
2012年至今,细数深度学习领域这些年取得的经典成果!
这些研究均已经过时间的考验,并得到广泛认可。

ImageNet Classification with Deep Convolutional Neural Networks (2012),https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks Improving neural networks by preventing co-adaptation of feature detectors (2012) ,https://arxiv.org/abs/1207.0580 One weird trick for parallelizing convolutional neural networks (2014) ,https://arxiv.org/abs/1404.5997
用PyTorch搭建AlexNet,https://pytorch.org/hub/pytorch_vision_alexnet/ 用TensorFlow搭建AlexNet,https://github.com/tensorflow/models/blob/master/research/slim/nets/alexnet.py
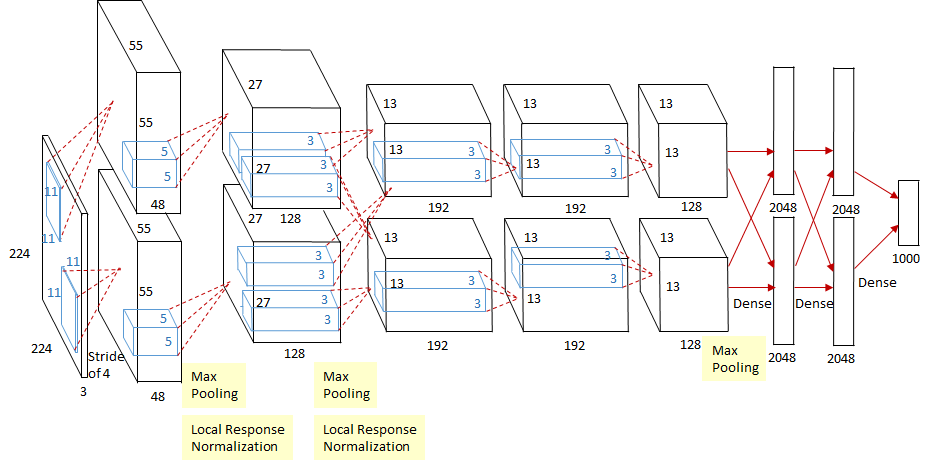
Playing Atari with Deep Reinforcement Learning (2013),https://arxiv.org/abs/1312.5602
用PyTorch搭建深度强化学习模型(DQN),https://pytorch.org/tutorials/intermediate/reinforcement_q_learning.html 用TensorFlow搭建DQN,https://www.tensorflow.org/agents/tutorials/1_dqn_tutorial
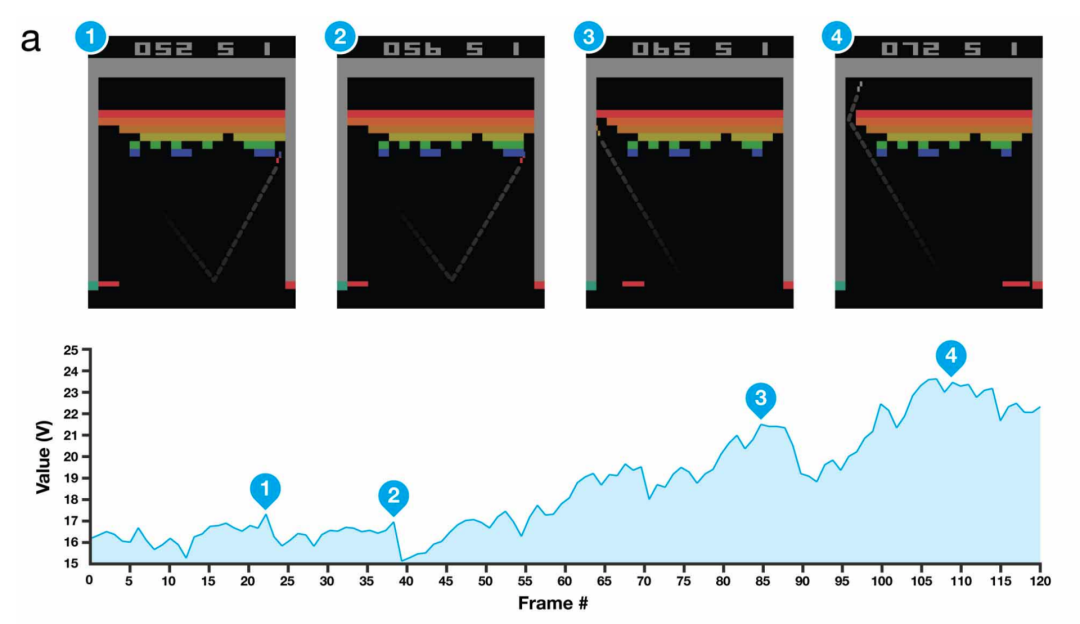
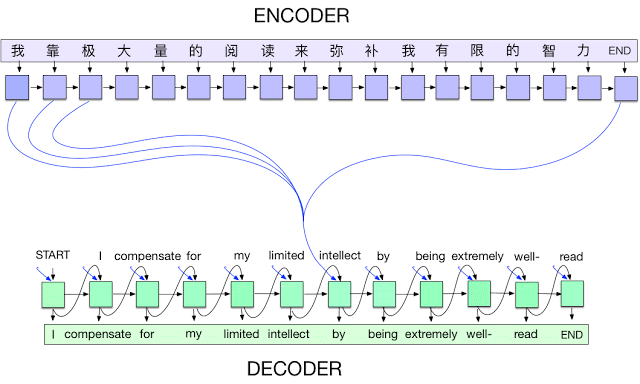
Sequence to Sequence Learning with Neural Networks,https://arxiv.org/abs/1409.3215 Neural Machine Translation by Jointly Learning to Align and Translate,https://arxiv.org/abs/1409.0473
用Pytorch搭建采用注意力的Seq2Seq,https://pytorch.org/tutorials/intermediate/seq2seq_translation_tutorial.html# 用TensorFlow搭建采用注意力的Seq2Seq,https://www.tensorflow.org/addons/tutorials/networks_seq2seq_nmt
Adam: A Method for Stochastic Optimization,https://arxiv.org/abs/1412.6980
用PyTorch搭建实现Adam优化器,https://d2l.ai/chapter_optimization/adam.html
PyTorch Adam实现,https://pytorch.org/docs/master/_modules/torch/optim/adam.html
TensorFlow Adam实现,https://github.com/tensorflow/tensorflow/blob/v2.2.0/tensorflow/python/keras/optimizer_v2/adam.py#L32-L281
Generative Adversarial Networks,https://arxiv.org/abs/1406.2661 Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks,https://arxiv.org/abs/1511.06434
用PyTorch搭建DCGAN,https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html 用TensorFlow搭建DCGAN,https://www.tensorflow.org/tutorials/generative/dcgan

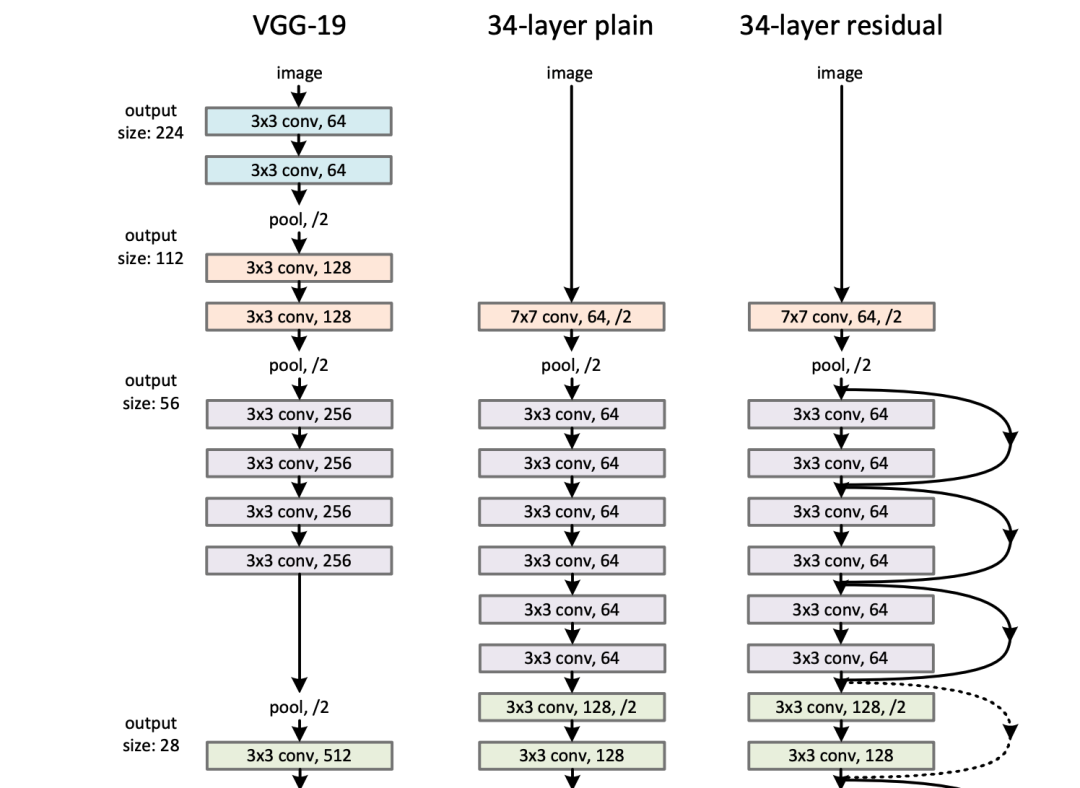
Deep Residual Learning for Image Recognition,https://arxiv.org/abs/1512.03385
用PyTorch搭建ResNet,https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py 用TensorFlow搭建ResNet,https://github.com/tensorflow/tensorflow/blob/v2.2.0/tensorflow/python/keras/applications/resnet.py
Attention is All You Need,https://arxiv.org/abs/1706.03762
PyTorch: 应用nn.Transformer和TorchText的序列到序列模型,https://pytorch.org/tutorials/beginner/transformer_tutorial.html Tensorflow: 用于语言理解的Transformer模型,https://www.tensorflow.org/tutorials/text/transformer HuggingFace的Transformers开发库,https://github.com/huggingface/transformers
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,https://arxiv.org/abs/1810.04805
具备Hugging Face的微调BERT,https://huggingface.co/transformers/training.html
本文不针对所提及的技术进行深入解析与代码示例。我们主要介绍技术的历史背景、相关论文链接和具体实现。建议有兴趣的读者能在不借助现有代码和高阶开发库的前提下将这些论文研究成果重新演示一遍,相信一定会有收获。 本文聚焦于深度学习的主流领域,包括视觉、自然语言、语音和强化学习/游戏等。 本文仅讨论运行效果出色的官方或半官方开放源代码实现。有些研究(比如Deep Mind的AlphaGo和OpenAI的Dota 2 AI)因为工程巨大、不容易被复制,所以在此没有被重点介绍。 同一个时间段往往发布了许多相似的技术方法。但由于本文的主要目标是帮助初学者了解涵盖多个领域的不同观点,所以在每一类方法里选取了一种技术作为重点。比方说,GAN模型有上百种,但如果你想学习GAN的整体概念,只需要学习任意一种GAN即可。
评论