
文字生万物,AI极简史
 大数据文摘授权转载自澎湃美数课
大数据文摘授权转载自澎湃美数课
编辑:舒怡尔
设计:张泽红
哈罗德·科恩花了 42 年把 AARON 铸成“另一半自己”。它是一段被画家造出来的计算机程序,或许也可以叫做 AI 系统。先是花了 20 年学会黑白简笔画,1995 年,它第一次表演上色,以一个庞大的机器模样(长 2.4 米,宽 1.8 米)。它先用机械臂上的钢笔勾勒线条,然后在调色板上混合颜料,创造出自定义的颜色,再使用笔刷进行涂抹,就好像在机床上织布。
2016 年,科恩去世,AARON 也停止了呼吸。
他们都没见到《太空歌剧院》的诞生,这幅 AI 作的画在艺术比赛上拿了一等奖。2022 年,使唤 AI 画画变得格外简单——只要会打字就行。AI 画画也不再是一笔一笔地勾勒线条、涂抹颜色,而是像一台反应有点迟缓的彩色电视机,从一片灰白雪花噪声中慢慢地腾出画面。
 AARON创作的首幅上色作品,1995
AARON创作的首幅上色作品,1995
 《太空歌剧院》,使用AI工具Midjourney创作,2022
《太空歌剧院》,使用AI工具Midjourney创作,2022
不过,恰好是在科恩去世的 2016 年,AI 画画所依托的“文本生成图像”(text to image)技术在深度学习领域迈出了第一步,小小的一步——生成比豆腐块还小的极模糊的图像,仔细一看,还很拙劣。比方说让它画一只站在草地上的羊,它就在绿色背景中放置一个灰色的不明形状的物体,就像一块污渍。
 Generative Adversarial text to image synthesis, 2016
Generative Adversarial text to image synthesis, 2016
这些小豆腐块儿的光芒还是太微弱了。
但 AI 的步速很快。2017 年,基于 GAN 的伪造人脸已经可以以假乱真。
2020年,扩散模型(Diffusion Model) 降低了图像生成模型的训练难度,还能生成比 GAN 更多元的图像。2021 年,OpenAI 推出了 CLIP,它学到了文本和图像之间的对应关系。2022 年,AI 画家诞生,不过没想到,这不是 2022 年最重要的 AI 新闻。
还是先让我们回到 2016 年吧。这一年最大的新闻是,谷歌旗下的人工智能公司 DeepMind 创造的 AlphaGO 以 4:1 击败了韩国传奇棋手李世石,人们仿佛看到原本只存在于科幻小说的强大的人工智能,在棋盘上空活了过来。
同一年,或许普通人没有太过在意,一家成立仅有半年的新公司 OpenAI(尽管它出身煊赫,是由特斯拉的创始人马斯克联合其他硅谷明星投资人注入 10 亿美金创立的非营利机构)宣布,他们的长远目标之一,是开发对人类友好的通用人工智能系统,简单来说,这个系统能像人一样推理和反应从而让人以为它是人。作为一个非营利组织,该公司的第一份声明称,公司要“为所有人而非股东创造价值”。
技术在往前发展。2017 年诞生了 Transformer,如今看来,那是个极其重要的时刻。
这个和变形金刚同名的小玩意儿是由谷歌团队创造的一种全新的模型结构,同样威力巨大。它能更好的理解上下文,更重要的是,此前 NLP (自然语言处理)的主流模型 RNN 天生是个时序结构,处理起句子来就好像在只开了一个窗口的银行排长队,处理完上一个词才能处理下一个,而 Transformer 对句子里的每个词可以同时进行处理,也就是所谓的并行化。它为后来的暴力出奇迹的大模型时代提供了可能性。
此前深度学习的主流仍是使用有标签的数据进行训练,效果好,但代价高昂。比如说一句话的情绪是积极还是消极?为了打上准确的标签,研究者必须付钱请人来做。于是数据集的规模一直没法大幅度提升。既然 Transformer 能很好地消化上下文的内容,2018 年,GPT、BERT 开始利用大规模的无标签的数据对模型进行预训练,在这个阶段,它们或是给定一串词让模型预测下一个词是什么,或是干脆在句子中间挖掉一个词,让模型重新给填上,如此这般,把价格更为低廉的无标签的文字引入了模型的训练。
OpenAI 的创始人之一 Sam Altman 接受《纽约客》采访时曾说:“成为一台机器有一定的优势。人类被输入-输出率所限制,每秒只学习 2 比特,丢失大量数据。而对机器而言,我们看起来肯定像是被减速的鲸歌。” BERT 用了 3300M 的文字来做预训练,这些文字来自书本和维基百科,质量较高,即使对人来说可能要看上几年时间,对机器来讲,仍算克制。
和 Open AI 推出的初代 GPT 相比,谷歌研发的 BERT 是更风光的那个,因为经过有标签的数据微调之后,它的表现更佳。BERT 很快 被用来改进谷歌的搜索引擎,被谷歌描述为“搜索历史上最大的飞跃”。
模型更大,效果就会更好,用于取得突破性成果的计算资源每 3、4 个月翻一番。OpenAI 需要足够的资本来匹配或超过这种指数级增长,“在经济上维持一个非营利组织是站不住脚的”。2019 年 3 月,OpenAI 通过设立一个利润上限(投资者的回报率不得超过 100 倍)掀掉了 “非营利组织”的帽子。不久之后,它宣布了微软的 10 亿美金投资。从此也背上了一定的商业化压力。
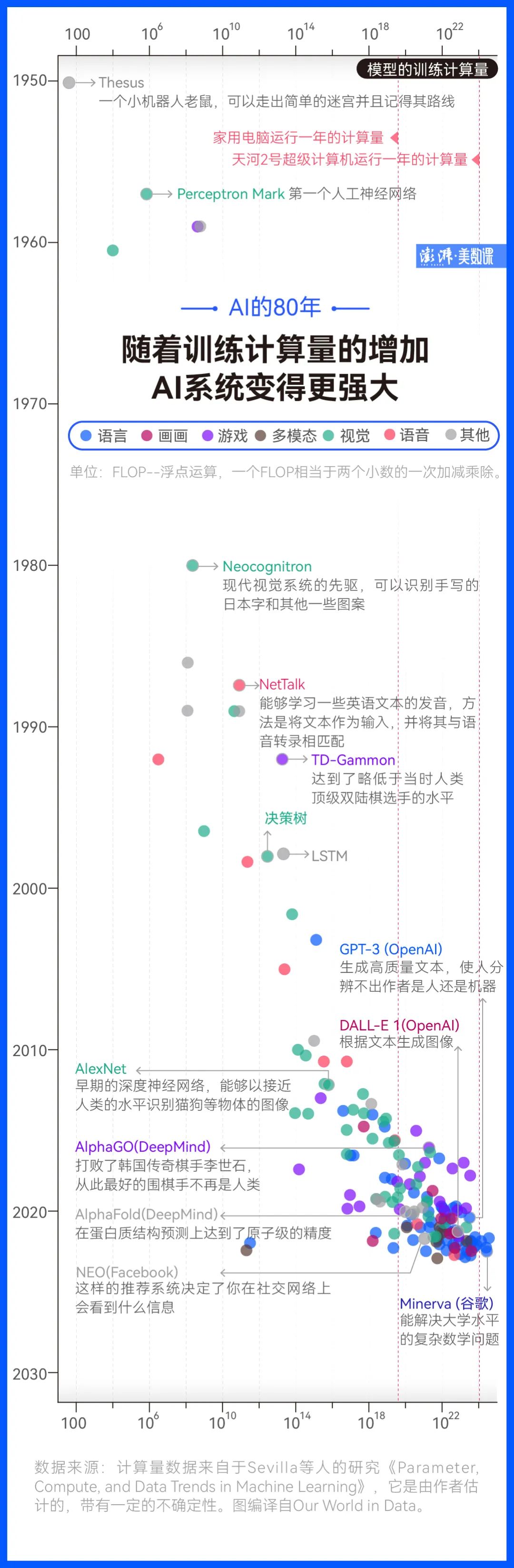
OpenAI 在 2019 年推出了 GPT-2,一个更大版本的 GPT-1,反响平平,在 2020 年推出了 GPT-3,一个更大版本的 GPT-2,终于大力出奇迹,激起千层浪。 据专业测算,训练一个 GPT-3 模型的第一阶段需要“355 个 GPU 年”,仅这一阶段的训练费用高达 450 万美元。
微软为 OpenAI 提供着资金和算力支持。2021 年 OpenAI 发表的 CLIP 模型学会了图片和其文字描述的对应关系,启发了很多后续应用,包括 AI 画画。
2022年中,OpenAI 放出了它神乎其技的 AI 画家,DALL-E 2,但只进行了小规模内测。于是它的低配版——DALL-E mini 变成了网友们趁手的新玩具,它听得懂人话,生成的图片虽然粗糙但是有趣,一时间成了互联网上的“梗图之王”。当时少有大众觉得 AI 能做出真的艺术创造,顶多拿来解闷罢了。仅过了一个多月,Midjourney、Stable Diffusion 和 DALL-E 2等 AI 画画工具接连向公众开放,人们终于意识到,AI 能画画,而且画得超乎想象的好。设计师会失业么?画家又如何看待这件事?到处都是这样的讨论。
但站在 2022 年的末尾谈 AI 画画,已经感到有些过时了。ChatGPT 抢走了这些 AI 画家的风头。
这个聊天机器人是鬼精灵,玩游戏、写代码、讲心灵鸡汤,无所不能,甚至还能写点小诗(尽管很平庸)。它能记住对话,进入情景,遵从指令,还展现了初级的推理能力,让人感叹“图灵测试已经被画上了句点”。有研究者评论“ChatGPT / GPT-3.5 是一种划时代的产物,它与之前常见的语言模型的区别,几乎是导弹与弓箭的区别”。
ChatGPT 当然还不完美,也谈不上能马上取代搜索引擎,因为它生成的答案还时有错误。也有消息称,此前谷歌内部已经开发出了强大的聊天机器人,但出于安全考虑,尚未对公众开放。大公司的谨慎给了小公司机会,Stability AI,这家公司 8 月份推出“文本转为图片”的生成器(Stable Diffusion),已经融资 1.01 亿美元。
无论如何,OpenAI 离他们 2016 年立下的那个长远目标更近了。人们因为看见了 ChatGPT 所以相信。2016 年 Sam Altman 接受《纽约客》采访时把一个人工智能算法比作一个人类婴儿,“婴儿学习任何有意义的事情都要好几年”,而他认为 OpenAI 的使命是“照顾好自己的「神童」,一直等到他可以由世界来「抚养」”。按照这个约定,他们已经照顾了 GPT 系列 4 年。
人工智能的奇点临近了,很多人这样讲。就好像站在一块不断隆起的土地上,不知道明天它会把你带向何方。或许我们每个人都要经历那个在自己最引以为傲的事情上被 AI 打败的时刻,正如 6 年前李世石和 AlphaGO 交锋的第一局,他抚摸棋盒边缘,终于落白子投降的那一刻。那一场的裁判,同样被 AlphaGO 打败的欧洲围棋冠军杯的冠军樊麾说,AlphaGo 是面镜子,在它面前棋手不得不直面赤身裸体的自己。
或许通用人工智能到来的时候,所有人都不得不直面那个最简单的问题,我是谁?
文本还可以生出这些 ……
文本生文本、文本生图像,已然不稀奇。让我们来谈点更时髦的吧,那些快要破土而出的新技术,文本可以生出万物。
首先,逃离平面,文本能生成 3D 模型了。
 OpenAI, Point·E
OpenAI, Point·E
不仅如此,谷歌声称,他们能用极少的图片(甚至单张图片)生成 3D 模型,拳打脚踢摄影测量法。
Google, 3DiM
稍微偏离一点儿轨道,写一段描述,AI 能生成对应的声效。比如,“在风中吹口哨”“警报声和嗡嗡作响的引擎接近后又走远”。
Meta AI, AudioGen
不管你信不信,AI 还能根据配乐起舞。或许不久之后,AI 就能给 KPOP 编舞了。
Stanford University, EDGE
步子迈得大一些,当然,已经有人在让 AI 做视频了,尽管还很短。
Google, Imagen Video
为视频创作者提供 AI 工具的网站 Runway 宣布举办第一届 AI 电影节,要求电影的核心需要为 AI 生成。是的,AI 已经走到这一步了。
毫无疑问,未来,AI 的文本炼金术能让创作的成本变得更低,人们可以不太费力地得到符合工业水准的产品。Joe Penna,一个电影导演,为了生成电影需要用到的特定的演员、地点、道具,他和朋友们一起开发了 DreamBooth 的民间版本,它能够做到输入文字,生成关于特定事物(比如你家沙发上的一只玩具小熊)的一组图像。漫画家,或者画工拙劣的编剧,也完全可以将 AI 当做自己的草稿本,由此掀开他的“宏伟巨著”。
 点「在看」的人都变好看了哦!
点「在看」的人都变好看了哦!
评论