
自己动手写一个GDB|设置断点(原理篇)
在上一篇文章《自己动手写一个GDB|基础功能》中,我们介绍了怎么使用 ptrace() 系统调用来实现一个简单进程追踪程序,本文主要介绍怎么实现断点设置功能。
什么是断点
当使用 GDB 调试程序时,如果想在程序执行到某个位置(某一行代码)时停止运行,我们可以通过在此处位置设置一个 断点 来实现。
当程序执行到断点的位置时,会停止运行。这时,我们可以对进程进行调试,比如打印当前进程的堆栈信息或者打印变量的值等。如下图所示:
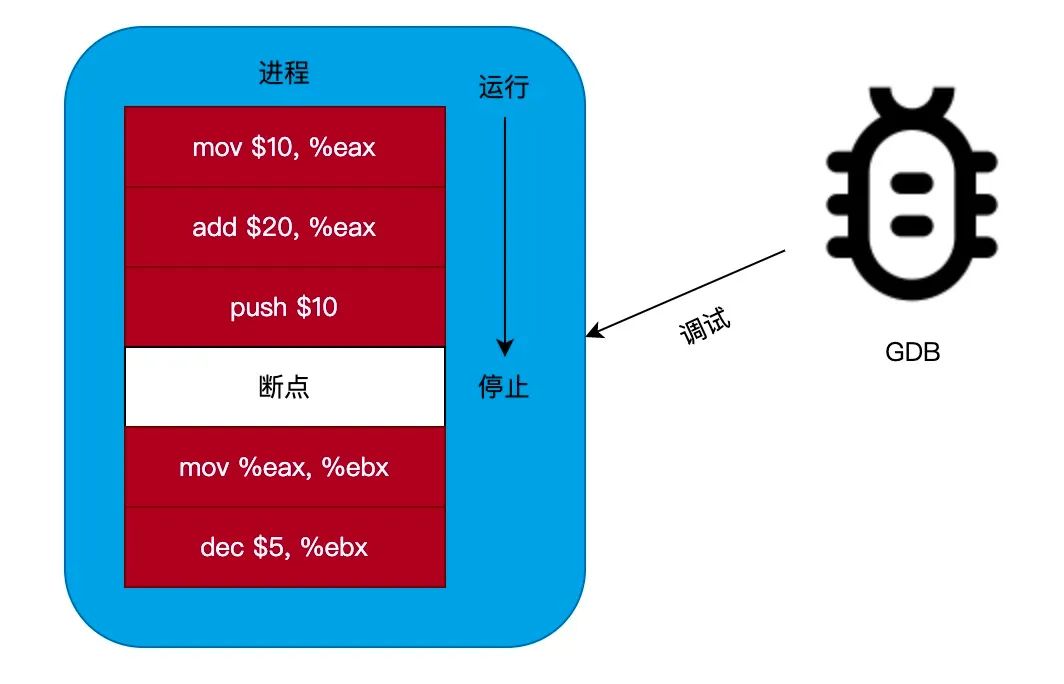
断点原理
要说明 断点 的原理,我们首先需要了解下什么是 中断。本公众号以前也写过很多关于 中断 的文章,例如:《一文看懂|Linux中断处理》。
想深入了解中断原理的,可以看看上文。下面简单介绍一下什么是中断:
中断是为了解决外部设备完成某些工作后通知CPU的一种机制(譬如硬盘完成读写操作后通过中断告知CPU已经完成)。从物理学的角度看,中断是一种电信号,由硬件设备产生,并直接送入中断控制器(如 8259A)的输入引脚上,然后再由中断控制器向处理器发送相应的信号。处理器一经检测到该信号,便中断自己当前正在处理的工作,转而去处理中断。此后,处理器会通知 OS 已经产生中断。这样,OS 就可以对这个中断进行适当的处理。不同的设备对应的中断不同,而每个中断都通过一个唯一的数字标识,这些值通常被称为中断请求线。
如果进程在运行的过程中,发生了中断,CPU 将会停止运行当前进程,转而执行内核设置好的 中断服务例程。如下图所示:
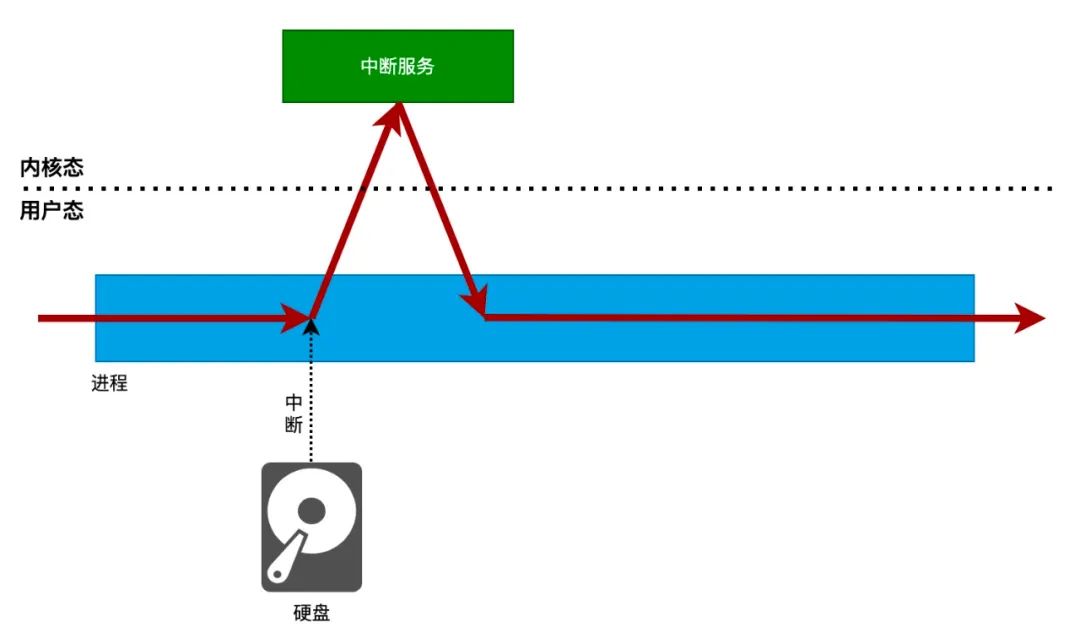
软中断
大概了解中断的原理后,接下来我们将会介绍 断点 会用到的 软中断 功能。软中断跟上面介绍的中断(也称为 硬中断)类似,不过软中断并不是由外部设备产生,而是有特殊的指令触发,这个特殊的指令称为 int3。
int3 是一个单字节的操作码(十六进制为 0xcc)。当 CPU 执行到 int3 指令时,将会停止运行当前进程,转而执行内核定义好的 int3 中断处理例程:do_int3()。
do_int3() 例程会向当前进程发送一个 SIGTRAP 信号,当进程接收到 SIGTRAP 信号后,CPU 将会停止执行当前进程。这时调试进程(GDB)就可以对进程进行调试,如:打印变量的值、打印堆栈信息等。
设置断点
从上面的介绍可知,设置断点的目的是让进程停止运行,从而调试进程(GDB)就可以对其进行调试。
接下来,我们将会介绍如何设置一个断点。
我们知道,当 CPU 执行到 int3 指令(0xcc)时会停止运行当前进程。所以,我们只需要在要进行设置断点的位置改为 int3 指令即可。如下图所示:
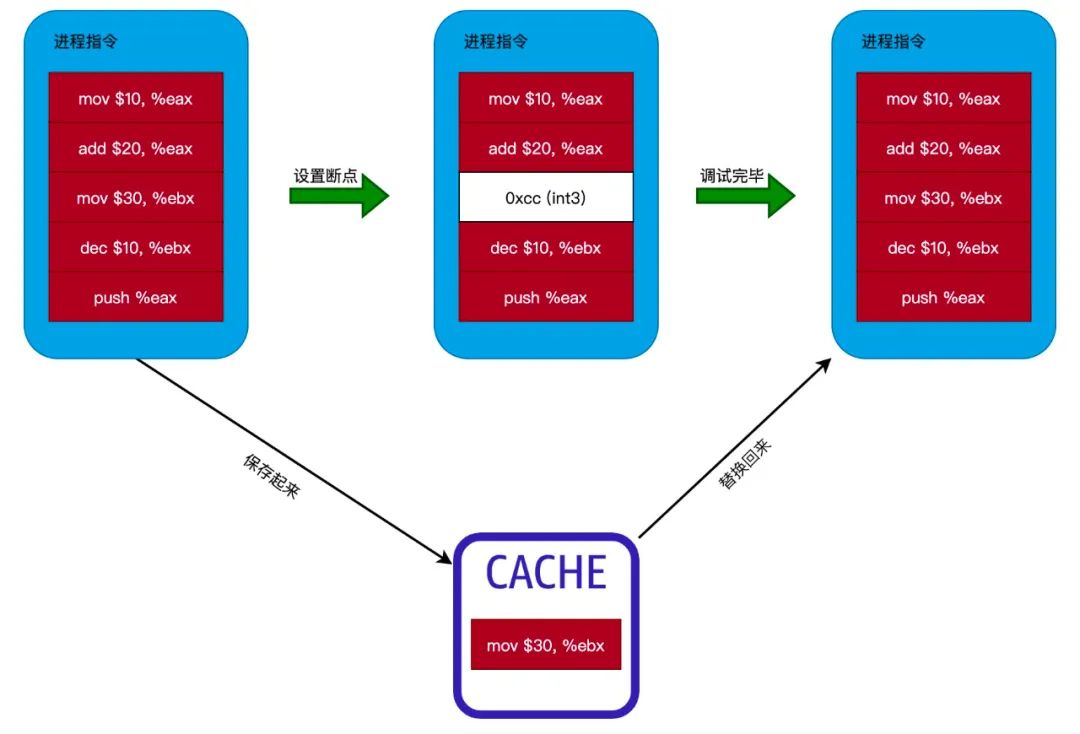
从上图可以看出,设置断点时,只需要在要设置断点的位置修改为 int3 指令即可。但我们还需要保存原来被替换的指令,因为调试完毕后,我们还需要把 int3 指令修改为原来的指令,这样程序才能正常运行。
断点实现
既然,我们已经知道了断点的原理。那么,现在是时候介绍怎么实现断点功能了。
我们来说说设置断点的步骤吧:
第一步:找到要设置断点的地址。第二步:保存此地址处的数据(为了调试完能够恢复原来的指令)。第三步:我们把此地址处的指令替换成 int3 指令。第四步:让被调试的进程继续运行,直到执行到 int3 指令(也就是断点)。此时,被调试进程会停止运行,调试进程(GDB)就可以对进程进行调试。第五步:调试完毕后,恢复断点处原来的指令,并且让 IP 寄存器回退一个字节(因为断点处原来的代码还没执行)。第六步:把被调试进程设置为单步调试模式,这是因为要在执行完断点处原来的指令后,重新设置断点(为什么?这是因为在一些循环语句中,可能需要重新执行原来的断点)。
知道断点实现的步骤后,我们可以开始编写代码了。
我们定义一个结构体 breakpoint_context 用于保存断点被设置前的信息:
struct breakpoint_context
{
void *addr; // 设置断点的地址
long data; // 断点原来的数据
};
围绕 breakpoint_context 结构,我们定义几个辅助函数,分别是:
create_breakpoint():用于创建一个断点。enable_breakpoint():用于启用断点。disable_breakpoint():用于禁用断点。free_breakpoint():用于释放断点。
现在我们来实现这几个辅助函数。
1. 创建断点
首先,我们来实现用于创建一个断点的辅助函数 create_breakpoint():
breakpoint_context *create_breakpoint(void *addr)
{
breakpoint_context *ctx = malloc(sizeof(*ctx));
if (ctx) {
ctx->addr = addr;
ctx->data = NULL;
}
return ctx;
}
create_breakpoint() 函数需要提供一个类型为 void * 的参数,表示要设置的断点地址。
create_breakpoint() 函数的实现比较简单,首先调用 malloc() 函数申请一个 breakpoint_context 结构,然后把 addr 字段设置为断点的地址,并且把 data 字段设置为 NULL。
2. 启用断点
启用断点的原理是:首先读取断点处的数据,并且保存到 breakpoint_context 结构的 data 字段中。然后将断点处的指令设置为 int3 指令。
获取某个内存地址处的数据可以使用 ptrace(PTRACE_PEEKTEXT,...) 函数来实现,如下所示:
long data = ptrace(PTRACE_PEEKTEXT, pid, address, 0);
在上面代码中,pid 参数指定了目标进程的PID,而 address 参数指定了要获取此内存地址处的数据。
而要将某内存地址处设置为制定的值,可以使用 ptrace(PTRACE_POKETEXT,...) 函数来实现,如下所示:
ptrace(PTRACE_POKETEXT, pid, address, data);
在上面代码中,pid 参数指定了目标进程的PID,而 address 参数指定了要将此内存地址处的值设置为 data。
有了上面的基础,现在我们可以来编写 enable_breakpoint() 函数的代码了:
void enable_breakpoint(pid_t pid, breakpoint_context *ctx)
{
// 1. 获取断点处的数据, 并且保存到 breakpoint_context 结构的 data 字段中
ctx->data = ptrace(PTRACE_PEEKTEXT, pid, ctx->addr, 0);
// 2. 把断点处的值设置为 int3 指令(0xCC)
ptrace(PTRACE_POKETEXT, pid, ctx->addr, (ctx->data & 0xFFFFFF00) | 0xCC);
}
enable_breakpoint() 函数的原理,上面已经详细介绍过了。
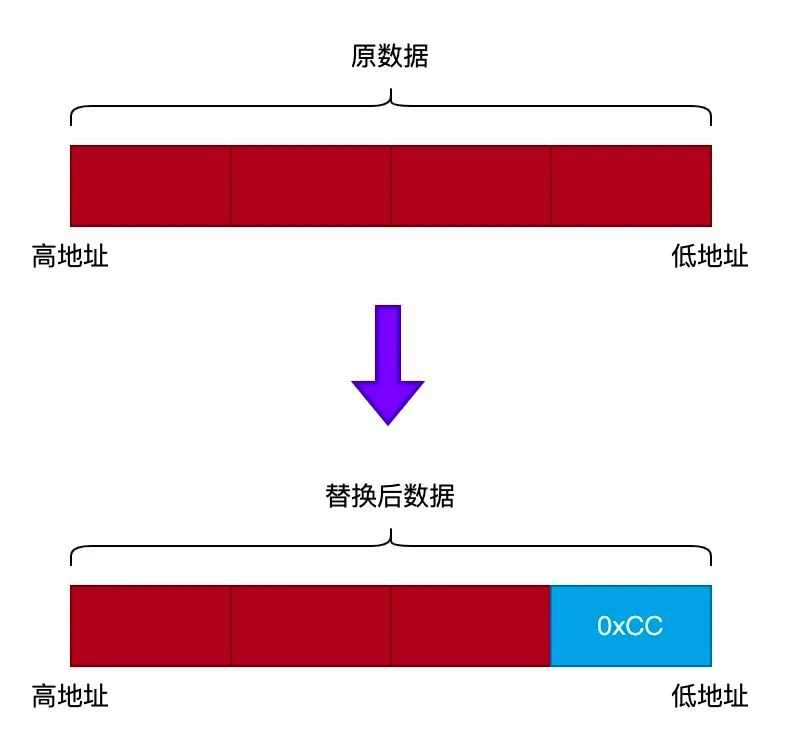
不过有一点我们需要注意的,就是使用 ptrace() 函数一次只能获取和设置一个 4 字节大小的长整型数据。但是 int3 指令是一个单子节指令,所以设置断点时,需要对设置的数据进行处理。如下图所示:
3. 禁用断点
禁用断点的原理与启用断点刚好相反,就是把断点处的 int3 指令替换成原来的指令,原理如下图所示:
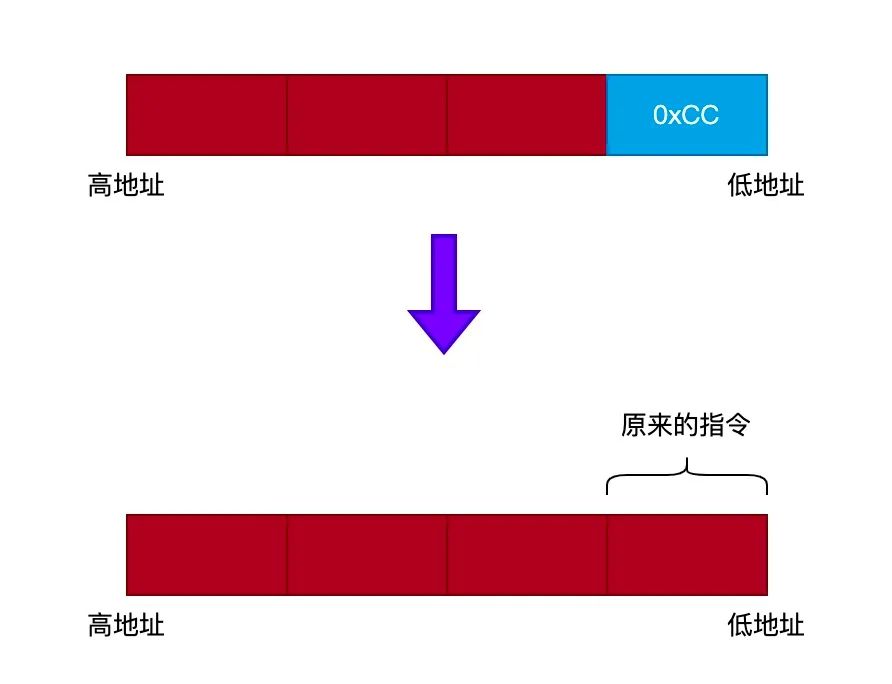
由于 breakpoint_context 结构的 data 字段保存了断点处原来的指令,所以我们只需要把断点处的指令替换成 data 字段的数据即可,代码如下:
void disable_breakpoint(pid_t pid, breakpoint_context *ctx)
{
long data = ptrace(PTRACE_PEEKTEXT, pid, ctx->addr, 0);
ptrace(PTRACE_POKETEXT, pid, ctx->addr, (data & 0xFFFFFF00) | (ctx->data & 0xFF));
}
4. 释放断点
释放断点的实现就非常简单了,只需要调用 free() 函数把 breakpoint_context 结构占用的内存释放掉即可,代码如下:
void free_breakpoint(breakpoint_context *ctx)
{
free(ctx);
}
总结
本来想一口气把断点的原理和实现都在本文写完的,但写着写着发现篇幅有点长。所以,决定把断点分为原理篇和实现篇。
本文是断点设置的原理篇,下一篇文章中,我们将会介绍如何使用上面介绍的知识点和辅助函数来实现我们的断点设置功能,敬请期待。