
如何解决图像分类中的类别不均衡问题?不妨试试分开学习表征和分类器
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达

在图像分类任务中类别不均衡问题一直是个难点,在实际应用中大部分的分类样本很可能呈现长尾分布。新加坡国立大学和 Facebook AI 的研究者提出了一种新型解决方案:将表征学习和分类器学习分开,从而寻找合适的表征来最小化长尾样本分类的负面影响。该论文已被 ICLR 2020 接收。


论文链接:https://openreview.net/pdf?id=r1gRTCVFvB
GitHub 链接:https://github.com/facebookresearch/classifier-balancing
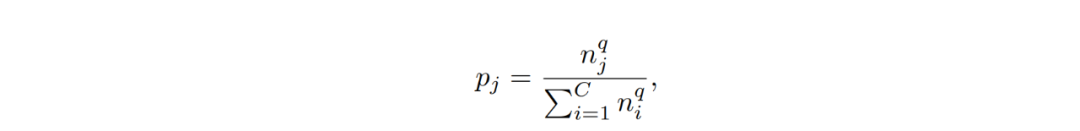
样本均衡采样(Instance-balanced sampling):该方法最为常见,即每一个训练样本都有均等的机会概率被选中,即上述公式中 q=1 的情况。
类别均衡采样(Class-balanced sampling):每个类别都有同等的概率被选中,即公平地选取每个类别,然后再从类别中进行样本选取,即上述公式中 q=0 的情况。
平方根采样(Square-root sampling):本质上是之前两种采样方式的变种,通常是将概率公式中的 q 定值为 0.5。
渐进式均衡采样(Progressively-balanced sampling):根据训练中的迭代次数 t(epoch)同时引入样本均衡(IB)与类别均衡(CB)采样并进行适当权重调整的一种新型采样模式,公式为
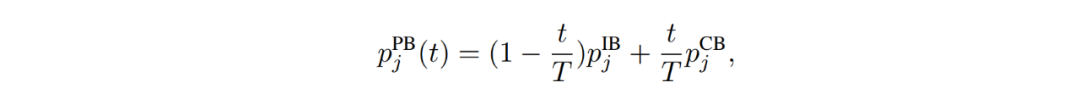
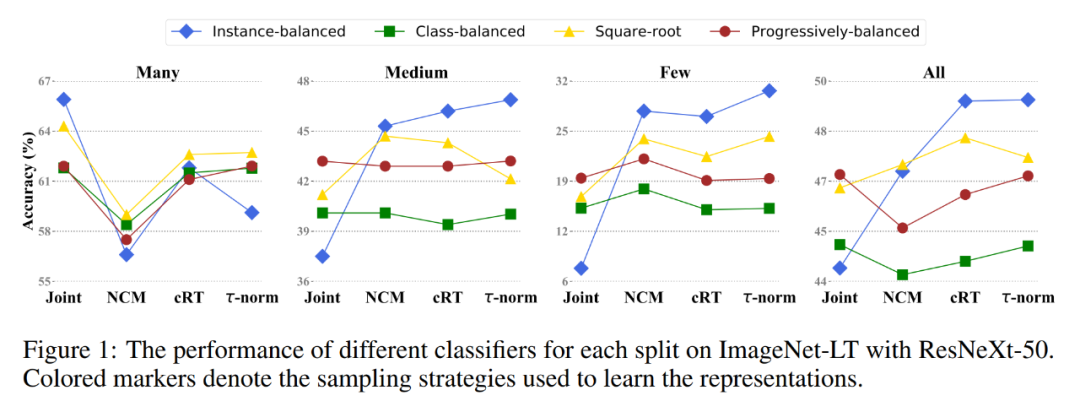
重训练分类器(Classifier Re-training, cRT):保持表征固定不变,随机重新初始化分类器并进行训练。
最近类别平均分类器(Nereast Class Mean classifier, NCM):首先计算学习到的每个类别特征均值,然后执行最近邻搜索来确定类别。
τ-归一化分类器(τ-normalized classifier):作者提出使用该方法对分类器中的类别边界进行重新归一化,以取得均衡。
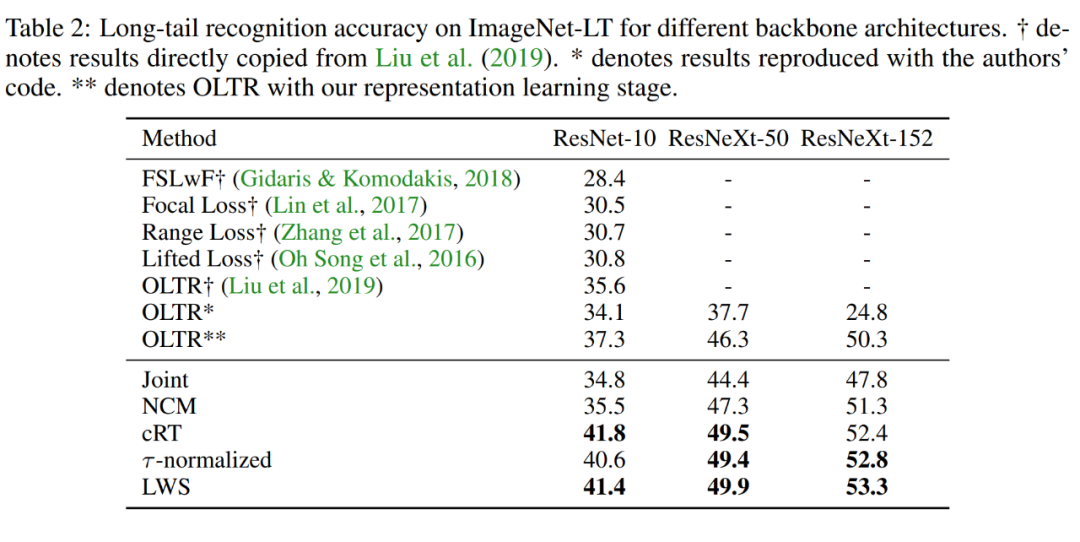
学习过程中保持网络结构(比如 global pooling 之后不需要增加额外的全连接层)、超参数选择、学习率和 batch size 的关系和正常分类问题一致(比如 ImageNet),以确保表征学习的质量。
类别均衡采样:采用多 GPU 实现的时候,需要考虑使得每块设备上都有较为均衡的类别样本,避免出现样本种类在卡上过于单一,从而使得 BN 的参数估计不准。
渐进式均衡采样:为提升采样速度,该采样方式可以分两步进行。第一步先从类别中选择所需类别,第二步从对应类别中随机选择样本。
重新学习分类器(cRT):重新随机初始化分类器或者继承特征表示学习阶段的分类器,重点在于保证学习率重置到起始大小并选择 cosine 学习率。
τ-归一化(tau-normalization):τ 的选取在验证集上进行,如果没有验证集可以从训练集模仿平衡验证集,可参考原论文附录 B.5。
可学习参数放缩(LWS):学习率的选择与 cRT 一致,学习过程中要保证分类器参数固定不变,只学习放缩因子。
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!