
一个缺失值可视化处理神器
数据预处理之缺失值可视化处理
每次处理数据时,缺失值是必须要考虑的问题。但是手工查看每个变量的缺失值是非常麻烦的一件事情。
missingno 提供了一个灵活且易于使用的缺失数据可视化和实用程序的小工具集,使您可以快速直观地总结数据集的完整性。
我们使用python来进行演练
1、首先安装程序包并加载:
pip install missingno
import missingno as msno
2、导入训练数据集
import pandas as pd
import numpy as ny
data=pd.read_csv("model.csv")
3、无效矩阵的数据密集显示
msno.matrix(data, labels=True)
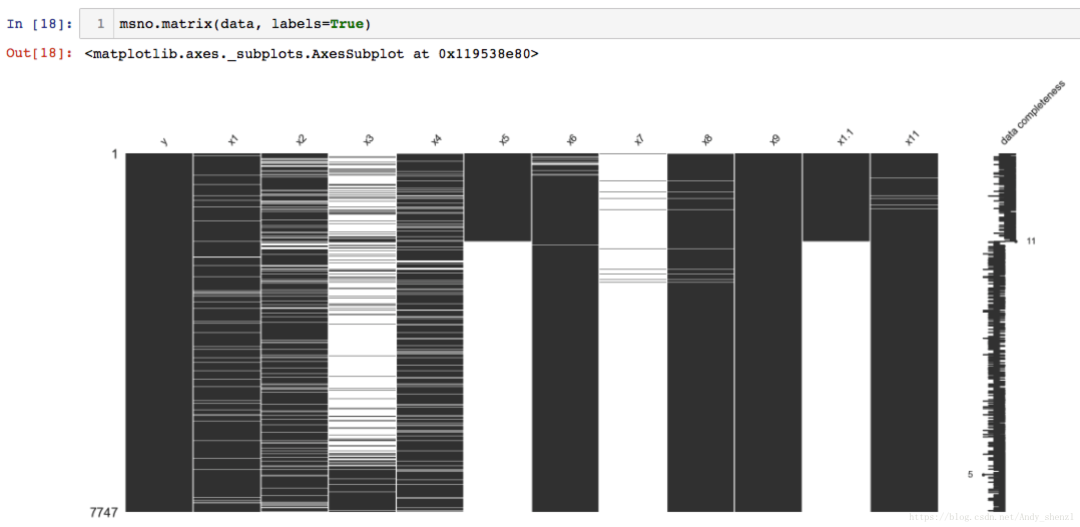
可以快速直观地挑选出图案的数据完成
我们可以一目了然的看到每个变量的缺失情况,
变量y,X9数据是完整的,其他变量都有不同程度的缺失,
尤其是X3,X5,X7等的缺失非常严重
4、条形图
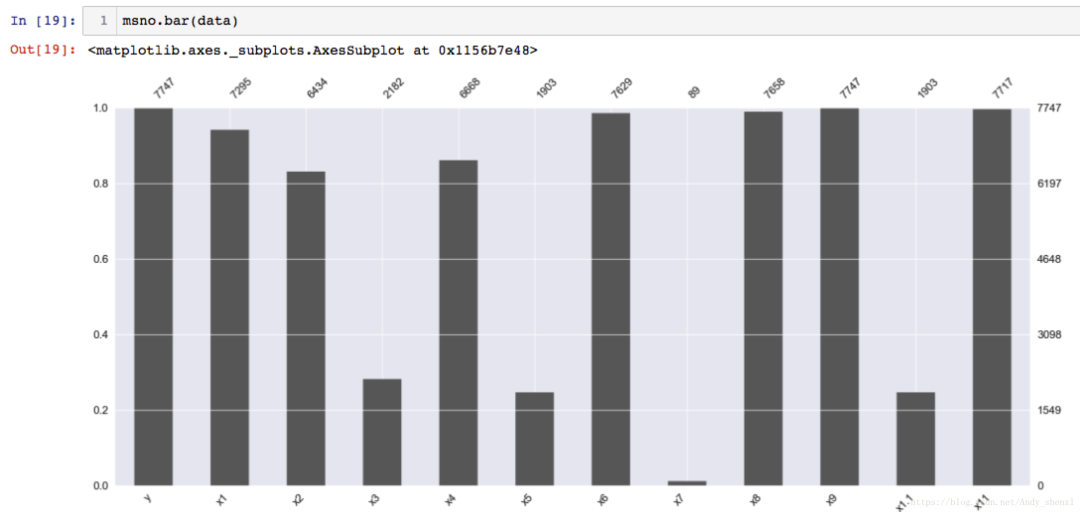
msno.bar(data)
msno.bar 是列的无效的简单可视化:
利用条形图可以更直观的看出每个变量缺失的比例和数量情况。
5、热图相关性
msno.heatmap(data)
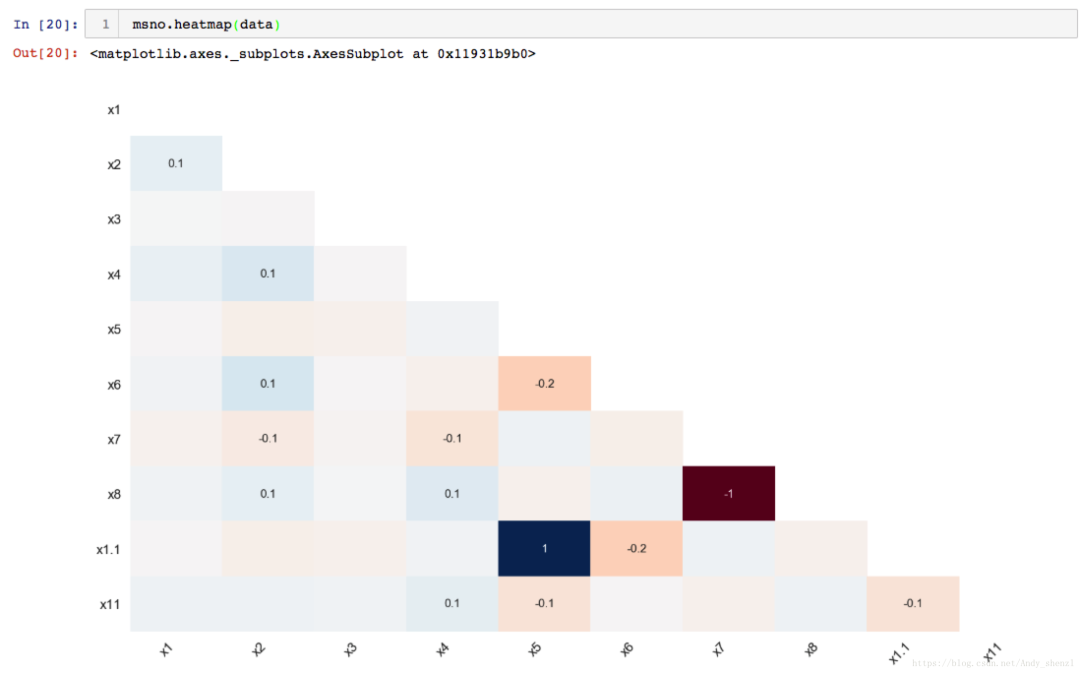
missingno相关性热图措施无效的相关性:一个变量的存在或不存在如何强烈影响的另一个的存在:
我们看到X5与X1.1的缺失相关性为1,说明X5只要发生了缺失,那么X1.1也会缺失,
X7和X8的相关性为-1,说明X7缺失的值,那么X8没有缺失;而X7没有缺失时,X8为缺失。
6、树状图
msno.dendrogram(data)
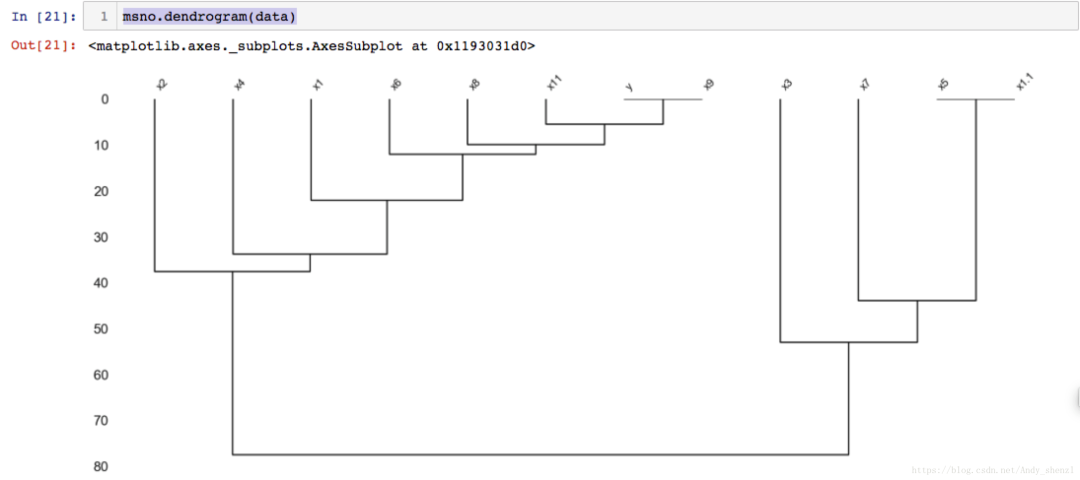
树形图使用层次聚类算法通过它们的无效性相关性(根据二进制距离测量)将变量彼此相加。在树的每个步骤,基于哪个组合最小化剩余簇的距离来分割变量。变量集越单调,它们的总距离越接近零,并且它们的平均距离(y轴)越接近零。
总体上,图标分为两个大类,一类是数据比较完整的,一类是缺失值比较多的。
要解释此图表,要从上往下的角度阅读。
左边数据是比较完整的一类,Y和X9是完整的数据,没有缺失值,所以他们的距离为0;相对于其他变量X11也是比较完整的,距离要比其他变量小,所以先把X11加进来。其他变量以此类推。
右边是缺失值比较严重的,热图相关性里面我们看到了X5和X1.1的相关性系数为1,所以他们的距离为0,首先聚在一起;之后再跟其他进行计算距离,把距离较近的X7加进来,以此类推。
文章参考:https://blog.csdn.net/Andy_shenzl/article/details/81633356