
深度学习论文精读[8]:ParseNet

U形的编解码结构奠定了深度学习语义分割的基础,随着基线模型的表现越来越好,深度学习语义分割关注的焦点开始由原先的编解码架构下上采样如何更好的恢复图像像素转变为如何更加有效的利用图像上下文信息和提取多尺度特征。因而催生出语义分割的第二个主流的结构设计:多尺度结构。接下来的几篇论文解读将对重在关注图像上下文信息和多尺度特征的结构设计网络进行梳理,包括ParseNet、PSPNet、以空洞卷积为核心的Deeplab系列、HRNet以及其他代表性的多尺度设计。
自从全卷积网络(Fully Convolutional Networks, FCN)和UNet提出以来,主流的改进思路是围绕着编解码结构来进行的。但又一些改进在当时看来却不是那么“主流”,其中有一些是针对如何提升网络的全局信息提取能力来进行改进的。FCN提出之后,一些学者认为FCN忽略了图像作为整张图的全局信息,因而在一些应用场景下不能有效利用图像的语义上下文信息。图像全局信息除了增加对图像的整体理解之外,还有助于模型对局部图像块的判断,此前一种主流的方法是将概率图模型融入到CNN训练中,用于捕捉图像像素的上下文信息,比如说给模型加条件随机场(Conditional Random Field,CRF),但这种方式会使得模型难以训练并且变得低效。
针对如何高效利用图像的全局信息问题,相关研究在FCN结构的基础上提出了ParseNet,一种高效的端到端的语义分割网络,旨在利用全局信息来指导局部信息判断,并且引入太多的额外计算开销。提出ParseNet的论文为ParseNet: Looking Wider to See Better,发表于2015年,是在FCN基础上基于上下文视角的一个改进设计。在语义分割中,上下文信息对于提升模型表现非常关键,在仅有局部信息情况下,像素的分类判断有时候会变得模棱两可。尽管理论上深层卷积层的会有非常大的感受野,但在实际中有效感受野却小很多,不足以捕捉图像的全局信息。ParseNet通过全局平均池化的方法在FCN基础上直接获取上下文信息,图1为ParseNet的上下文提取模块,具体地,使用全局平均池化对上下文特征图进行池化后得到全局特征,然后对全局特征进行L2规范化处理,再对规范化后的特征图反池化后与局部特征图进行融合,这样的一个简单结构对于语义分割质量的提升的巨大的。如图2所示,ParseNet能够关注到图像中的全局信息,保证图像分割的完整性。
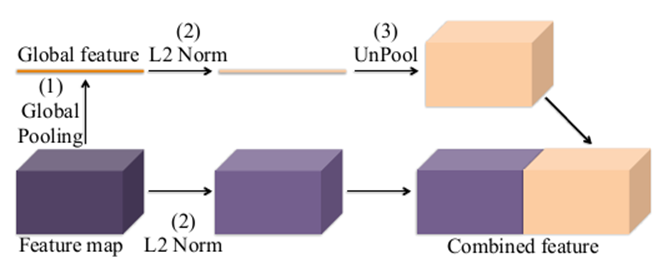
关于全局特征与局部特征的融合,ParseNet给出两种融合方式:早期融合(early fusion)和晚期融合(late fusion)。早期融合就是图6-1中所展现的融合方式,对全局特征反池化后直接与局部特征进行融合,然后在进行像素分类。而晚期融合则是把全局特征和局部特征分别进行像素分类后再进行某种融合,比如说进行加权。但无论是早期融合还是晚期融合,如果选取的归一化方式合适,其效果是差不多的。
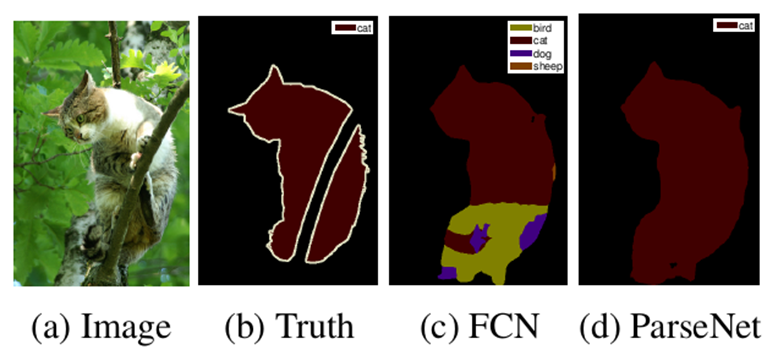
下图是ParseNet在VOC 2012数据集上的分割效果,可以看到,ParseNet的分割能够明显关注到图像全局信息。

ParseNet作者基于caffe的源码可参考:
https://github.com/weiliu89/caffe
往期精彩: