
NLP文本分类大杀器:PET范式
作者 | 周俊贤
整理 | NewBeeNLP
之前我们分享了NLP文本分类 落地实战五大利器!,今天我们以两篇论文为例,来看看Pattern Exploiting Training(PET)范式,可以用于半监督训练或无监督训练。
Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference
论文:《Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference Timo》[1] 项目地址:https://github.com/timoschick/pet
大家思考一个问题,BERT在预训练时学习到的知识或者说参数我们在fine-tunning的时候都有用到吗?
答案是不是的。大家看下图,BERT的预训练其中一个任务是MLM,就是去预测被【MASK】掉的token,采用的是拿bert的最后一个encoder(base版本,就是第12层的encoder的输出,也即下图左图蓝色框)作为输入,然后接全连接层,做一个全词表的softmax分类(这部分就是左图的红色框)。但在fine tuning的时候,我们是把MLM任务的全连接层抛弃掉,在最后一层encoder后接新的初始化层来做具体的下游任务。
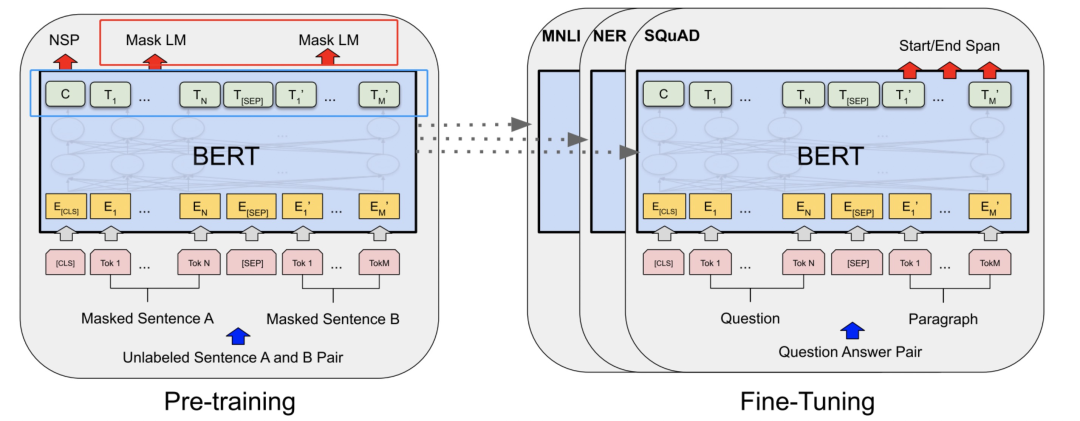
想一个问题,「能不能通过某些巧妙的设计,把MLM层学习到的参数也利用上?」 答案当然是可以的,请继续往下看。
现在举一个二分类的例子,输入一条汽车论坛的评论,输出这个评论是属于【积极】or【消极】。但问题是现在我每个类别只有10个labeled数据,1K条unlabeled数据。怎么训练model?
直接做有监督训练?样本量太少,会过拟合。应该优先采用半监督学习的方法,如UDA、MixText这种,而PET采用的是另外一种巧妙的设计思想。
现在通过改造输入,如下图,

一个样例是"保养贵,配件贵,小毛病多,还有烧机油风险"。定义一个「pattern」函数,把它转变成以下形式"保养贵,配件贵,小毛病多,还有烧机油风险。真__!"。
这里定义一个「verblizer」作为映射函数,把label【积极】映射为好,把label【消极】映射为差。然后model对下划线__部分进行预测。BERT预训练时MLM任务是预测整个词表,而这里把词表限定在{好,差},cross entropy交叉熵损失训练模型。预测时,假如预测出好,即这个样例预测label就为积极,预测好差,这个样例就是消极。
这样做的好处是,「BERT预训练时的MLM层的参数能利用上」。而且,「即使model没有进行fine tunning,这个model其实就会含有一定的准确率」!想想,根据语义来说,没可能预测出 "保养贵,配件贵,小毛病多,还有烧机油风险。真好!" 比 "保养贵,配件贵,小毛病多,还有烧机油风险。真差!" 的概率还大吧!因为前面一句很明显是语义矛盾的。
上面定义的Pattern和verblizer,就是一个PVP(pattern-verbalizer pairs)。
Auxilliary Language Modeling
由于现在是用MLM做分类任务,所以可以引入无标注数据一起训练!
举个简单的例子,下图样例1是labeled数据,我们利用pattern把它改写后,对__部分做完形填空预测(即MLM任务)。样例2是一个unlabeled数据,我们就不对__部分做预测,而是对被【MASK】做预测。这里的【MASK】可以采用BERT的方法,随机对句子的15%token进行【MASK】。

这样做的好处是,能让model更适应于当前的任务,有点像「在预训练模型上继续根据任务的domain和task继续做预训练,然后再做fine-tunning呢?」 详细的可以看我写的这篇博文。
Combining PVPs
引入一个问题,「怎么评价我们的pattern定义得好不好?」
举个例子,如下图,我们可以造两个pattern,又可以造两个verblizer。这样,图中所示,其实一共有4个PVP。我们怎么衡量哪一个PVP训练完后在测试集上的效果最好?

答案是我们也不知道,因为「我们不能站在上帝视角从一开头就选出最佳的PVP,同样由于是小样本学习,也没有足够的验证集让我们挑选最佳的PVP」。既然如此,解决方式就是「知识蒸馏」。
具体的,我们用20个labeled数据训练4个PVP模型,然后拿这四个PVP模型对1K条unlabeled数据进行预测,预测的结果用下式进行平均。
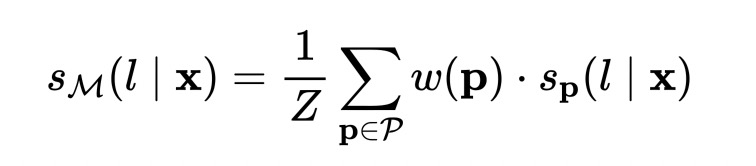
这里的 保持概率和为1, 就是单个PVP模型对样本预测的概率分布, 就是PVP的权重。有uniform和weighted两种方式,uniform就是所有PVP的权重都为1,weighted就是把每个PVP的权重设置为它们在训练集上的准确率。最后还要对上式进行temperature=2的软化。
这就是在做知识的蒸馏。「何谓知识的蒸馏?」 经过这样处理后,噪声减少了,利用多个PVP平均的思想把某些本来单个PVP预测偏差比较大的进行平均后修正。
这样子,利用训练好的PVPs所有1K条unlabeled数据打上soft label,再用这1K条打上软标签的数据进行传统的有监督训练,训练完的model应用于下游任务的model。
注意哦,这里就可以用「轻量的模型」来做fine tuning了哦,因为从20条labeled数据扩充到1K条有带有soft label的数据,labeled数据量大大增加,这时候轻量级的模型也能取得不错的结果,而且轻量模型对轻量部署、高并发等场景更加友好。
下图就是所有的流程,再总结一下步骤就是
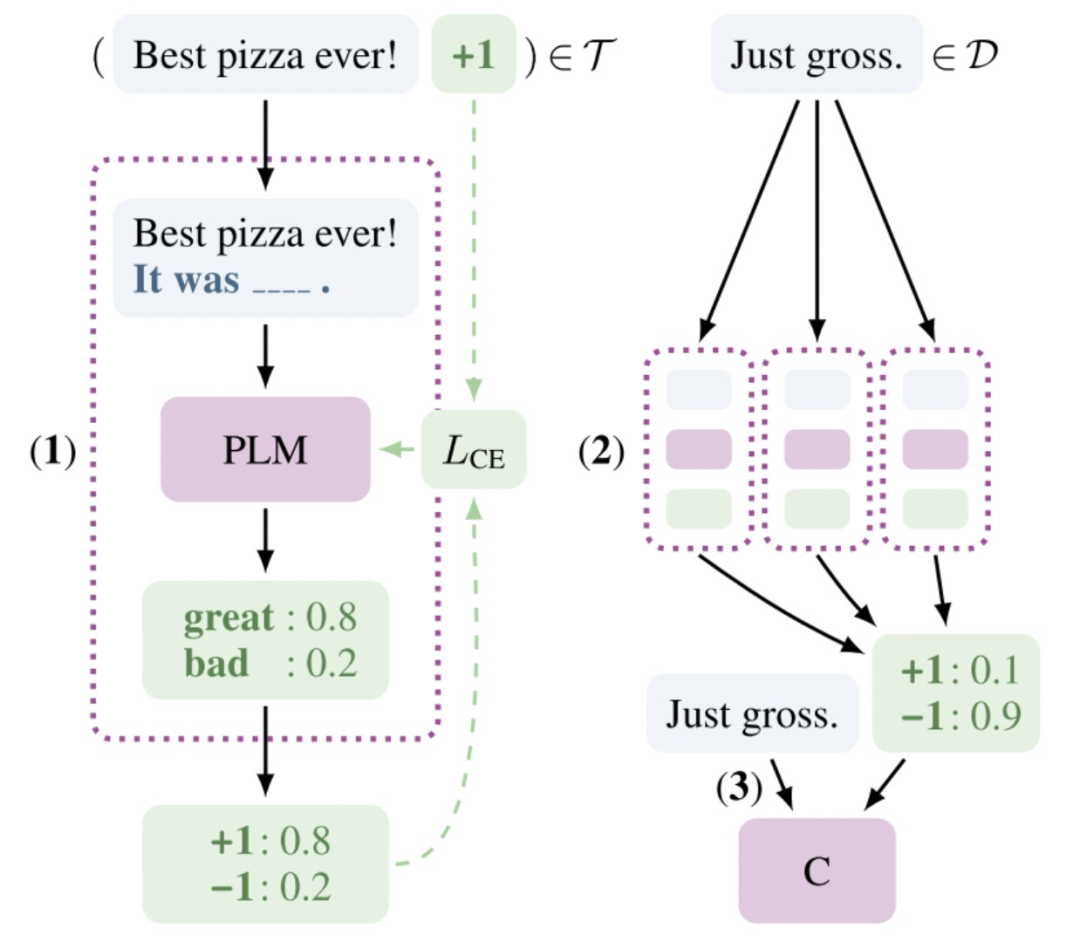
第一步:先定义PVPs,然后对每个PVP用labeled据进行单独的训练,该步可以加入上面提到的Auxiliary Language Modeling一起训练; 第二步:用训练好的PVPs,对unlabled数据进行预测,并知识蒸馏,得到大量的soft label; 第三步:用第二步得到的带有soft label的data,用传统的fine tuning方法训练model。
IPET
在每个PVP训练的过程中,互相之间是没有耦合的,就是没有互相交换信息,IPET的意思就是想通过迭代,不断扩充上面训练PVP的数据集。
这里简单举个例子,现在有20个labeled数据,1K个unlabeled数据,定义5个PVP,第一轮,利用20个labeled数据分别训练PVP,第二轮,用第2~4个PVP来预测这1K unlabeled数据,然后选一些模型预测概率比较高的加入到第一个PVP的训练集上,同样用第1、3、4、5个PVP来训练这1K条,然后也将这部分加入到第2个PVP的训练集中,然后再训练一轮,训练后,重复,这样每一轮每个PVP的训练样本不断增多,而且PVP之间的信息也发生了交互。
实验
分析
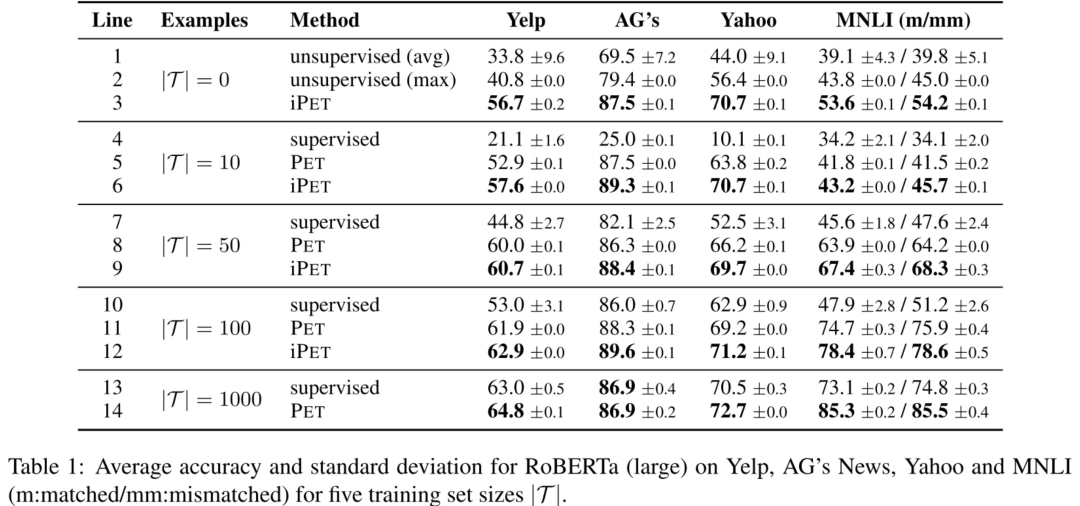
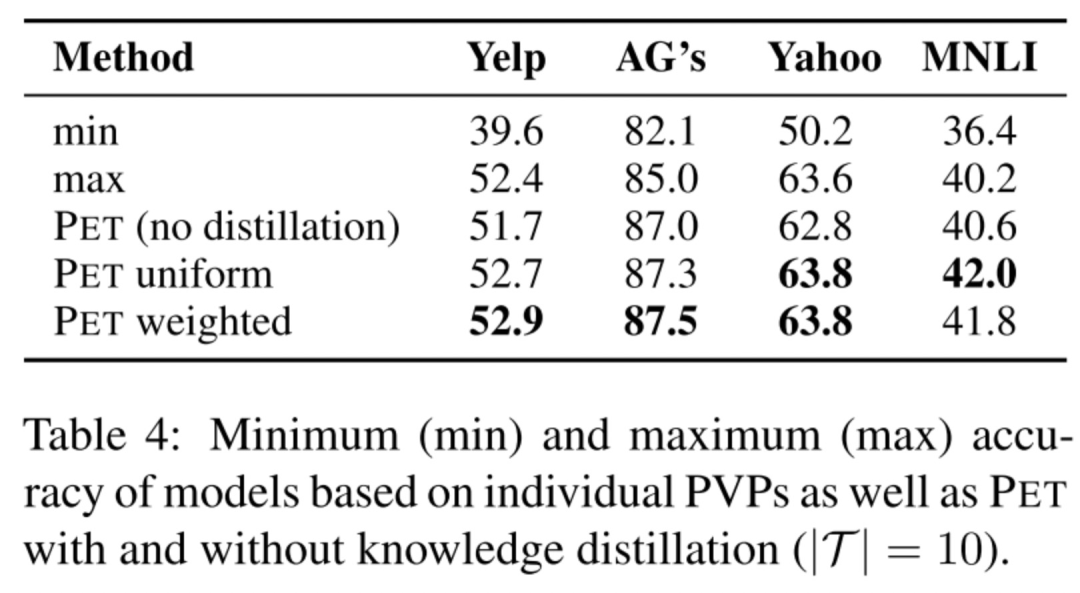
作者发现不同PVP之间可能有很大的性能差别,如下图min就是最差的PVP,max就是最好的PVP,可以观察到它们之间的差别就很大。但是又不能站在上帝视角从一开始就选择最好的PVP,所以办法就是做commind PVPs,即上面所提到的知识蒸馏,而且发现蒸馏后会比采用单个最好的PVP效果还要好,并且发现uniform和weighted两个方法效果差不多。
labeled数据越少,auxiliary task的提升效果越明显。

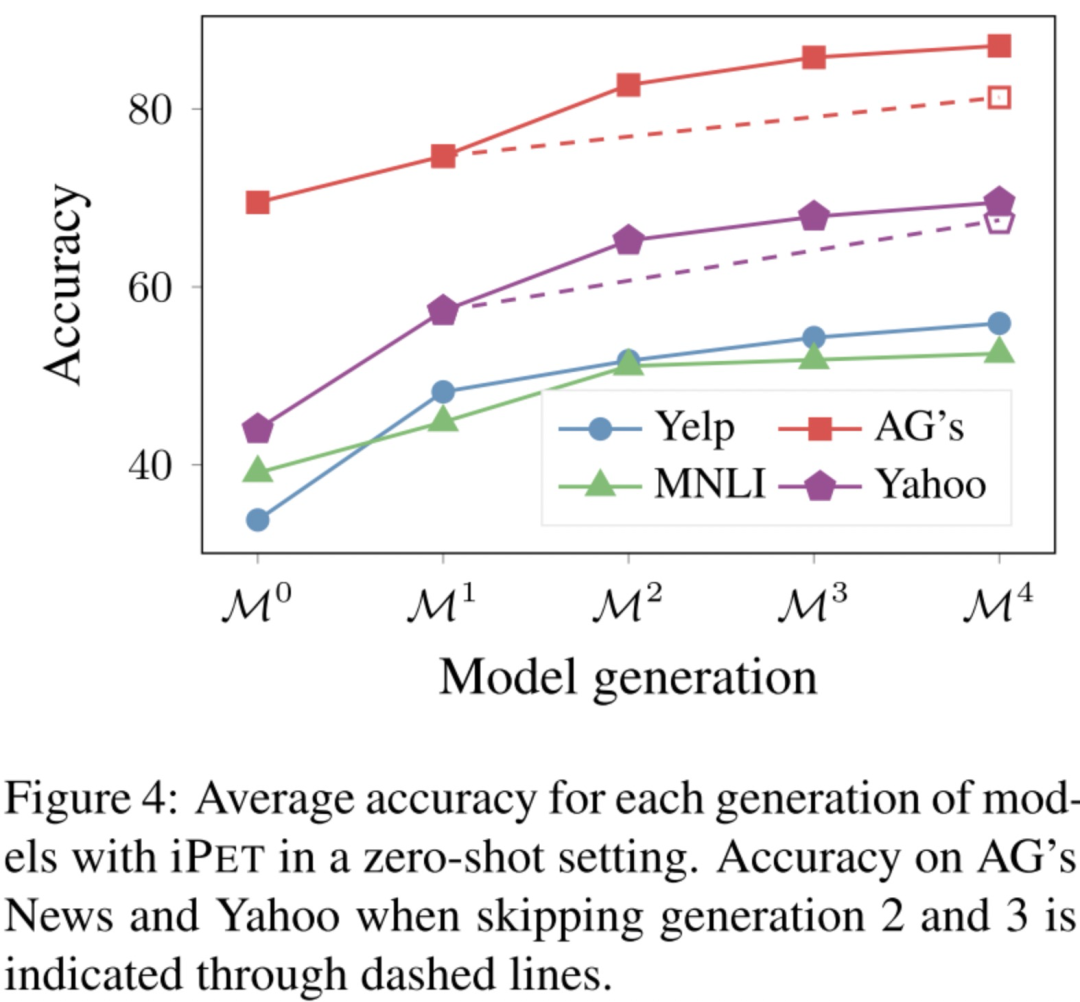
iPET的效果,因为iPET是迭代多轮,每一轮每个PVP的训练集都会增大,从图可以看到每一轮的模型效果都是越来越好的。
In-Domain Pretraining
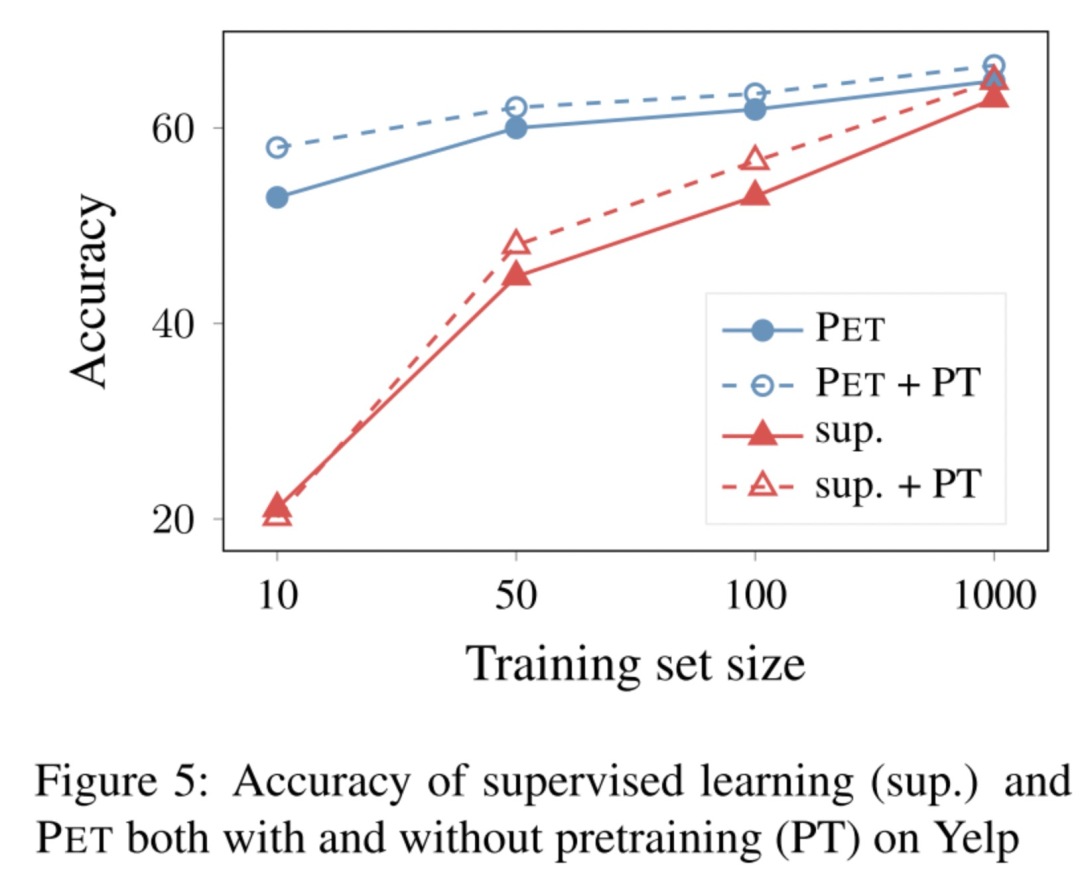
这里讨论了一个问题:PET效果比有监督训练好,是不是因为PET在大量无标签上打上软标签,扩大了有标签数据集?然后作者做了一个实验,有监督训练时,先在所有数据集上进行继续预训练(这一步作者认为相当于把无标签数据也加进来了),然后再fine funing。实验结果表明,即使这样,有监督效果也离PET有一定距离。
不过这里想略微吐槽:还可以这样来做比较的?感觉都不太公平hh。
It's Not Just Size That Matters:Small Language Models Are Also Few-Shot Learners
论文:《It's Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners》[2] 项目地址:https://github.com/timoschick/pet
这篇论文是上篇论文的延伸,其实没有太多新的工作,主要是下面提到的处理多个token的mask,这篇论文主要PK GPT3,不断diss GPT3有多少的不环保hh。
PET with Multiple Masks
PET要定义pattern和verblizer,还拿那汽车评论那个场景举例,我们能不能定义一个verbilzer,它把不同label映射到长度不一的token,如

因为verbilzer把标签映射到长度不一致的token,那我们究竟定义长度为多少的下划线_,来让model进行完形填空。答案是用最长的那个,例如这里最长的是"不好",长度为2,所以就挖空两个下划线来让模型做完形填空预测。
做Inference时,
=第一个下划线_模型预测到token为好的概率;
就麻烦一些,先让模型对两个下划线,进行预测,看是第一个下划线预测token为不,还是第二个下划线预测token为好的概率高一些,把高的那个token先填上去,再重新预测剩下的。举个例子,假如模型预测第一个下划线token为不的概率是0.5,第二个下划线token为好的概率为0.4,即先把不填上第一个下划线,然后再用模型重新预测第二个token为好的概率,假如为0.8,即 =0.5*0.8=0.4。
做train时,就不考虑这么细致了,具体的,取上面的例子为例,
=第一个下划线_,模型预测到token为好的概率,跟inference是一样的; =0.5*0.4=0.2,这里就不分成两步,一步KO,目的是一次前向计算就算完,避免训练过慢。
最后,采用的损失函数也跟第一篇的不一样,这里用的是hinge loss,详细的请看论文。
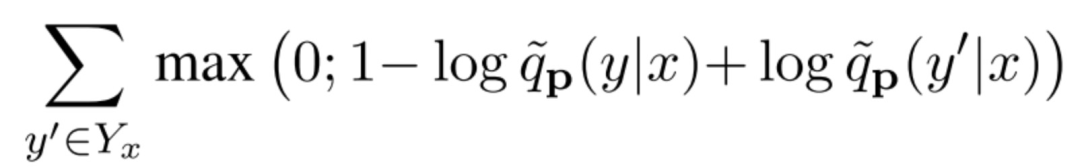
分析
再次强调Combining PVPs做知识蒸馏的重要性,因为当我们仅采用单个pattern的时候,根本不知道它的效果如何,最好的做法就是定义多个PVP,然后做平均做知识蒸馏。
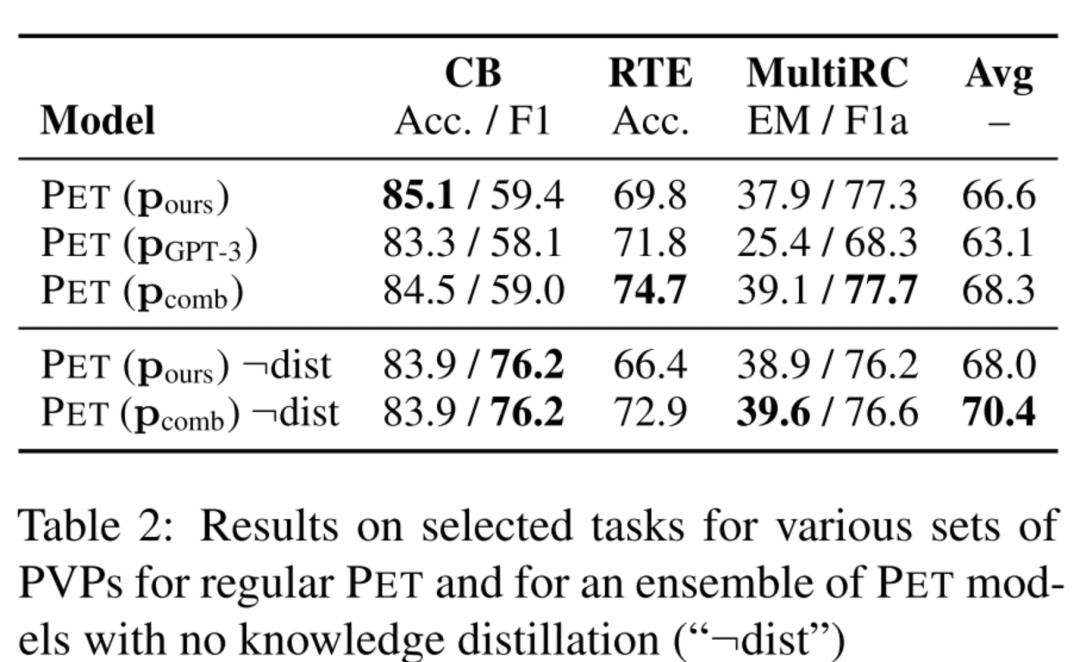
还是下面这幅图,这里讨论了unlabeled数据的利用。
在PET利用到unlabeled数据的有三个地方:
第一处:PET的第二步,用PVPs对unlabeled数据进行知识蒸馏,给数据打上soft label,然后第三步利用这些软标签训练一个模型; 第二处:PET的第一步,假如用的是iPET的话,每一个generation都会把部分的无标签数据打上标签,加入到PVP的训练集; 第三处:PET的第一步,假如采用的是Auxiliary Language Modelling辅助训练,也会引入无标签数据。
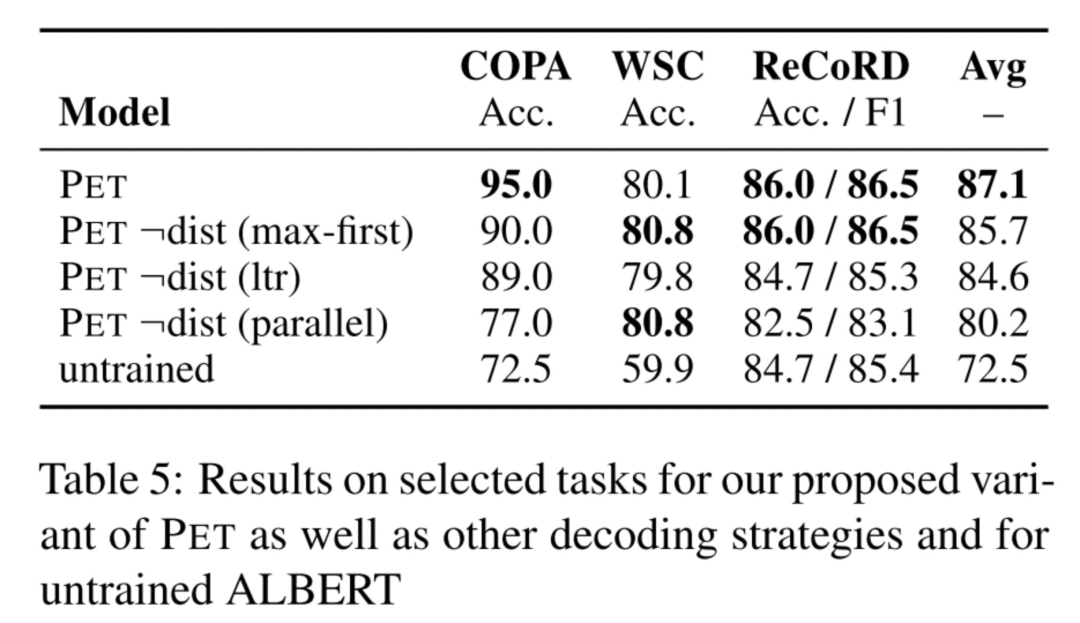
首先,讨论上面的第一点,究竟能不能直接用PET训练的第一步的PVPs来做预测,这样就不用给unlabeled数据打软标签了(因为虽然说unlabeled数据比labled数据容易获得,但某些场景下unlabeled数据也有可能是拿不到的),答案是可以的,大家看下表的倒数两列,发现不用PET训练的第二、第三步,直接采用第一步训练好的PVPs来做下游应用的预测,效果也是OK的。「只不过,这样做的话,你应用于下游任务的时候就是一堆PVP模型,而不是单一个模型了,这样对轻量部署不是很友好」。

还讨论了上面的第二处,发现iPET训练过程中,每一个generation从unlabeled数据中挑选部分加入到PVP的训练集,能让PVP收敛更快,减少不稳定性。
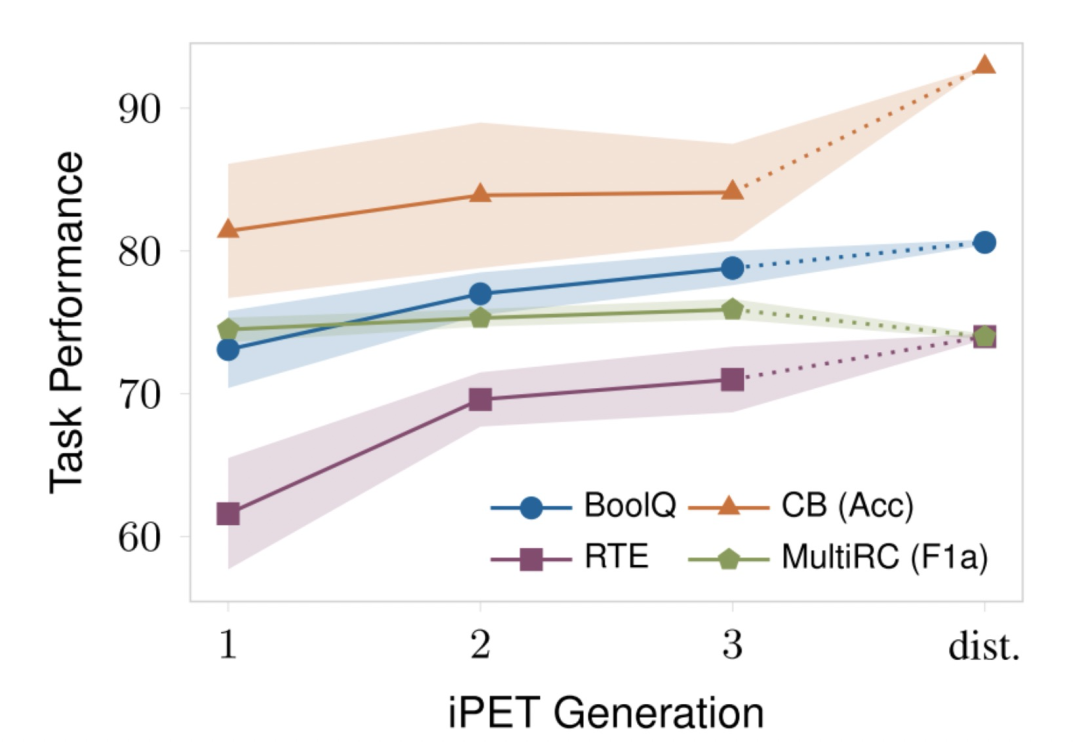
Labeled Data Usage
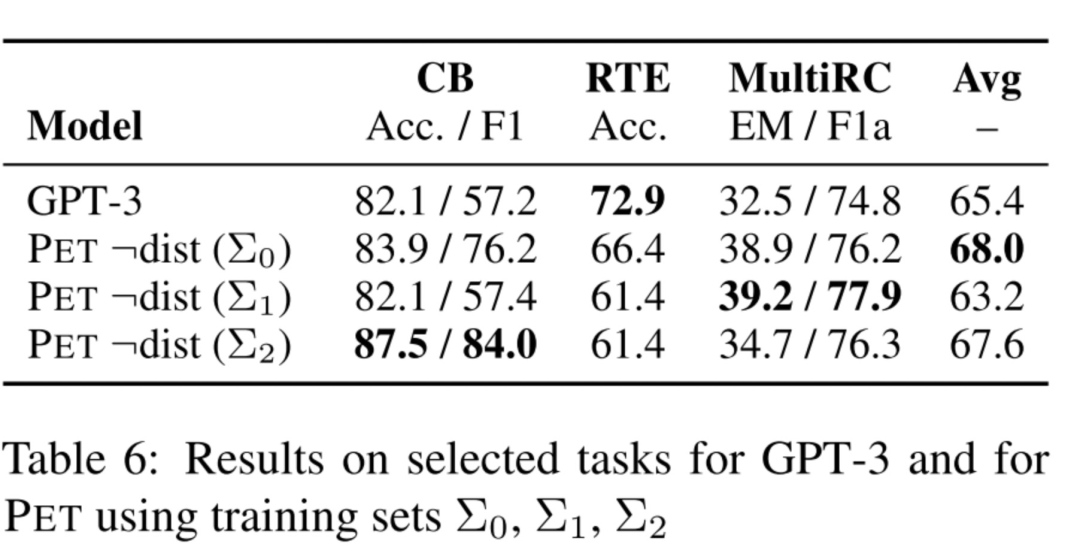
这里研究了labeled数据对PET的影响,
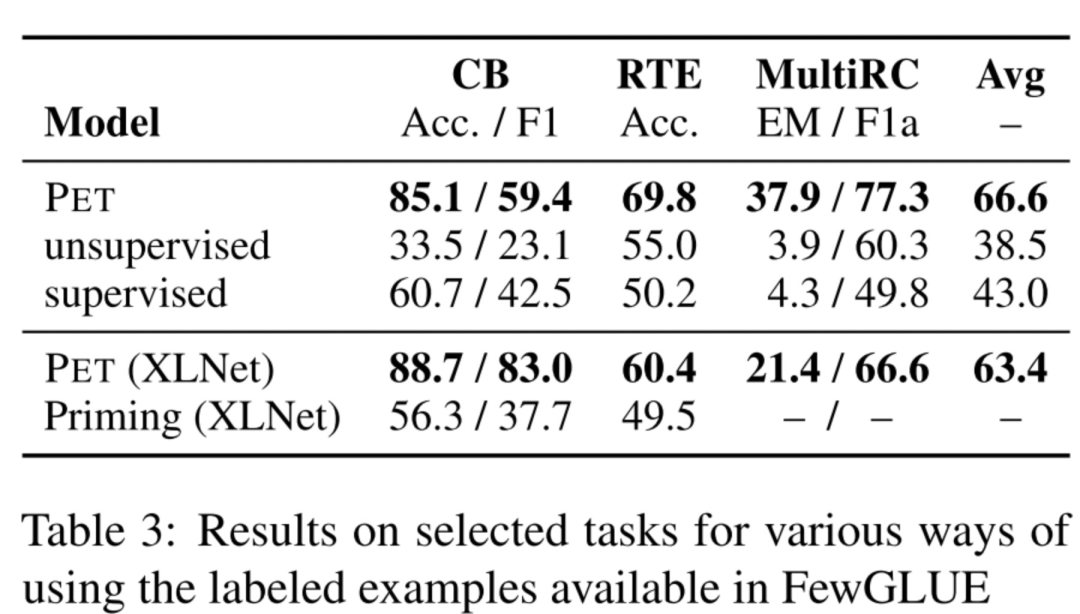
Model Type
不同预训练模型的影响,像BERT这种双向的语言模型会比GPT这种单向的要好,因为假如采用的是单向的语言模型,那么pattern的下划线__部分只能放在句子末尾进行预测。
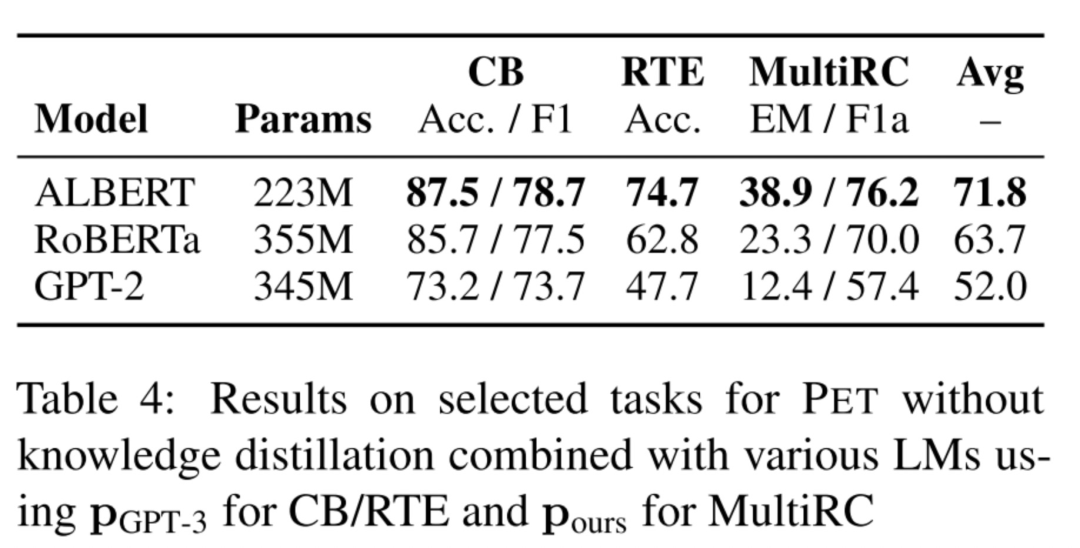
PET with Multiple Masks
讨论了上面提到的处理多个mask token的效果。
Training Examples
由于是小样本学习,一开始labeled数据对PET最后的效果影响很大。
总结
个人觉得PET的思想非常的优雅,主要利用把分类任务转换成完形填空任务,让模型利用上预训练时的MLM信息,让大家重新审视MLM任务的重要性。
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定要备注信息才能通过)
本文参考资料
Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference Timo: https://arxiv.org/abs/2001.07676
[2]It's Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners》: https://arxiv.org/abs/2009.07118
- END -

2021-07-19
2021-07-30
2021-08-06

2021-08-26
