
RabbitMQ 的延时队列和镜像队列原理与实战
你好呀,我是歪歪。
前几天的时候看了一个阿里云栖开发者沙龙的视频录播。
其中一个分享的主题就是掌阅资深后端工程师、掘金小测《Redis深度历险》作者钱文品老师给大家介绍的RabbitMQ的延时队列和镜像队列的原理与实践。
重点比较了 RabbitMQ 提供的消息可靠与不可靠模式,同时介绍了生产环境下如何使用 RabbitMQ 实现集群间消息传输。
如果大家有时间的话,可以看看这个直播回顾的视频:
https://yq.aliyun.com/live/965
如果你需要钱老师的 PPT 可以在公众号后台回复关键字 01,即可领取。
本文根据演讲视频以及PPT整理而成。
将主要围绕以下四个方面进行分享:
- RabbitMQ特性
- RabbitMQ中的消息不可靠问题及其解决方案
- 死信队列
- 生产环境下使用RabbitMQ应注意的事项
RabbitMQ特性
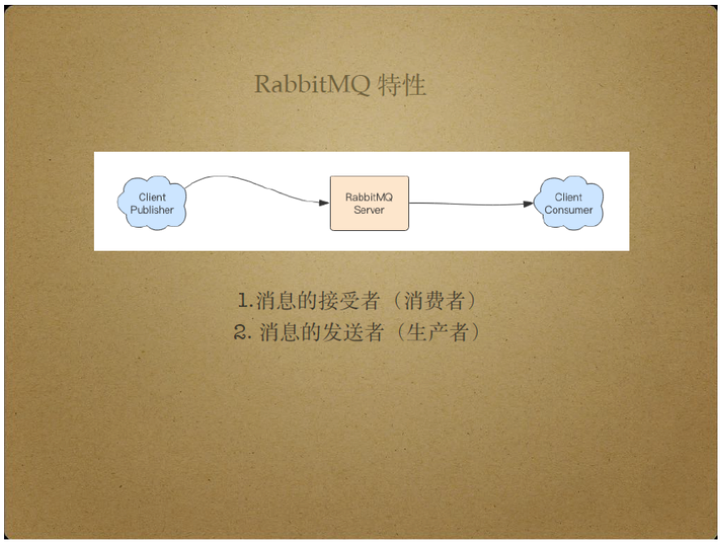
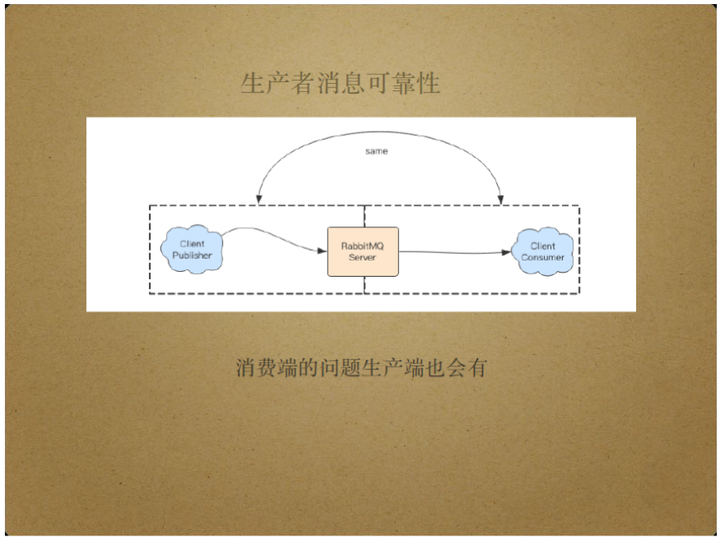
对于右边的Client Consumer而言,RabbitMQ Server是消息的发送者,也就是生产者。
RabbitMQ Server将消息从Client Publisher传送给Client Consumer,扮演着消息中间商的角色。
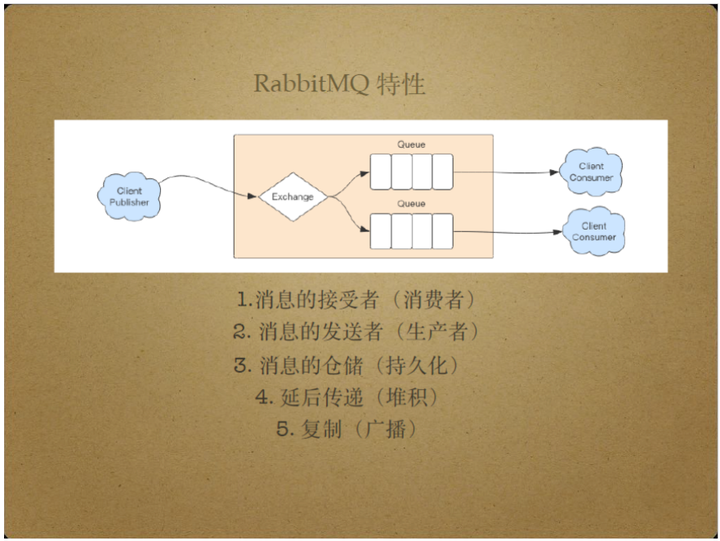
RabbitMQ Server负责将Client Publisher传递来的消息持久化,延后地将消息传递给Client Consumer.这样,即使消费者挂掉,RabbitMQ Server也可以存储消息,当消费者重新工作时再将存储的消息传递过去,从而保证消息不丢失。
RabbitMQ Server提供了堆积消息的能力。
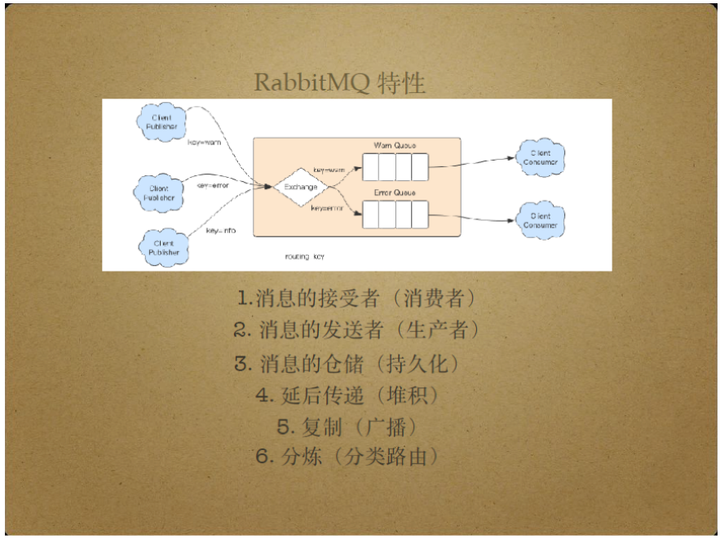
另外,RabbitMQ Server还具有复制和广播消息的能力。
具体来说,RabbitMQ Server可以将Client Publisher发布的消息分发给多个消费者,比如它能够将特定的消息按照特定的队列分发给特定的消费者。
“特定”指不同消息具有不同的routing key属性,由上图实例,不同的消息生产者生产了具有不同routing key的消息,通过exchange路由器将不同的routing key消息投递到不同队列,从而分发给不同消费者。
RabbitMQ中的消息不可靠问题及其解决方案
消费端消息不可靠问题及其解决方案
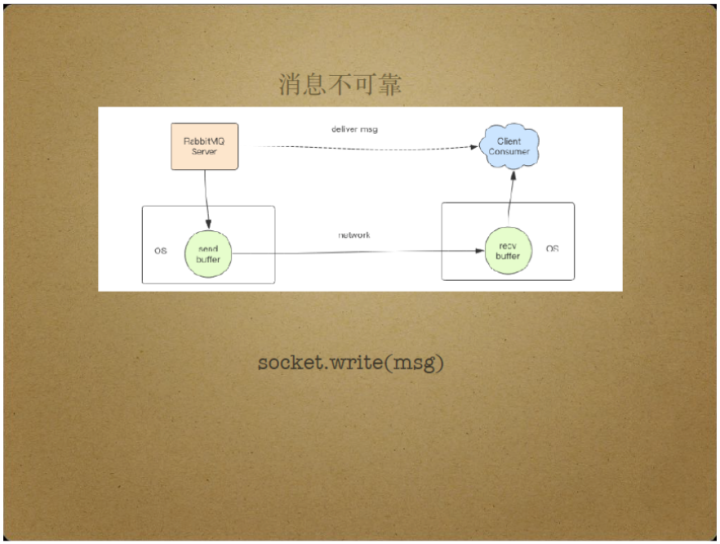
实际上,RabbitMQ Server将消息投递给消费者,具有消息不可靠的特点。
具体来说,RabbitMQ Server将消息投递给消费者时会调用套接字的write操作,而write操作的过程是不可靠性的。
在write操作的过程中,Server需要将消息发送到套接字的缓存中,通过网卡转发到链路上,最终到达消费者所在的机器内核的套接字缓存中,由消费者使用套接字的read操作将消息读出来。
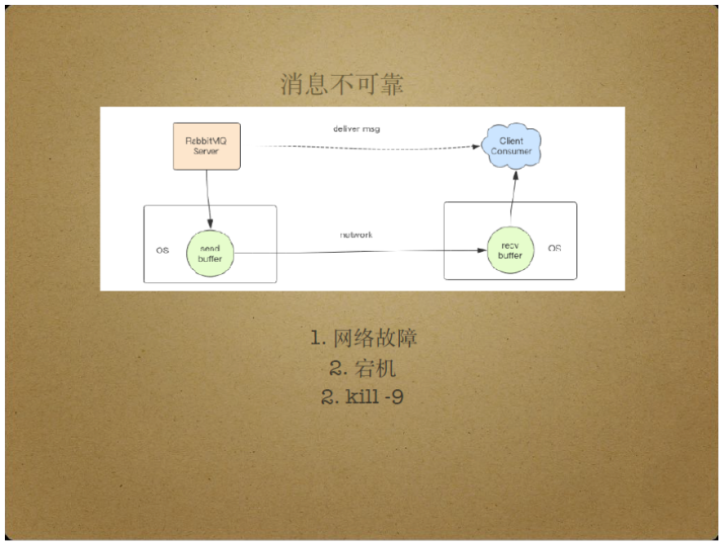
即使套接字的write操作成功也无法保证消息可靠,潜在的网络故障可能使消费者接收不到消息。
机器宕机也可能使消息不可靠,即使消息字节流已经到达消费者所在机器,消费者所在机器的宕机也可能使消息无法被即时读取并处理。
另外,即使消费者即时读取消息,内存消息队列中的所有消息也可能因为kill-9操作发生丢失。
这些可能性都直接导致了消息不可靠。
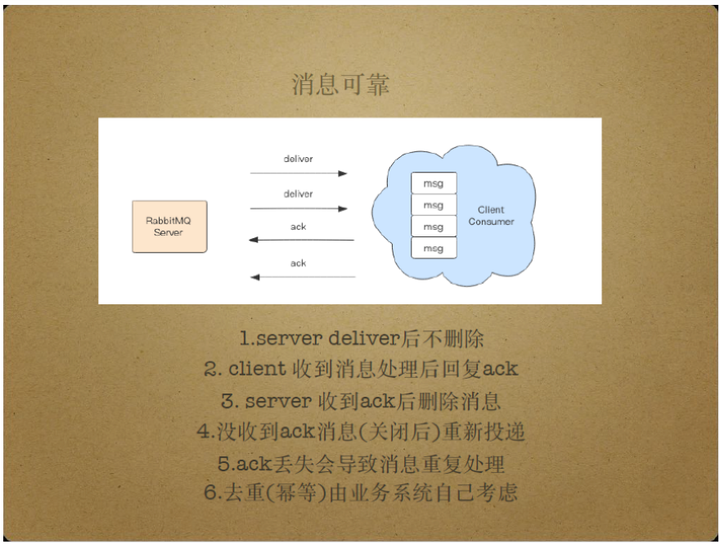
因此,需要额外的措施为消息提供可靠保障。
一种消息可靠性保障方式是,Server投递消息后并不立即将消息从Server删除,而是等到消费者接收、处理消息并返回Ack包给Server后,Server才删除该消息。
如果消费者没有发送Ack包,那么Server将重新投递该消息。
这个过程确保消息被消费者处理,保证了消息可靠。
另外,假如消费者已处理消息并发送Ack包给Server,但由于网络故障等问题导致Ack包丢失时,那么Server同样会重新投递该消息,导致消息被重复处理。
消息的重复处理通常由业务层面的技术手段来避免,比如在数据库层面添加主键约束等。
另一种重复消息处理的避免方式是客户端对每条消息维护ID,将被处理消息的ID记录在列表中,同时检查新到消息是否在该列表中。
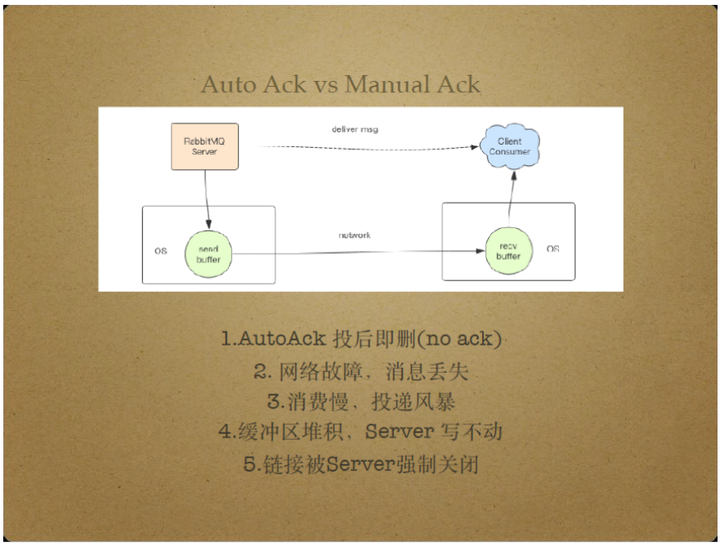
RabbitMQ中的Auto Ack和Manual Ack对应着消息不可靠模式和消息可靠模式. Auto Ack即no ack,指消息投后即删除,对应消息不可靠传输。
Manual Ack即手动Ack,消费者处理完消息后使用Ack包通知Server删除消息,对应消息可靠传输。
Auto Ack是RabbitMQ中最常用的模式,性能较好,但具有以下问题。
当消息通过套接字write操作投递后,RabbitMQ Server立即删除该消息,该模式在遇到网络故障时容易发生消息丢失。
另外,假如消费者处理消息的速率过低,可能导致消息在消费者recv buffer中大量堆积,从而导致Server端send buffer也堆积大量消息,Server端无法继续调用套接字write操作。
这样,一段时间之后,Server可能强制关闭消息传输链接,导致消息不可传输。
尽管Auto Ack存在一定风险,目前许多公司仍在应用Auto Ack模式。
使用Auto Ack模式时,开发者需要注意消费者和生产者的实例数量比例,使消息生产者产生消息的速率与消费者消费消息的速率大致持平。
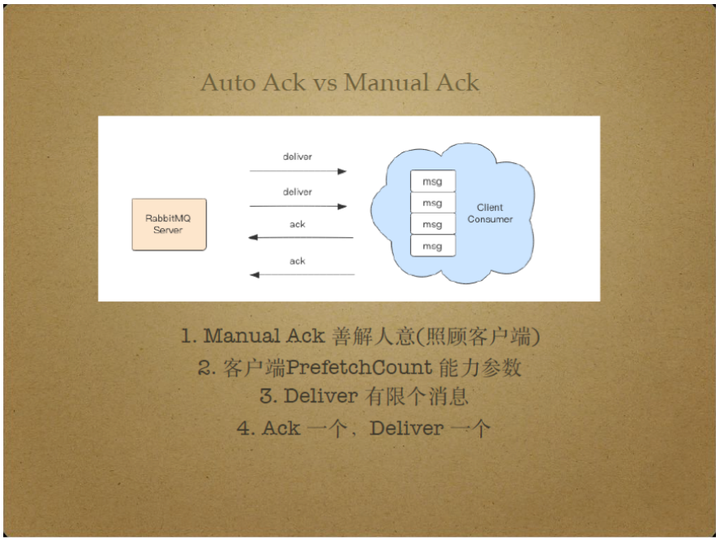
Manual Ack是RabbitMQ 中更加智能的一种模式。
Manual Ack在工作时会考虑消息消费者的消息接收能力,根据消费者的消息接受能力和当前接收到的Ack包自动调节分发消息的速率,保证消息分发可靠、不阻塞。具体来说,客户端通过PrefetchCount告知Server自身堆积消息的能力。
生产端消息不可靠问题及其解决方案
消息生产端同样存在消息的可靠性问题。
从Client Publisher将消息传递给Server和从Server将消息传递给Client Consumer的过程是完全对等的,Server和Client Consumer间传递消息的可靠性问题在Client Publisher和Server间同样存在。
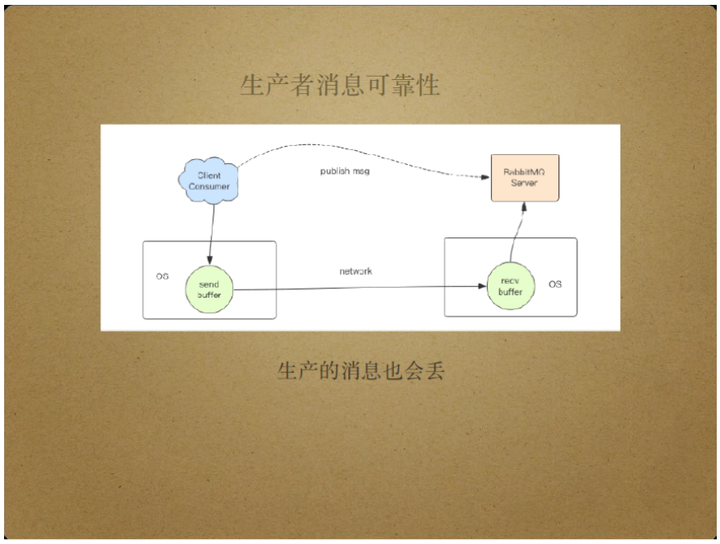
Client Publisher首先将消息写到套接字,再通过网络传递给Server的套接字buffer,最终由Server读取该消息。这一过程的潜在网络问题也可能使Server端接收不到消息。
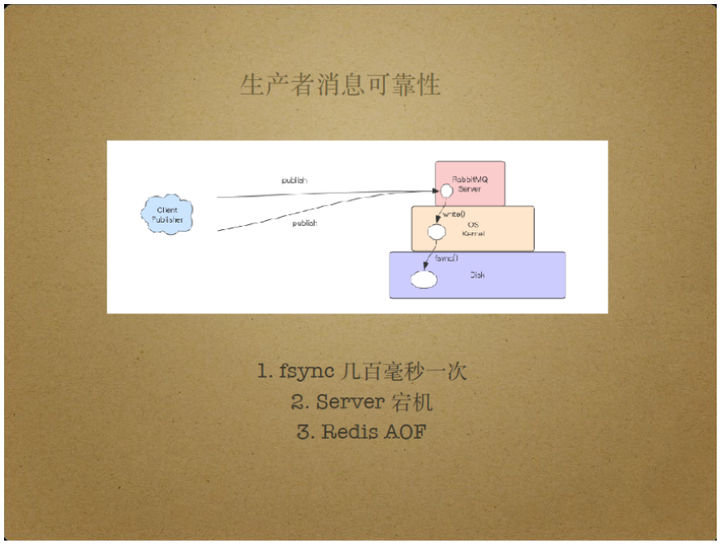
另外,Server端本身也可能导致消息不可靠。
Server端需要持久化消息,但出于性能开销的考虑,Server端并不在每次持久化消息时都刷盘。
具体来说,Server端会对文件执行write操作,将脏数据写入操作系统的缓存中,而不是立即将数据写入磁盘。
一般情况下,Server可能每几百毫秒执行一次fsync操作,通过fsync操作将文件的脏数据写入磁盘。
由于Server具有宕机风险,那么每次Server宕机时,还未被fsync操作处理的数据就可能丢失,此过程类似于Redis AOF。
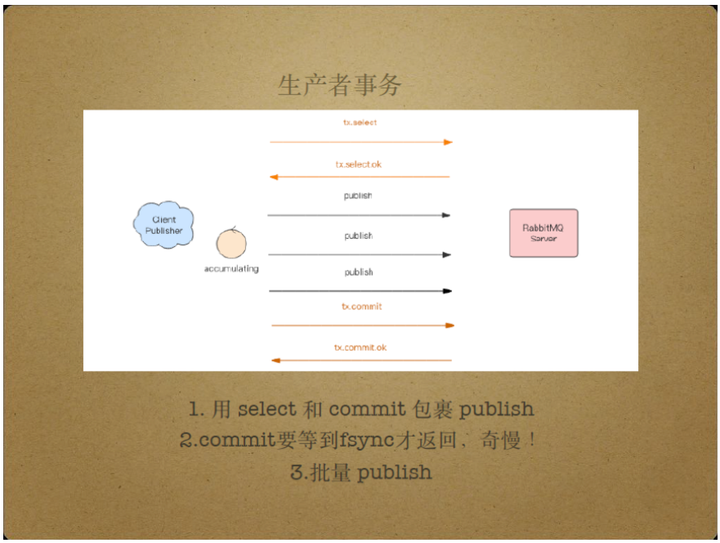
RabbitMQ通过生产者事务和生产者确认两个方法解决Server产生的数据不可靠问题。
生产者事务的基本原理是采用select和commit指令包裹publish,在消息生产者publish数据之前执行select操作,相当于begin transaction事务开始,在执行若干个publish操作后,再执行commit操作,相当于提交事务。根据tcp包的有序性,commit包成功接收意味着commit包之前的包也成功接收。
因此,收到从Client Publisher传递过来的commit包意味着该commit包之前的所有publish包都已成功接收,即所有消息都成功接收。
然而,commit包只有等到Server端的fsync操作执行完毕时才返回,因此生产者事务的效率较低,通常只在有批量publish操作时才使用生产者事务模式。
也就是说,客户端将消息累计起来批量发送,以降低fsync操作带来的性能损失。
此外,在进程中累计消息也存在风险,累计的消息可能由于进程挂掉而丢失。
总的来说,生产者事务由于性能缺点不被RabbitMQ官方推荐。
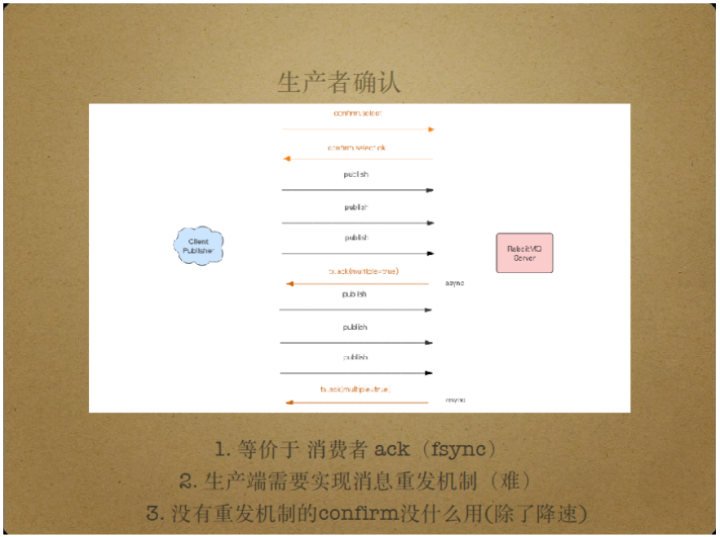
另一种Server带来的数据不可靠问题的解决方案是生产者确认。
生产者确认类似于消费端的Ack机制,生产者可能连续发送多条消息,Server将这些消息异步地通过fsync操作写入磁盘再异步地给生产者发送Ack包,告知生产者消息的接收成功。
由于Ack包异步传输,不影响生产者端消息的正常发送。生产者确认模式下,Ack包批量发送,并且都携带有序号,以告知生产者该序号以前的所有消息都已正常落盘。
尽管RabbitMQ推荐用户使用生产者确认模式,目前的RabbitMQ版本还未实现消息的重发机制,只实现了Ack包的批量发送,以通知Client Publisher哪些消息接收成功。
当消息丢失时,Client Publisher端已publish的消息在进程挂掉时也可能丢失,而不是重新发送,因此生产者确认的作用也不明显。
当然,生产者确认起到了降低消息发布速度的作用,减小了消息丢失的数量。
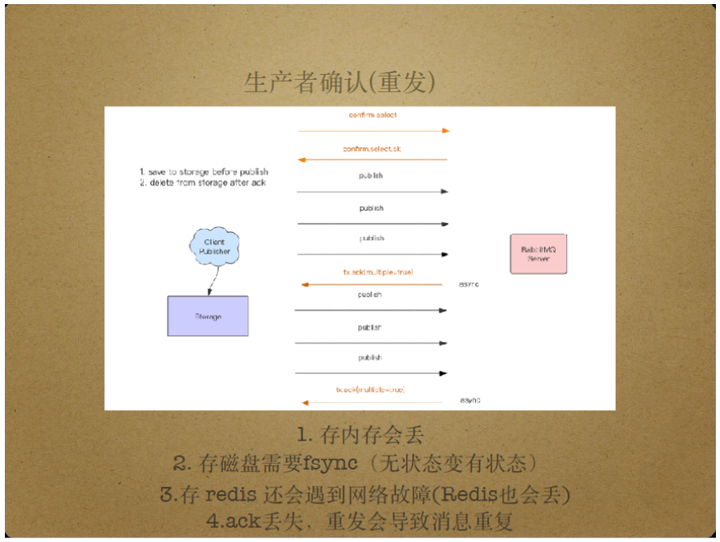
生产者确认中的消息重发可以通过以下几种方法实现。
第一种方式在内存中累积还未收到Ack包的消息,收到Ack包后删除该消息,对于一段时间内还停留在内存中的消息,重发该消息。
这种方式将未Ack消息存入内存,一旦消息生产者宕机,这些消息也会丢失。
另一种方式将未收到Ack包消息存入磁盘,当收到Ack包后删除该消息,然而,磁盘存储依赖于fsync操作,降低了系统处理消息的性能。
同时,这还会提高编程的复杂度,因为这要求发布消息时维护文件队列,还要求一个异步线程将文件队列中的消息发布到Server,带来了多线程和锁问题。
还有一种方式将未Ack消息存入Redis,但当出现网络故障时,Redis也是不可靠的。
目前提供的生产者确认中的消息重发方案都还存在问题,具体的方案选择依赖于实际场景和个人取舍。
生产者确认中的消息重发可以通过以下几种方法实现。
第一种方式在内存中累积还未收到Ack包的消息,收到Ack包后删除该消息,对于一段时间内还停留在内存中的消息,重发该消息。这种方式将未Ack消息存入内存,一旦消息生产者宕机,这些消息也会丢失。
另一种方式将未收到Ack包消息存入磁盘,当收到Ack包后删除该消息,然而,磁盘存储依赖于fsync操作,降低了系统处理消息的性能。同时,这还会提高编程的复杂度,因为这要求发布消息时维护文件队列,还要求一个异步线程将文件队列中的消息发布到Server,带来了多线程和锁问题。
还有一种方式将未Ack消息存入Redis,但当出现网络故障时,Redis也是不可靠的。目前提供的生产者确认中的消息重发方案都还存在问题,具体的方案选择依赖于实际场景和个人取舍。
死信队列

死信队列使用了RabbitMQ中的一种特殊队列属性,即x-message-ttl属性,表示队列中消息的构建时间。
假如用户在声明队列时定义队列的x-message-ttl属性,此后所有进入该队列的消息都将持有构建时间,到达构建时间的消息将被删除。
如果还为队列配置了回收站属性,那么即使构建时间到达,RabbitMQ也不会立即删除这些消息,而是将这些过期消息丢入回收站,即死信队列。
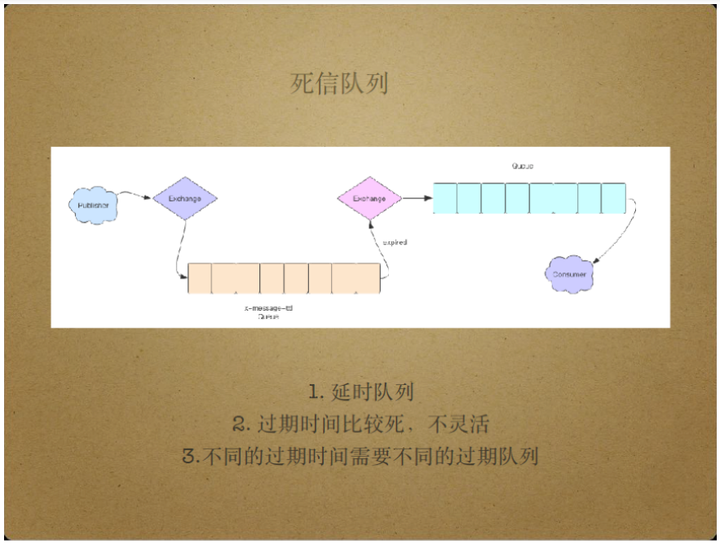
死信队列的工作方式如上图。
Client Publisher将消息投递给路由器,也就是exchange,再由exchange将消息投递给队列,由队列生成该消息的构建时间,到达构建时间的消息将过期,同时进入死信队列。
过期消息进入死信队列的方式和进入普通队列的方式基本一致,即先投递给exchange路由器,再由exchange投递消息。
消费者消费死信队列,得到的消息是延后的消息,延迟的时间长度即构建时间。
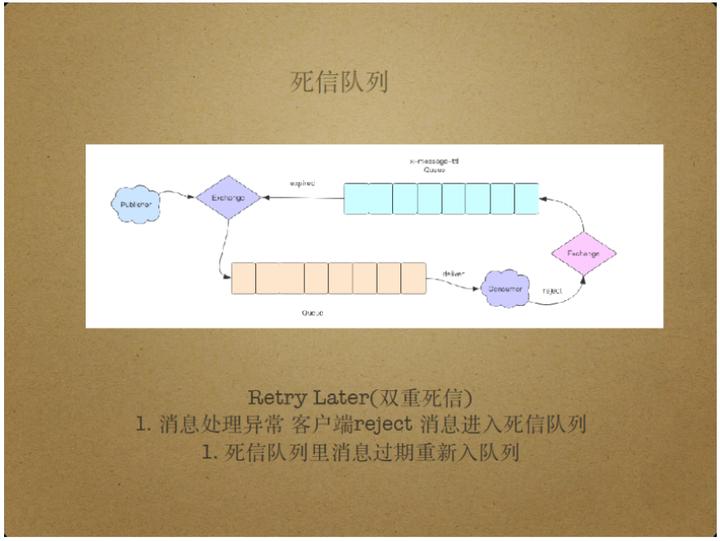
死信队列的另一个使用场景是Retry Later,即在一段时间后才重新处理此前处理失败的消息,这时可能用到双重死信。
具体来说,死信队列不仅可以接收过期消息,还可以接收被reject的消息,即消费端拒绝处理或处理过程发生异常的消息,Reject操作具有requeue参数,当requeue设为true时被reject消息会重新进入消息队列并被重新投递,当requeue设为false时被reject消息将进入死信队列。
假如死信队列持有构建时间,那么到达构建消息的消息将重新投递给原有队列,实现Retry Later。双重死信在使用过程中需注意消息处理的死循环问题,因为消息可能无限循环地进入死信队列。
生产环境下使用RabbitMQ应注意的事项
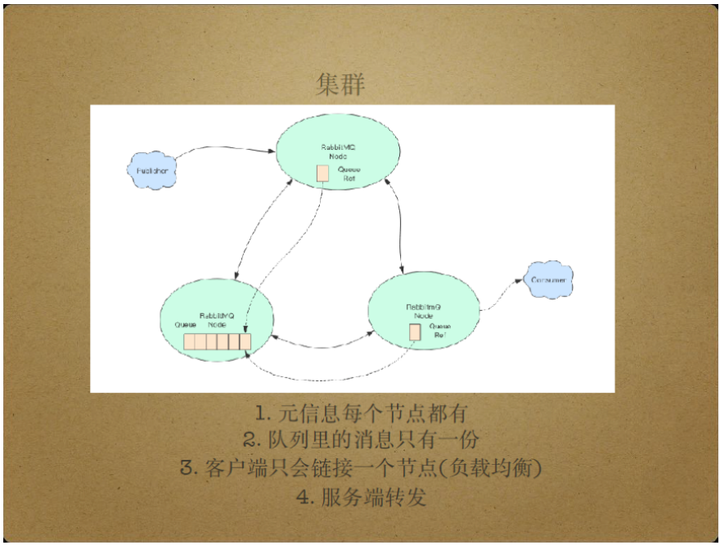
生产环境下,RabbitMQ通过使用集群模式。
集群模式下,只有元信息分布在所有节点中。
元信息指队列信息,路由器信息等,队列中的信息只存储在一个节点中,因此,单个节点宕机会导致所有节点都不可用。
另外,RabbitMQ的所有节点间存在转发机制,即允许节点转发其他目标节点的消息处理请求,这样客户端只需连接到任意一个节点就可以实现其消息转发需求。
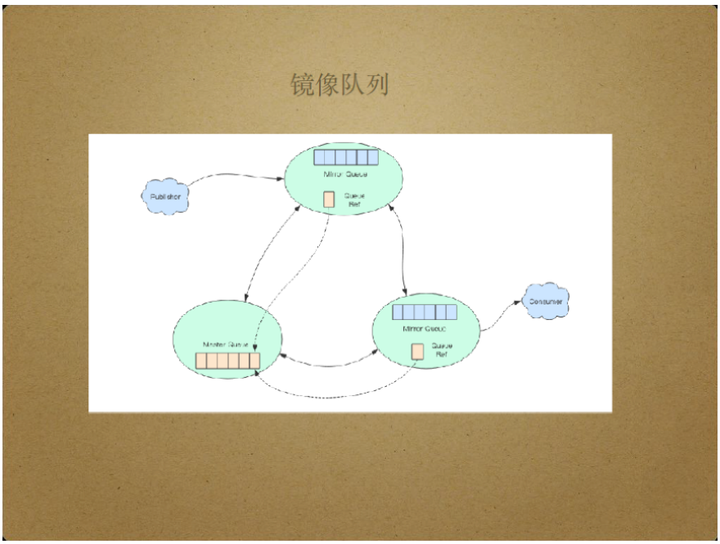
队列的高可用依赖于RabbitMQ的镜像队列,即在其他节点上备份某节点的消息内容。这样,当消息所在主节点宕机时,其他镜像节点可以替代主节点完成消息传递任务。

通常情况下,镜像节点是默默无闻的,客户端无需感知镜像节点的存在。只有当主节点宕机时,镜像节点才发挥作用。镜像队列的配置如下:
Ha-mode具有三个选项,all指将所有队列的信息存入所有节点,这种模式最安全,但也最浪费存储空间;exactly指由用户精确指定每个队列的复制数,当ha-mode设置为exactly,ha-params设置为2时表示“一主一从”,这种模式是官方推荐的;nodes指由用户指定副本所在的节点,这种模式极少被使用。
x-queue-master-locator用于设置存储队列主节点的RabbitMQ节点。min-master指将队列主节点设置在队列数量最少的RabbitMQ节点,client-local指将队列主节点设置在当前客户端所在的RabbitMQ节点,random即随机选择节点。
Ha-sync-mode用于镜像节点代替宕机主节点并创建新节点以弥补缺失节点时,设置新节点上数据的同步策略。automatic指自动地将新主节点上数据全部同步给新节点,manual指不同步新主节点上的老数据,只同步新产生的数据。由于节点间数据同步需要耗费时间,长时间的数据同步可能会影响服务的稳定性,但通常情况下RabbitMQ的节点堆积的数据量并不大,因此RabbitMQ官方推荐使用Automatic进行数据同步。
Ha-sync-batch-size指节点间批量同步的数据量。
Ha-promote-on-shutdown表示主动停止主节点的服务时,其他节点如何替代主节点。Always指其他节点总是能顺利地替代主节点,when-synced要求与原主节点数据完全一致的节点才能替代主节点。
Ha-promote-on-failure表示异常情况下其他节点如何替代主节点,always和when-synced的含义与Ha-promote-on-shutdown中一致。

许多公司为RabbitMQ集群设置了内存模式,认为内存模式无需落盘,能够提升系统性能。但实际上,RabbitMQ官方文档指出,内存模式无法提升系统性能,它只提升了产生元信息数据的速度,即Ram Node指将元信息存入内存,可以提升元信息的创建速度,而不是消息数据的性能。这是使用RabbitMQ时的一个常见误区。
如果你需要钱老师的 PPT 可以在公众号后台回复关键字 01,即可领取。
原文链接:https://developer.aliyun.com/article/699886
你好呀,我是歪歪。一个主要敲代码,经常怼文章,偶尔拍视频的成都人。
我没进过一线大厂,沒创过业,也没写过书,更不是技术专家,所以也没有什么亮眼的title。
当年以超过二本线 13 分的优异成绩顺利进入某二本院校计算机专业,误打误撞,进入了程序员的行列,开始了运气爆棚的程序员之路。
说起程序员之路还是有点意思,可以看看。点击蓝字,查看我的程序员之路