
2021年了,Redis复制原理你应该理解!
点击上方 好好学java ,选择 星标 公众号
重磅资讯,干货,第一时间送达 今日推荐:14 个 github 项目!
个人原创100W +访问量博客:点击前往,查看更多
作者:JingQ
https://www.sevenyuan.cn/
Redis的单机模式不难,配置文件参数了解具体含义,设定业务上符合自己的就好了。
之前记录了关于Redis的数据结构和对象的知识(可以点Redis标签看看),下面开始填坑。
复制
在Redis中,用户可以通过执行 SLAVEOF 命令或者设置 slaveof 选项,让一个服务去复制(replicate)另一个服务器。「被复制」的服务器为「主服务器(master)」,另一「个对主服务器进行复制」的服务器则被称为「从服务器(slave)」
举个🌰:(Redis版本是4.0.8)
在6379端口启动一个redis-server:
$ redis-server --port 6379
$ redis-cli -p 6379
127.0.0.1:6379>
在6380端口号启动一个redis-server,接着通过slaveof命令进行复制
$ redis-server --port 6380
$ redis-cli -p 6380
127.0.0.1:6380> slaveof 127.0.0.1 6379
OK
在这里,6379 是主服务器,6380 是从服务器。
接着能在 6380 的 redis-server 界面中看到日志:
19092:S 23 Mar 01:00:26.944 * Before turning into a slave, using my master parameters to synthesize a cached master: I may be able to synchronize with the new master with just a partial transfer.
19092:S 23 Mar 01:00:26.945 * SLAVE OF 127.0.0.1:6379 enabled (user request from 'id=2 addr=127.0.0.1:60778 fd=8 name= age=50 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=32768 obl=0 oll=0 omem=0 events=r cmd=slaveof')
19092:S 23 Mar 01:00:27.234 * Connecting to MASTER 127.0.0.1:6379
19092:S 23 Mar 01:00:27.234 * MASTER <-> SLAVE sync started
19092:S 23 Mar 01:00:27.234 * Non blocking connect for SYNC fired the event.
19092:S 23 Mar 01:00:27.246 * Master replied to PING, replication can continue...
19092:S 23 Mar 01:00:27.246 * Trying a partial resynchronization (request 2e56cf1343f6b2e864c968bd59b4a16ed78b8f1d:1).
19092:S 23 Mar 01:00:27.266 * Full resync from master: bf36b20c3942e91ac4f262a2afdc90970b2d7c54:0
19092:S 23 Mar 01:00:27.266 * Discarding previously cached master state.
19092:S 23 Mar 01:00:27.441 * MASTER <-> SLAVE sync: receiving 187 bytes from master
19092:S 23 Mar 01:00:27.442 * MASTER <-> SLAVE sync: Flushing old data
19092:S 23 Mar 01:00:27.442 * MASTER <-> SLAVE sync: Loading DB in memory
19092:S 23 Mar 01:00:27.442 * MASTER <-> SLAVE sync: Finished with success
具体流程如下:
从服务器发送 「SYNC 命令」到主服务器
主服务器通过 BGSAVE(子线程中运行)生成 RDB 文件,发送给从服务器
主服务器在 BGSAVE 过程中的写操作,保存在缓冲区中,发送给从服务器
进行复制中的主从服务器双方的数据库将保存相同的数据,概念上将这种现象称为**“数据库状态一致”,或者简称“一致”**。
旧版复制功能的缺陷
旧版指的是2.8之前
在Redis中,从服务器对主服务器的复制可以分成两种情况:
「初次复制」:从服务器从前没有复制过任何主服务器,或者从服务器当前要复制的主服务器和上一次复制的主服务器不同。
「断线后重新复制」:处于命令传播阶段的主从服务器因为网络原因而中断了复制,但从服务器通过自动重连接重新连上了主服务器,继续复制主服务器。
对于初次复制来说来说,旧版复制完全没有问题,但是断线重连之后,如果当时从服务器已经复制了一些,重连之后,从服务器需要重新复制,造成一些浪费。
「旧版使用的是SYNC命令进行复制」,是一个非常浪费资源的操作。
新版复制的优势
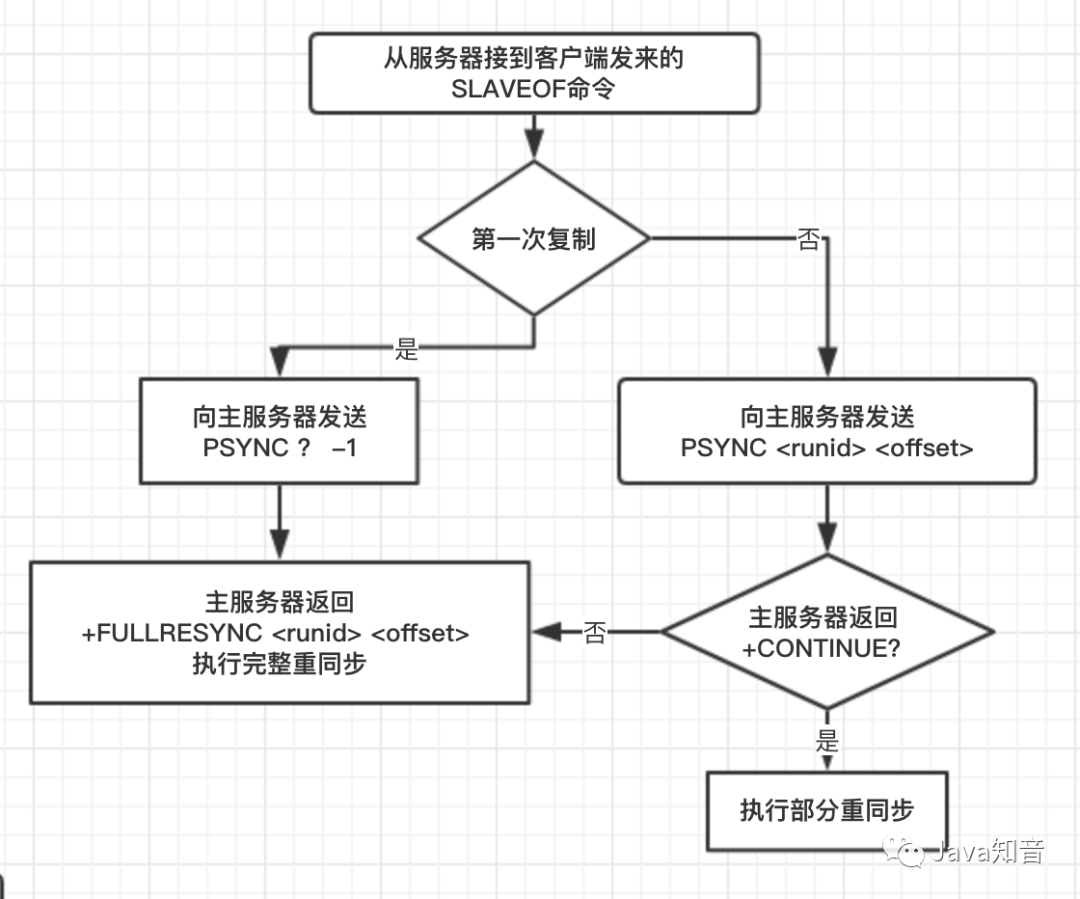
使用 PSYNC 命令替代 SYNC 命令来执行复制时的同步操作。
具有**完整重同步(full resynchronization)「和」部分重同步(partial resynchronization)**两种模式:
完整重同步:与初次复制相同,都是先让主服务器发送 RDB 文件,以及向从服务器发送保存在缓冲区里面的命令来进行同步。
部分重分步:当从服务器断线的时候,下次可以发起 PSYNC 命令,从中断处开始,执行部分重同步,只需要将从服务器缺少的写命令发送给从服务器执行就可以了,这时使用的资源比起执行 SYNC 命令所需的资源要少的多。
新版复制实现
部分重同步功能由以下三个部分构成:
主服务器的**复制偏移量(replication offset)**和从服务器的复制偏移量
主从服务器都各自持有一份复制偏移量。如果偏移量一致,表示处于一致状态;否则,两者处于不一致状态。
主服务器的「复制积压缓冲区((replication backlog)」
复制积压缓冲区是由主服务器维护的一个「固定长度(fixed-size)先进先出(FIFO)队列」,默认是1MB。
主服务器的复制积压缓冲区里面会保存着一部分最近传播的写命令,并且复制积压缓冲区会为队列中的每个字节记录相应的复制偏移量。
当从服务器重新连上主服务器时,从服务器会通过PSYNC命令将自己的offset发送给主服务器,主服务器会根据这个复制偏移量来决定对从服务器执行何种同步操作。
服务器的「运行ID(run ID)」
每个服务器都有自己的运行 ID,在服务器启动时自动生成,由 40 个堆积的十六进制字符组成。
当从服务器对主服务器进行初次复制时,主服务器会将自己的运行ID传送给从服务器,而从服务器则会将这个运行ID保存起来。
断线重连后,如果从服务器保存的运行 ID 与当前链接的主服务器的运行 ID 相同,主服务器会尝试执行「部分重同步操作」
相反的,如果不一致,主服务器将对从服务器执行「完整重同步操作」。
PSYNC命令实现
具体调用看流程图即可:
心跳检测
在命令传播阶段,从服务器默认会以每秒一次的频率,向主服务器发送命令:
$ REPLCONF ACK <replication_offset>
其中replication_offset是从服务器当前的复制偏移量。
发送REPLCONF ACK有三个作用:
检测主从服务器的网络连接情况
辅助实现min-slaves选项
检测命令丢失
小结
部分重同步通过「复制偏移量、复制积压缓冲区、服务器运行 ID」 三个部分来实现。
在复制操作刚开始的时候,从服务器会成为主服务器的客户端,并通过向主服务器发送命令请求来执行复制步骤,而在复制操作的后期,主从服务器互相成为对方的客户端。
主服务器通过向从服务器传播命令来更新从服务器的状态,保持主从服务器一致,而从服务器则通过向主服务器发送命令来进行心跳检测,以及命令丢失检测。
更多项目源码