构特征。主观实验证明,Museformer 能够在音乐性和结构性等各项指标上取得最高分,且总体评分上相较其他模型有统计上的显著提升。效率方面,相较于全注意力模型,在32GB显存下,Museformer 能够编码超过其3倍长度的序列,训练速度在长序列场景下也提升显著。

表2:客观评测和消融实验结果

表3:主观测评结果
负责任的人工智能
Responsible AI
FairVFL: 公平的纵向联邦学习

论文链接:
https://www.microsoft.com/en-us/research/publication/fairvfl-a-fair-vertical-federated-learning-framework-with-contrastive-adversarial-learning/
传统的机器学习需要中心化收集和存储数据,容易造成巨大的隐私风险和担忧。联邦学习是一种重要的隐私保护机器学习框架,可以在不收集数据的前提下实现模型的协同学习,是机器学习的一个热门研究领域。其中,纵向联邦学习(vertical federated learning, VFL)是联邦学习的一种重要范式,可以联合学习和利用分散在不同平台上的特征。由于现实训练数据中通常包含着偏见,所以从数据中学到的纵向联邦学习模型往往对具有某些敏感属性(如性别和年龄)的用户群体并不公平。虽然机器学习的模型公平性被广泛关注和研究,已有的方法都假设训练数据和敏感属性信息是存储在一起的,然而在纵向联邦学习的场景下,二者往往分布在不同平台。
为了解决上述问题,微软亚洲研究院的研究员们希望在模型性能、用户隐私以及公平性中取得较好的平衡,因此提出了 FairVFL 框架。该框架的核心是基于分布式的特征以保护隐私的方式学习公平的统一表征。FairVFL 首先会得到各个数据特征存储平台的局部数据表征,然后再将这些局部数据表征上传到可信服务器上进行针对目标任务的统一表征的聚合。为了学习公平的统一表征,研究员们将聚合后的统一表征发送至各个存储敏感属性的平台,并应用对抗学习来消除从有偏见(biased)的数据中学到的统一表示中的偏见。此外,为了保护用户隐私,研究员们还在将含有用户隐私信息的统一表征发送到存储敏感属性的平台之前,利用对比对抗性学习从统一表征中删除隐私信息。在三个真实数据集上的实验验证了 FairVFL 可以在保护用户隐私的同时有效地提高模型的公平性。
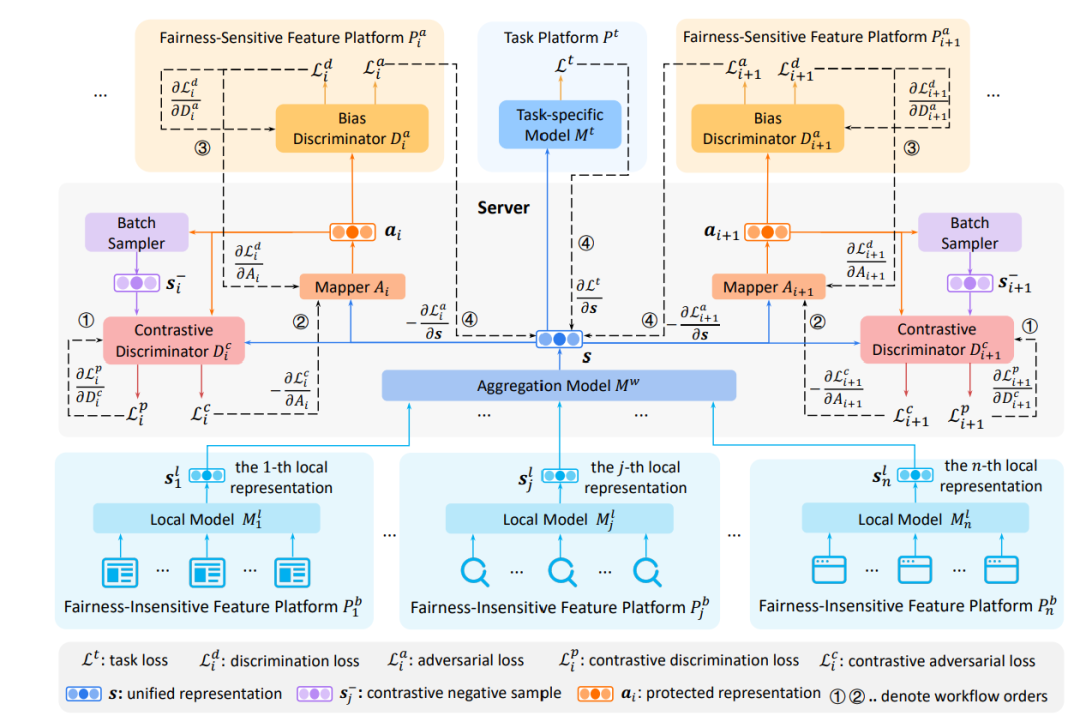
图3:FairVFL 框架
基于逻辑规则推理的自可解释深度学习框架

论文链接:
https://www.microsoft.com/en-us/research/publication/self-explaining-deep-models-with-logic-rule-reasoning/
如何保证解释和人类推理过程一致,或解释对人精度(Human Precision)高,是可解释人工智能领域重要、困难却经常被忽视的问题。Human Precision 高要求人看到解释以后,认为人工智能的解释合理,能根据人工智能的解释自然而然地猜出模型的预测结果。例如,对人精度高的解释是“awesome, tasty => positive sentiment”(因为句子含有 awesome 和 tasty,所以是正面情感),而不是“is, and => positive sentiment”。
本文中提出了达到高对人精度的两个条件,说明了逻辑规则形式的解释天然能够满足这两个条件。基于此,微软亚洲研究院的研究员们提出了一个基于逻辑规则的自可解释深度学习框架。此框架的优点如下:
1)模型无关:能够将给定的深度模型升级成为以逻辑规则推理的自可解释深度模型
2)对人精度高:用户实验表明本文提出的自可解释模型的解释与人推理逻辑相似性,相较于现有方法有显著提高
3)预测准确性高:升级后的自可解释模型的准确性和原模型没有显著差别
4)鲁棒性高:升级后的自可解释模型比原始黑盒模型对噪音更加鲁棒
5)容易融入用户反馈:不需要重新训练模型,用户就能够修改模型的预测逻辑

图4:自可解释深度模型框架
如图4所示,升级后的自可解释深度模型由两部分组成。其中,①是基于深度学习的。它根据深度模型学习的表达式输入表征,选择一个适用规则(例如"hurt AND black")。这一部分类似人脑的潜意识部分,可以快速关注到重要信息。②类似人类推理部分,根据规则来判断结果(例如“negative sentiment”)。这一部分是一个可以被人类完全理解和控制的白盒子,想当于对用户友好的交互界面,允许用户根据他们的知识和需要直接编辑模型逻辑,例如,阻止模型使用 "black"这个词进行情感预测。
分享
收藏
点赞
在看