
我的Pandas学习经历及动手实践
想入门人工智能或者数据分析,要重视可以快速上手的学习技能:掌握一些基本概念,建立一个知识框架,然后就去实战,在实战中学习新知识,来填充这个框架。
我根据之前整理的一些pandas知识,总结了一个pandas的快速入门的知识框架。有了这些知识,然后去通过项目实战,然后再补充。希望能帮助大家快速上手。

Pandas入门知识框架
1. 什么是Pandas?熊猫?
Pandas 可以说是基于 NumPy 构建的含有更高级数据结构和分析能力的工具包, 实现了类似Excel表的功能,可以对二维数据表进行很方便的操作。
在数据分析工作中,Pandas 的使用频率是很高的,一方面是因为 Pandas 提供的基础数据结构 DataFrame 与 json 的契合度很高,转换起来就很方便。另一方面,如果我们日常的数据清理工作不是很复杂的话,你通常用几句 Pandas 代码就可以对数据进行规整。
Pandas的核心数据结构:Series 和 DataFrame 这两个核心数据结构。他们分别代表着一维的序列和二维的表结构。基于这两种数据结构,Pandas 可以对数据进行导入、清洗、处理、统计和输出。
快速掌握Pandas,就要快速学会这两种核心数据结构。
2. 两种核心数据结构
2.1 Series
Series 是个定长的字典序列。说是定长是因为在存储的时候,相当于两个 ndarray,这也是和字典结构最大的不同。因为在字典的结构里,元素的个数是不固定的。
Series 有两个基本属性:index 和 values。在 Series 结构中,index 默认是 0,1,2,……递增的整数序列,当然我们也可以自己来指定索引,比如 index=[‘a’, ‘b’, ‘c’, ‘d’]。
import pandas as pd
from pandas import Series, DataFrame
x1 = Series([1,2,3,4])
x2 = Series(data=[1,2,3,4], index=['a', 'b', 'c', 'd'])
print x1
print x2
上面这个例子中,x1 中的 index 采用的是默认值,x2 中 index 进行了指定。我们也可以采用字典的方式来创建 Series,比如:
d = {'a':1, 'b':2, 'c':3, 'd':4}
x3 = Series(d)
print x3
Series的增删改查
创建一个Series
In [85]: ps = pd.Series(data=[-3,2,1],index=['a','f','b'],dtype=np.float32)
In [86]: ps
Out[86]:
a -3.0
f 2.0
b 1.0
dtype: float32增加元素append
In [112]: ps.append(pd.Series(data=[-8.0],index=['f']))
Out[112]:
a 4.0
f 2.0
b 1.0
f -8.0
dtype: float64删除元素drop
In [119]: ps
Out[119]:
a 4.0
f 2.0
b 1.0
dtype: float32
In [120]: psd = ps.drop('f')
In [121]: psd
Out[121]:
a 4.0
b 1.0
dtype: float32注意不管是 append 操作,还是 drop 操作,都是发生在原数据的副本上,不是原数据上。
修改元素
通过标签修改对应数据,如下所示:In [123]: psn
Out[123]:
a 4.0
f 2.0
b 1.0
f -8.0
dtype: float64
In [124]: psn['f'] = 10.0
In [125]: psn
Out[125]:
a 4.0
f 10.0
b 1.0
f 10.0
dtype: float64Series里面允许标签相同, 且如果相同, 标签都会被修改。
访问元素
一种通过默认的整数索引,在 Series 对象未被显示的指定 label 时,都是通过索引访问;另一种方式是通过标签访问。In [126]: ps
Out[126]:
a 4.0
f 2.0
b 1.0
dtype: float32
In [128]: ps[2] # 索引访问
Out[128]: 1.0
In [127]: ps['b'] # 标签访问
Out[127]: 1.0
2.2 DataFrame
DataFrame 类型数据结构类似数据库表。它包括了行索引和列索引,我们可以将 DataFrame 看成是由相同索引的 Series 组成的字典类型。
import pandas as pd
from pandas import Series, DataFrame
data = {'Chinese': [66, 95, 93, 90,80],'English': [65, 85, 92, 88, 90],'Math': [30, 98, 96, 77, 90]}
df1= DataFrame(data)
df2 = DataFrame(data, index=['ZhangFei', 'GuanYu', 'ZhaoYun', 'HuangZhong', 'DianWei'], columns=['English', 'Math', 'Chinese'])
print df1
print df2
在后面的案例中,我一般会用 df, df1, df2 这些作为 DataFrame 数据类型的变量名,我们以例子中的 df2 为例,列索引是[‘English’, ‘Math’, ‘Chinese’],行索引是[‘ZhangFei’, ‘GuanYu’, ‘ZhaoYun’, ‘HuangZhong’, ‘DianWei’],所以 df2 的输出是:
English Math Chinese
ZhangFei 65 30 66
GuanYu 85 98 95
ZhaoYun 92 96 93
HuangZhong 88 77 90
DianWei 90 90 80
2.2.1基本操作
(1)数据的导入与输出
Pandas 允许直接从 xlsx,csv 等文件中导入数据,也可以输出到 xlsx, csv 等文件,非常方便。
需要说明的是,在运行的过程可能会存在缺少 xlrd 和 openpyxl 包的情况,到时候如果缺少了,可以在命令行模式下使用“pip install”命令来进行安装。
import pandas as pd
from pandas import Series, DataFrame
score = DataFrame(pd.read_excel('data.xlsx'))
score.to_excel('data1.xlsx')
print score
关于数据导入, pandas提供了强劲的读取支持, 比如读写CSV文件, read_csv()函数有38个参数之多, 这里面有一些很有用, 主要可以分为下面几个维度来梳理:
基本参数
filepathorbuffer: 数据的输入路径, 可以是文件路径, 也可是是URL或者实现read方法的任意对象sep: 数据文件的分隔符, 默认为逗号delim_whitespace: 表示分隔符为空白字符, 可以是一个空格, 两个空格header: 设置导入DataFrame的列名称, 如果names没赋值, header会选取数据文件的第一行作为列名index_col: 表示哪个或者哪些列作为indexusecols: 选取数据文件的哪些列到DataFrame中prefix: 当导入的数据没有header时, 设置此参数会自动加一个前缀通用解析参数
dtype:读取数据时修改列的类型converters: 实现对列数据的变化操作skip_rows: 过滤行nrows: 设置一次性读入的文件行数,它在读入大文件时很有用,比如 16G 内存的PC无法容纳几百 G 的大文件。skip_blank_lines: 过滤掉空行时间处理相关参数
parse_dates: 如果导入的某些列为时间类型,但是导入时没有为此参数赋值,导入后就不是时间类型 date_parser: 定制某种时间类型 分开读入相关参数:
分块读入内存,尤其单机处理大文件时会很有用。iterator: iterator 取值 boolean,default False,返回一个 TextFileReader 对象,以便逐块处理文件。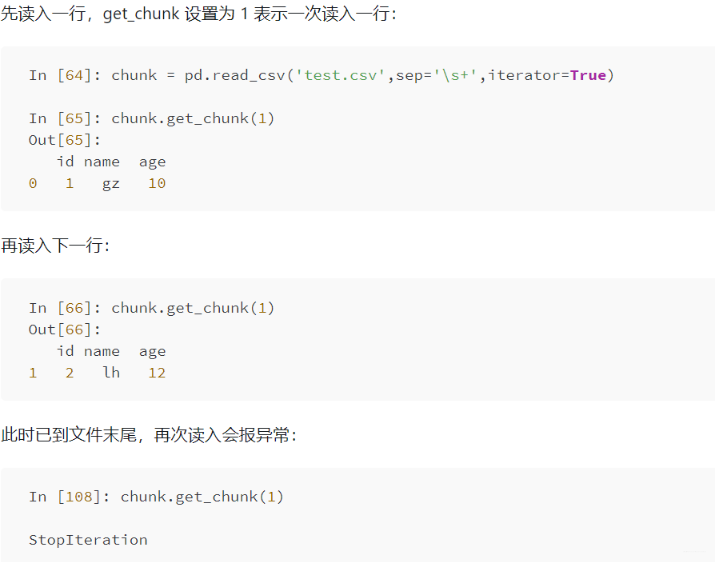
chunksize: 整型,默认为 None,设置文件块的大小。 格式和压缩相关参数
id name age 0 1 gz 10 1 2 lh 12
- `thousands`: str,default None,千分位分割符,如 `,` 或者 `.`。
- `encoding`: 指定字符集类型,通常指定为 ‘utf-8’compression
compression 参数取值为 {‘infer’, ‘gzip’, ‘bz2’, ‘zip’, ‘xz’, None},默认 ‘infer’,直接使用磁盘上的压缩文件。如果使用 infer 参数,则使用 gzip、bz2、zip 或者解压文件名中以 ‘.gz’、‘.bz2’、‘.zip’ 或 ‘xz’ 这些为后缀的文件,否则不解压。如果使用 zip,那么 ZIP 包中必须只包含一个文件。设置为 None 则不解压。手动压缩本文一直使用的 test.csv 为 test.zip 文件,然后打开In [73]: df = pd.read_csv('test.zip',sep='\s+',compression='zip')
In [74]: df
Out[74]:
具体这些参数怎么用, 可以看https://gitbook.cn/gitchat/column/5e37978dec8d9033cf916b5d/topic/5e3bcef3ec8d9033cf92466f
(2)数据清洗
数据清洗是数据准备过程中必不可少的环节,Pandas 也为我们提供了数据清洗的工具,在后面数据清洗的章节中会给你做详细的介绍,这里简单介绍下 Pandas 在数据清洗中的使用方法。
(2.1)删除 DataFrame 中的不必要的列或行
Pandas 提供了一个便捷的方法 drop() 函数来删除我们不想要的列或行
df2 = df2.drop(columns=['Chinese'])
想把“张飞”这行删掉。
df2 = df2.drop(index=['ZhangFei'])
(2.2)重命名列名 columns,让列表名更容易识别
如果你想对 DataFrame 中的 columns 进行重命名,可以直接使用 rename(columns=new_names, inplace=True) 函数,比如我把列名 Chinese 改成 YuWen,English 改成 YingYu。
df2.rename(columns={'Chinese': 'YuWen', 'English': 'Yingyu'}, inplace = True)
(2.3)去重复的值
数据采集可能存在重复的行,这时只要使用 drop_duplicates() 就会自动把重复的行去掉
df = df.drop_duplicates() #去除重复行
(2.4)格式问题
更改数据格式
这是个比较常用的操作,因为很多时候数据格式不规范,我们可以使用 astype 函数来规范数据格式,比如我们把 Chinese 字段的值改成 str 类型,或者 int64 可以这么写
df2['Chinese'].astype('str')
df2['Chinese'].astype(np.int64)
数据间的空格
有时候我们先把格式转成了 str 类型,是为了方便对数据进行操作,这时想要删除数据间的空格,我们就可以使用 strip 函数:
#删除左右两边空格
df2['Chinese']=df2['Chinese'].map(str.strip)
#删除左边空格
df2['Chinese']=df2['Chinese'].map(str.lstrip)
#删除右边空格
df2['Chinese']=df2['Chinese'].map(str.rstrip)
如果数据里有某个特殊的符号,我们想要删除怎么办?同样可以使用 strip 函数,比如 Chinese 字段里有美元符号,我们想把这个删掉,可以这么写:
df2['Chinese']=df2['Chinese'].str.strip('$')
(2.5)大小写转换
大小写是个比较常见的操作,比如人名、城市名等的统一都可能用到大小写的转换,在 Python 里直接使用 upper(), lower(), title() 函数,方法如下:
#全部大写
df2.columns = df2.columns.str.upper()
#全部小写
df2.columns = df2.columns.str.lower()
#首字母大写
df2.columns = df2.columns.str.title()
(2.6)查找空值
数据量大的情况下,有些字段存在空值 NaN 的可能,这时就需要使用 Pandas 中的 isnull 函数进行查找。比如,我们输入一个数据表如下: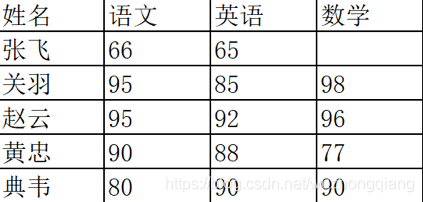
如果我们想看下哪个地方存在空值 NaN,可以针对数据表 df 进行 df.isnull(),结果如下: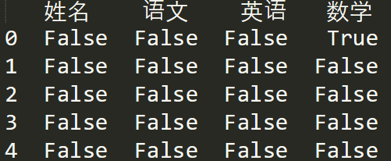
如果我想知道哪列存在空值,可以使用 df.isnull().any(),结果如下: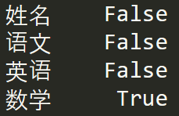
2.2.2 使用apply函数对数据进行清洗
apply 函数是 Pandas 中自由度非常高的函数,使用频率也非常高。比如我们想对 name 列的数值都进行大写转化可以用:
df['name'] = df['name'].apply(str.upper)
我们也可以定义个函数,在 apply 中进行使用。比如定义 double_df 函数是将原来的数值 *2 进行返回。然后对 df1 中的“语文”列的数值进行 *2 处理,可以写成:
def double_df(x):
return 2*x
df1[u'语文'] = df1[u'语文'].apply(double_df)
我们也可以定义更复杂的函数,比如对于 DataFrame,我们新增两列,其中’new1’列是“语文”和“英语”成绩之和的 m 倍,'new2’列是“语文”和“英语”成绩之和的 n 倍,我们可以这样写:
def plus(df,n,m):
df['new1'] = (df[u'语文']+df[u'英语']) * m
df['new2'] = (df[u'语文']+df[u'英语']) * n
return df
df1 = df1.apply(plus,axis=1,args=(2,3,))
2.3 数据统计
在数据清洗后,我们就要对数据进行统计了。Pandas 和 NumPy 一样,都有常用的统计函数,如果遇到空值 NaN,会自动排除。常用的统计函数包括:
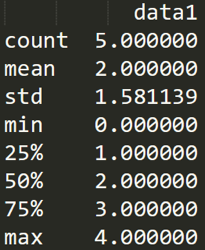
表格中有一个 describe() 函数,统计函数千千万,describe() 函数最简便。它是个统计大礼包,可以快速让我们对数据有个全面的了解。下面我直接使用 df1.descirbe() 输出结果为:
df1 = DataFrame({'name':['ZhangFei', 'GuanYu', 'a', 'b', 'c'], 'data1':range(5)})
print df1.describe()
2.4 数据表合并
有时候我们需要将多个渠道源的多个数据表进行合并,一个 DataFrame 相当于一个数据库的数据表,那么多个 DataFrame 数据表的合并就相当于多个数据库的表合并。
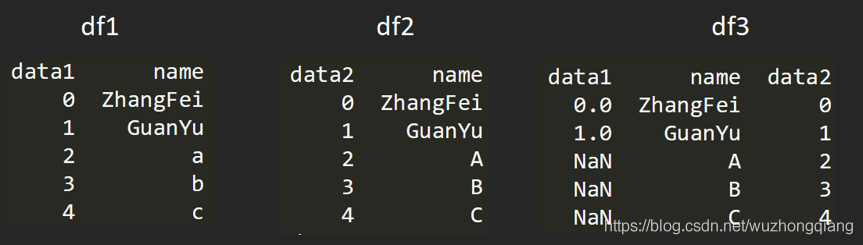
比如我要创建两个 DataFrame:
df1 = DataFrame({'name':['ZhangFei', 'GuanYu', 'a', 'b', 'c'], 'data1':range(5)})
df2 = DataFrame({'name':['ZhangFei', 'GuanYu', 'A', 'B', 'C'], 'data2':range(5)})
两个 DataFrame 数据表的合并使用的是 merge() 函数,有下面 5 种形式:
比如我们可以基于 name 这列进行连接。基于指定列进行连接
df3 = pd.merge(df1, df2, on='name')

2. inner内连接
inner 内链接是 merge 合并的默认情况,inner 内连接其实也就是键的交集,在这里 df1, df2 相同的键是 name,所以是基于 name 字段做的连接:
df3 = pd.merge(df1, df2, how='inner')
3. left左连接
左连接是以第一个 DataFrame 为主进行的连接,第二个 DataFrame 作为补充。
df3 = pd.merge(df1, df2, how='left')
右连接是以第二个 DataFrame 为主进行的连接,第一个 DataFrame 作为补充。right右连接
df3 = pd.merge(df1, df2, how='right')
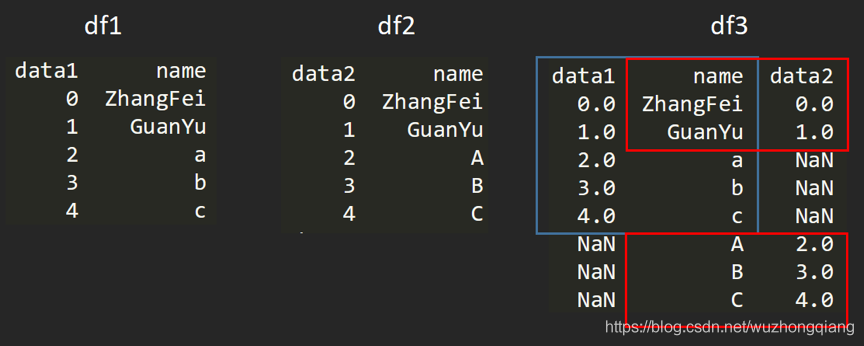
5. outer外连接
外连接相当于求两个 DataFrame 的并集。
df3 = pd.merge(df1, df2, how='outer')
2.5 DataFram的行级遍历
尽管 Pandas 已经尽可能向量化,让使用者尽可能避免 for 循环,但是有时不得已,还得要遍历 DataFrame。Pandas 提供 iterrows、itertuples 两种行级遍历。
使用
iterrows遍历打印所有行,在 IPython 里输入以下行:def iterrows_time(df):
for i,row in df.iterrows():
print(row)访问每一行某个元素的时候, 可以通过列名直接访问:

使用
itertuples遍历打印每行:def itertuples_time(df):
for nt in df.itertuples():
print(nt)这个效率更高, 比上面那个节省6倍多的时间, 所在数据量非常大的时候, 推荐后者。访问每一行某个元素的时候, 需要
getattr函数
使用
iteritems遍历每一行这个访问每一行元素的时候, 用的是每一列的数字索引

3. 如何用SQL方式打开Pandas
Pandas 的 DataFrame 数据类型可以让我们像处理数据表一样进行操作,比如数据表的增删改查,都可以用 Pandas 工具来完成。不过也会有很多人记不住这些 Pandas 的命令,相比之下还是用 SQL 语句更熟练,用 SQL 对数据表进行操作是最方便的,它的语句描述形式更接近我们的自然语言。
事实上,在 Python 里可以直接使用 SQL 语句来操作 Pandas。
这里给你介绍个工具:pandasql。
pandasql 中的主要函数是 sqldf,它接收两个参数:一个 SQL 查询语句,还有一组环境变量 globals() 或 locals()。这样我们就可以在 Python 里,直接用 SQL 语句中对 DataFrame 进行操作,举个例子:
import pandas as pd
from pandas import DataFrame
from pandasql import sqldf, load_meat, load_births
df1 = DataFrame({'name':['ZhangFei', 'GuanYu', 'a', 'b', 'c'], 'data1':range(5)})
pysqldf = lambda sql: sqldf(sql, globals())
sql = "select * from df1 where name ='ZhangFei'"
print pysqldf(sql)
运行结果
data1 name
0 0 ZhangFei
上面代码中,定义了:
pysqldf = lambda sql: sqldf(sql, globals())
在这个例子里,输入的参数是 sql,返回的结果是 sqldf 对 sql 的运行结果,当然 sqldf 中也输入了 globals 全局参数,因为在 sql 中有对全局参数 df1 的使用。
参考
极客时间《数据分析实战45讲》课程:https://time.geekbang.org/ Pandas的基本使用:http://note.youdao.com/noteshare?id=28264a6b8536e4448e0bf3de701cd230&sub=25080C078C444E6E8B0C809C88BD0C76 python数据分析实用小抄:https://www.cnblogs.com/nxld/p/6687253.html 像Excel一样使用python进行数据分析:https://www.cnblogs.com/nxld/p/6756492.html 50道练习带你玩转Pandas:https://mp.weixin.qq.com/s/39yPBJ7DWSMs_aIxtlpXCw AI基础:Pandas简易入门:https://mp.weixin.qq.com/s/uLBJc_iIize8a9B491U7VQ Pandas常用用法:https://www.freesion.com/article/7330378876/
整理不易,点赞三连↓