TextRank的灵感来源于PageRank算法,这是一个用作网页重要度排序的算法。
并且,这个算法也是基于图的,每个网页可以看作是一个图中的结点,如果网页A能够跳转到网页B,那么则有一条A->B的有向边。这样,我们就可以构造出一个有向图了。
然后,利用公式:
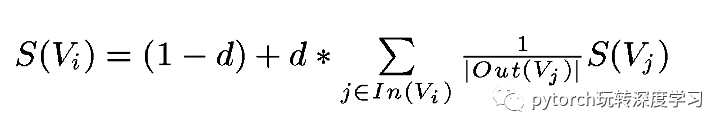
经过多次迭代就可以获得每个网页对应的权重。下面解释公式每个元素的含义:

能够跳转到的页面,在图中对应出度的点。
可以发现,这个方法只要构造好图,对应关系自然就有了,这实际上是一个比较通用的算法。那么对于文本来说,也是同样的,只要我们能够构造出一个图,图中的结点是单词or句子,只要我们通过某种方法定义这些结点存在某种关系,那么我们就可以使用上面的算法,得到一篇文章中的关键词or摘要。
使用TextRank提取关键词
提取关键词,和网页中选哪个网页比较重要其实是异曲同工的,so,我们只需要想办法把图构建出来就好了。
图的结点其实比较好定义,就是单词喽,把文章拆成句子,每个句子再拆成单词,以单词为结点。
那么边如何定义呢?这里就可以利用n-gram的思路,简单来说,某个单词,只与它附近的n个单词有关,即与它附近的n个词对应的结点连一条无向边(两个有向边)。
另外,还可以做一些操作,比如把某类词性的词删掉,一些自定义词删掉,只保留一部分单词,只有这些词之间能够连边。
下面是论文中给出的例子:
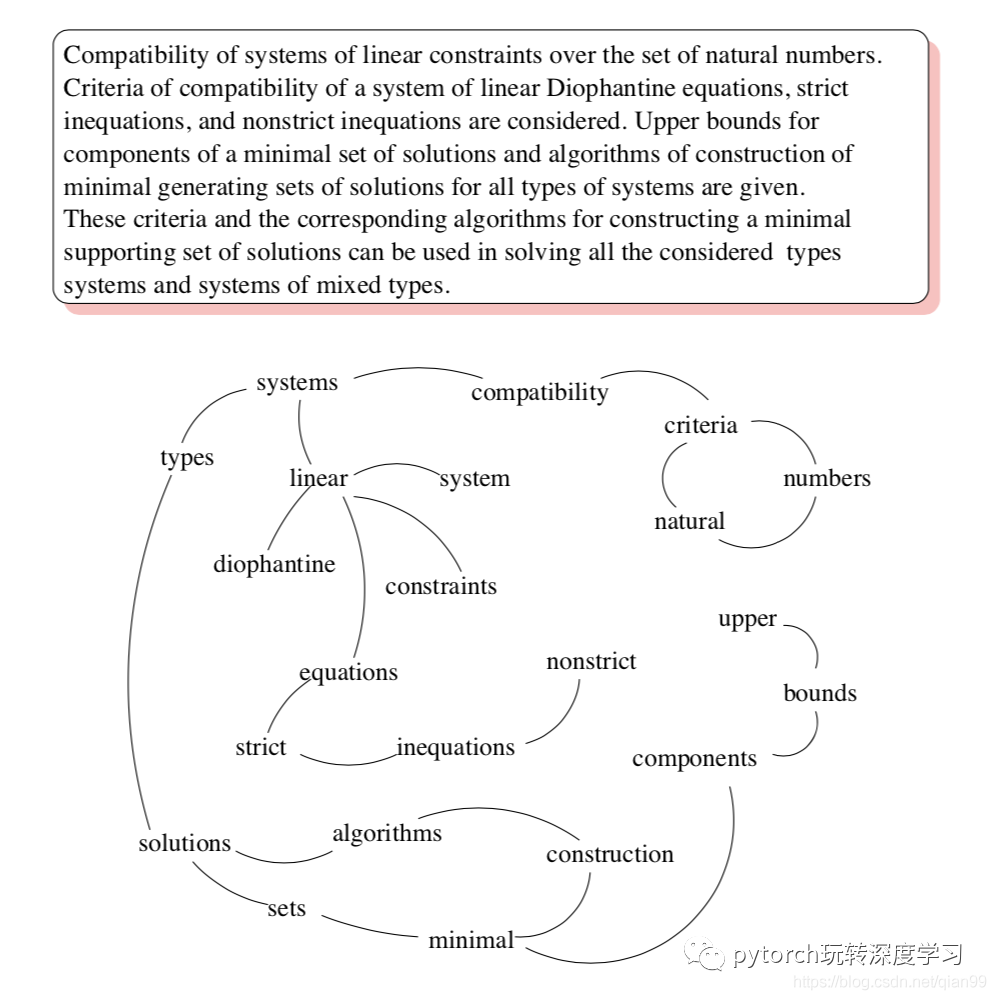
当构图成功以后,就可以利用上面的公式进行迭代求解了。
使用TextRank提取文章摘要
提取关键词以单词为结点,很显然,提取文章摘要自然就是以句子为结点了。那么边呢?如何定义呢?上面的方法似乎不是很适用了,因为两个句子即使相邻,也可以去讲完全不同的两件事。
在论文里,作者给出了一个方法,那就是计算两个句子的相似度。我的理解是这样的,这个计算相似度,其实就是一个比较粗略的方法来判断这两个句子是不是在讲同一个事情,如果两个句子是讲同一个事情,那么肯定会使用相似的单词之类的,这样就可以连一个边了。
既然有了相似度,那么就会有两个句子很相似,两个句子不太相似的情况了,因此,连的边也需要是带权值的边了。
下面是论文中给出的相似度的公式:
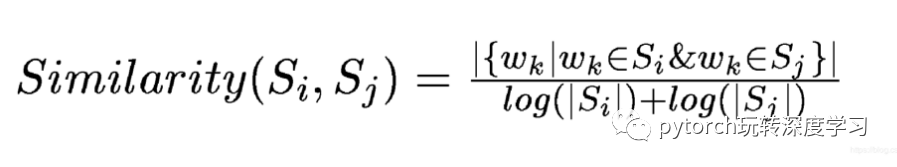
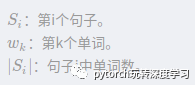
简单来说就是,两个句子单词的交集除以两个句子的长度(至于为什么用log,没想明白,论文里也没提)。然后还有一点,就是,其他计算相似度的方法应该也是可行的,比如余弦相似度,最长公共子序列之类的,不过论文里一笔带过了。
由于使用了带权的边,因此公式也要进行相应的修改:
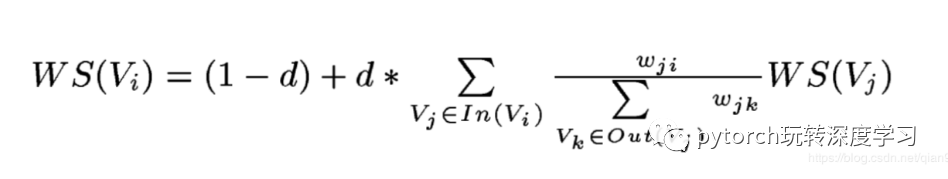
上面的公式基本上就是把原来对应边的部分添加了权重,边的数量和改成了权重和,很好理解。
