
独家|pytorch模型性能分析和优化
共 15785字,需浏览 32分钟
·
2023-08-29 15:04

翻译:林立锟
校对:zrx
本文约6700字,建议阅读10分钟
本文介绍了pytorch模型性能分析和优化。

照片由 Torsten Dederichs 拍摄,上传到 Unsplash

性能优化流程(来自作者)
优化后的性能(摘自 PyTorch 网站)
简单示例
import numpy as npimport torchimport torch.nnimport torch.optimimport torch.profilerimport torch.utils.dataimport torchvision.datasetsimport torchvision.modelsimport torchvision.transforms as Tfrom torchvision.datasets.vision import VisionDatasetfrom PIL import Imageclass FakeCIFAR(VisionDataset):def __init__(self, transform):super().__init__(root=None, transform=transform)self.data = np.random.randint(low=0,high=256,size=(1,000,032,323),dtype=np.uint8)self.targets = np.random.randint(low=0,high=10,size=(10000),dtype=np.uint8).tolist()def __getitem__(self, index):img, target = self.data[index], self.targets[index]img = Image.fromarray(img)if self.transform is not None:img = self.transform(img)return img, targetdef __len__(self) -> int:return len(self.data)transform = T.Compose([T.Resize(224),T.ToTensor(),T.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])train_set = FakeCIFAR(transform=transform)train_loader = torch.utils.data.DataLoader(train_set, batch_size=32,shuffle=True)device = torch.device("cuda:0")model = torchvision.models.resnet18(weights='IMAGENET1K_V1').cuda(device)criterion = torch.nn.CrossEntropyLoss().cuda(device)optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)model.train()# train stepdef train(data):inputs, labels = data[0].to(device=device), data[1].to(device=device)outputs = model(inputs)loss = criterion(outputs, labels)optimizer.zero_grad()loss.backward()optimizer.step()# training loop wrapped with profiler objectwith torch.profiler.profile(schedule=torch.profiler.schedule(wait=1, warmup=4, active=3, repeat=1),on_trace_ready=torch.profiler.tensorboard_trace_handler('./log/resnet18'),record_shapes=True,profile_memory=True,with_stack=True) as prof:for step, batch_data in enumerate(train_loader):if step >= (1 + 4 + 3) * 1:breaktrain(batch_data)prof.step() # Need to call this at the end of each step
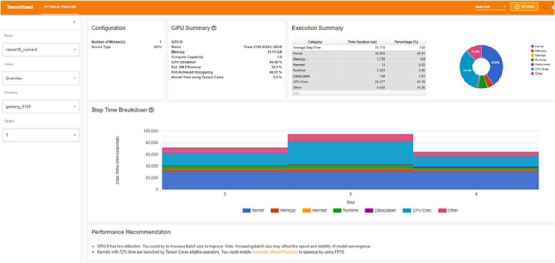
TensorBoard Profiler 概述选项卡中显示的基线性能结果(作者截图)
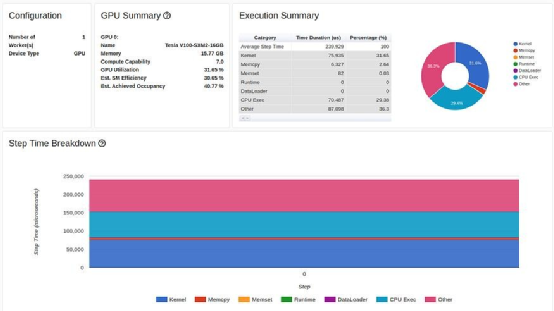
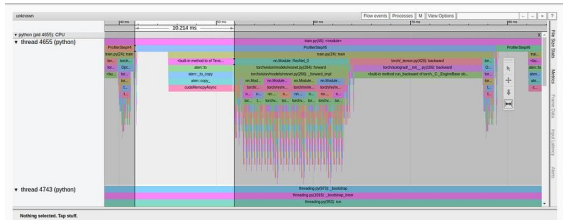
首先,我们注意到,与教程相反,我们实验中的概述页面(torrent-tb-profiler 0.4.1 版)将三个步骤合并为一个。因此,整个步骤的平均时间是 80 毫秒,而不是报告中的 240 毫秒。从跟踪选项卡(根据我们的经验,跟踪选项卡几乎总能提供更准确的报告)中可以清楚地看到这一点,其中每个步骤耗时约为80毫秒。
TensorBoard Profiler 跟踪视图选项卡中显示的基线性能结果(作者截图)
请注意,我们的起点(31.65% 的 GPU 利用率和 80 毫秒的步进时间)与教程中介绍的起点(分别为 23.54% 和 132 毫秒)有所不同。这可能是包括 GPU 类型和 PyTorch 版本在内的训练环境不同造成的。我们还注意到,教程的基线结果将性能问题明确诊断为数据加载器的瓶颈,而我们的结果并非如此。我们经常发现,数据加载瓶颈会伪装成 "概览 "选项卡中"CPU 执行 "或 "其他 "的高百分比。
优化 #1:多进程数据加载
首先,让我们按照教程中的描述使用多进程数据加载。鉴于Amazon EC2 p3.2xlarge 实例有 8 个 vCPU,我们将数据加载器工作者的数量设置为 8,以获得最高性能:
train_loader = torch.utils.data.DataLoader(train_set, batch_size=32,shuffle=True, num_workers=8)
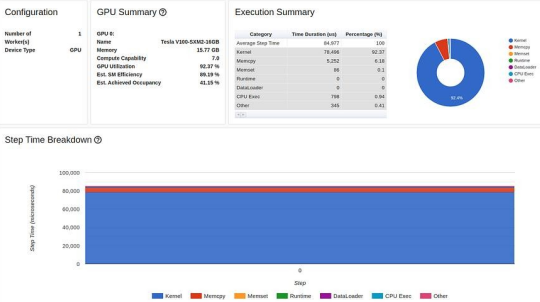
优化结果如下:
 |
优化#2:固定内存
train_loader = torch.utils.data.DataLoader(train_set, batch_size=32,shuffle=True, num_workers=8, pin_memory=True)
inputs, labels = data[0].to(device=device, non_blocking=True), \data[1].to(device=device, non_blocking=True)
|
|
优化 #3:增加batch大小
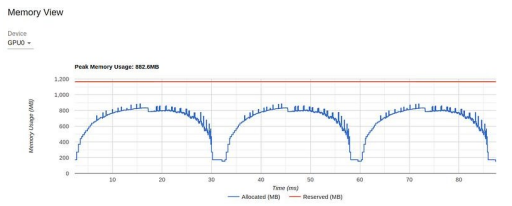
TensorBoard Profiler 中的内存视图(由作者截图)
优化 #4:减少主机到设备的复制
您可能注意到了,在我们之前的结果中,饼状图中代表主机到设备数据拷贝的红色大块。要解决这种瓶颈,最直接的方法就是看能否减少每批数据的数量。请注意,在图像输入的情况下,我们将数据类型从 8位无符号整数转换为 32 位浮点数,并在执行数据复制之前进行归一化处理。在下面的代码块中,我们建议对输入数据流进行修改,将数据类型转换和归一化推迟到数据进入 GPU 后进行:
# maintain the image input as an 8-bit uint8 tensortransform = T.Compose([T.Resize(224),T.PILToTensor()])train_set = FakeCIFAR(transform=transform)train_loader = torch.utils.data.DataLoader(train_set, batch_size=1024, shuffle=True, num_workers=8, pin_memory=True)device = torch.device("cuda:0")model = torch.compile(torchvision.models.resnet18(weights='IMAGENET1K_V1').cuda(device), fullgraph=True)criterion = torch.nn.CrossEntropyLoss().cuda(device)optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)model.train()# train stepdef train(data):inputs, labels = data[0].to(device=device, non_blocking=True), \data[1].to(device=device, non_blocking=True)# convert to float32 and normalizeinputs = (inputs.to(torch.float32) / 255. - 0.5) / 0.5outputs = model(inputs)loss = criterion(outputs, labels)optimizer.zero_grad()loss.backward()optimizer.step()
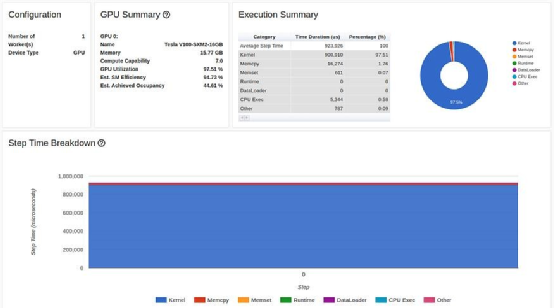
优化 #5:将梯度设置为无
optimizer.zero_grad(set_to_none=True)优化 #6:自动混合精度
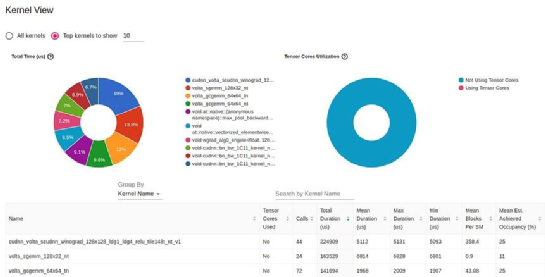
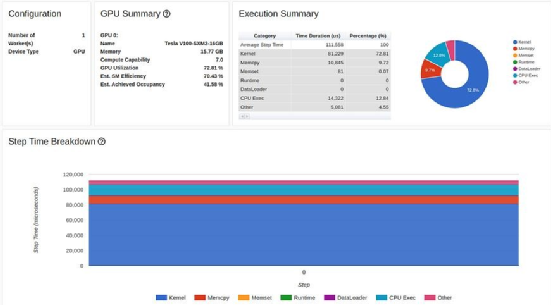
TensorBoard Profiler 中的内核视图(由作者捕获)
def train(data):inputs, labels = data[0].to(device=device, non_blocking=True), \data[1].to(device=device, non_blocking=True)inputs = (inputs.to(torch.float32) / 255. - 0.5) / 0.5with torch.autocast(device_type='cuda', dtype=torch.float16):outputs = model(inputs)loss = criterion(outputs, labels)# Note - torch.cuda.amp.GradScaler() may be requiredoptimizer.zero_grad(set_to_none=True)loss.backward()optimizer.step()
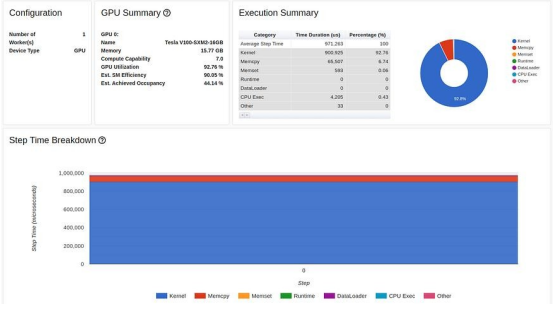
下图显示了对“张量核心”利用率的影响。虽然它继续表明还有进一步改进的机会,但仅凭一行代码,
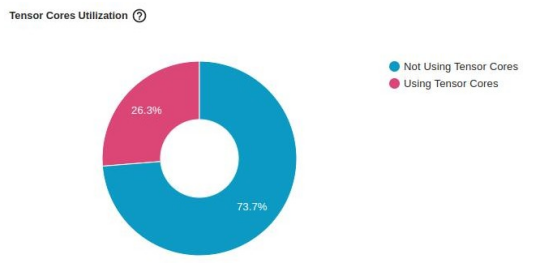
利用率就从 0% 跃升至26.3%。
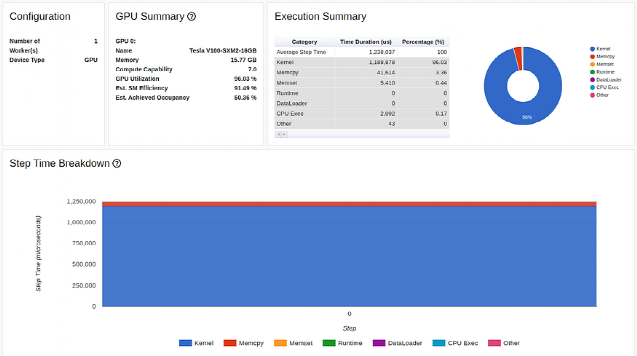
优化 #7:在图形模式下进行训练
model = torchvision.models.resnet18(weights='IMAGENET1K_V1').cuda(device)model = torch.compile(model)

TensorBoard Profiler 概述选项卡中的图形编译结果(作者截图)
临时成果
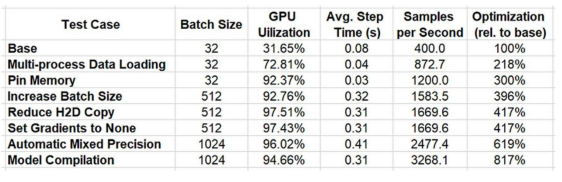
总结
下一个是?
原文标题:
PyTorch Model Performance Analysis and Optimization
原文链接:
PyTorch Model Performance Analysis and Optimization | by Chaim Rand | Towards Data Science
译者简介
作者简介
林立锟,香港城市大学计算数学本科,数据科学爱好者,对数学和计算机特别感兴趣,尤其是两者的结合部分特别感兴趣。兴趣是打羽毛球,以及琢磨一些奇奇怪怪的学习工具。希望能够通过自己的努力,将一些更优质的文章,更有价值的内容分享给读者,让大家在学习数据科学时能够更加顺利!
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。
点击“阅读原文”拥抱组织