
Groupby 分组后合并列内容 ~ 进一步优化
Python大咖谈
共 1066字,需浏览 3分钟
·
2021-04-30 08:36
Pandas 百问百答第 013 篇。
今天这篇文章是上一篇文章(Groupby 分组后,如何合并列里的内容?)的补充,重点推荐群友小小明,上篇文章发布后,他很快给了我三种更优化的解决方案,一种比一种简洁,有这么好的东西,呆鸟肯定不能私藏,现在分享给大家,代码见最下方说明。
今天主要讲小小明方案中的几个知识点,以及与呆鸟的方案的区别:
1. 列类型的转换
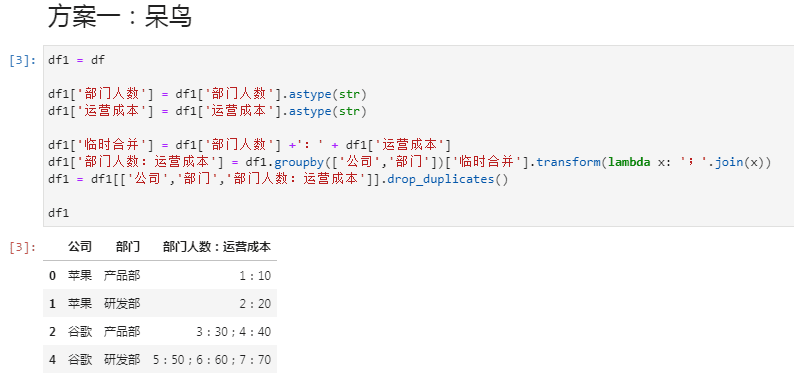
为了把部门人数与运营成本转为文本,呆鸟用了两行代码:
df1['部门人数'] = df1['部门人数'].astype(str)
df1['运营成本'] = df1['运营成本'].astype(str)
而小小明只用了一行:
df2 = df2.astype(str, copy=False)
要注意的是,如果 df 中还有其它类型的列,也会都转为文本类型,如果无所谓的话,这种方式更简洁。
2. 合并文本列
呆鸟用的是最传统的方式,字符串相加:
df1['临时合并'] = df1['部门人数'] +':' + df1['运营成本']小小明用的是 str 的 cat 方法,这种方式可以直接用在 apply 函数里
data.部门人数.str.cat(data.运营成本, sep=":"
3. 链式方法
小小明其中一种解决方案使用了链式函数:
(
df3.groupby(["公司", "部门"])
.apply(lambda data: data.部门人数.str.cat(data.运营成本, sep=":").str.cat(sep=";"))
.to_frame("部门人数:运营成本").reset_index()
)
看见括号了吧,括号内的写法就是链式方法,非常赞的一种方式,呆鸟虽然知道,但没咋用过,还要继续学以致用啊~
4. agg 函数
小小明还有一种方案,使用了 agg() 进行合并,代码如下:
df4.groupby(['公司','部门'],as_index=False)['部门人数:运营成本'].agg(';'.join)因为精力有限,所以这次只把最核心的知识点分享给大家,不过这几种方案,每种方案都很简洁,只有两三行代码,有点 pandas 知识的朋友就能看得懂。
感谢小小明的倾情奉献,如对呆鸟的文章有意见或建议,欢迎大家在 Python大咖谈 后台与我交流。
 方案一
方案一 方案二
方案二 方案三
方案三 方案四
方案四在 python大咖谈 后台输入分组合并优化,即可下载 ipynb 文件

评论