
4个方面入手 TiledMap 地图优化!W字干货分享
引言:如何进行 TiledMap 地图优化?开发者 Bool Chen 将分享一套行之有效的 TiledMap 地图优化方案,其中包括了渲染、解析、寻路方面。
当项目里的地图越来越庞大和复杂,一些性能上的问题也开始逐渐出现。本文将从裁剪区域共享、Sprite 颜色数据去除、多图集渲染合批和分帧寻路四个方面,分享关于 TiledMap 地图的优化以及实现。
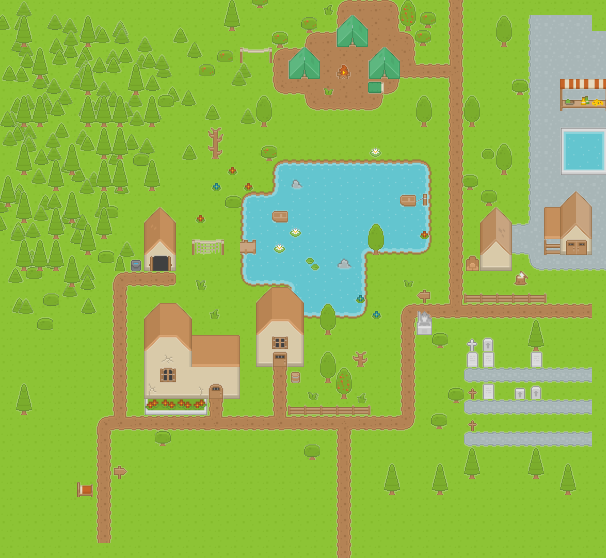
测试用例
本次的测试用例是这样的一张地图,有6个图层,其中4个图块层、2个物件层。测试的数据来源是在浏览器环境下,利用 console.time 和 timeEnd 函数,打印对应的逻辑耗时或渲染耗时,需要注意的是每次运行的耗时并不是一致的,但是在取均值后,可以认为是相对可靠的。
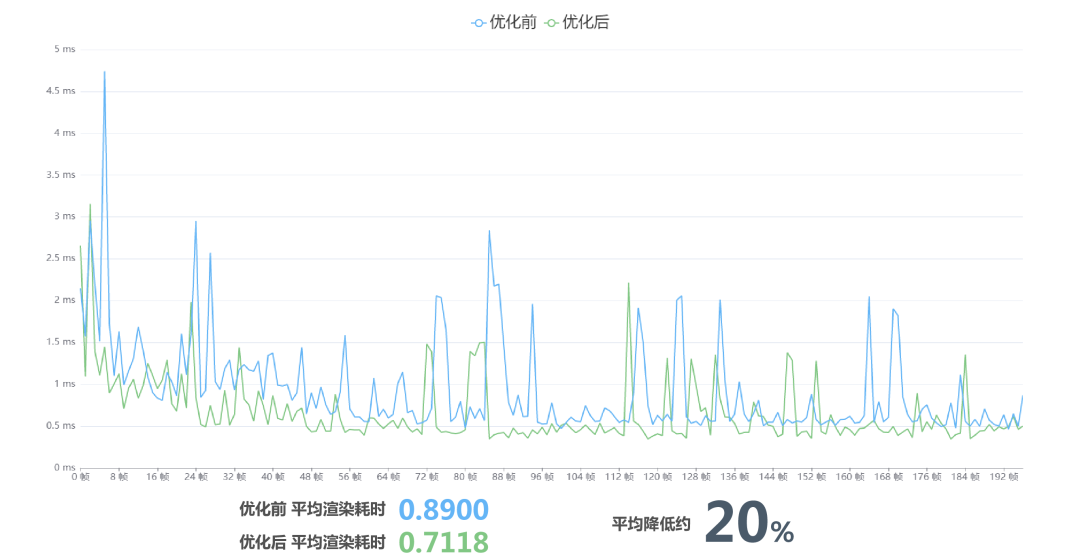
优化前后(注:横轴是游戏运行的帧数,纵轴是在该帧数下,对应的耗时,单位是毫秒)
上图是我们最后将裁剪区域共享+Sprite 颜色数据去除+多图集渲染合批一起使用后的优化效果,测试显示渲染耗时大约降低了20%左右。其实这张地图并不算复杂,如果物件数量、图层数量增加的话,优化效果会更加明显。
本次的主要优化方案参考自大城小胖的《如何重绘<江南百景图>》,文章介绍了很多性能优化技巧,强烈推荐大家去看看。项目基于 Cocos Cocos Creator 2.4.3,不过大部分优化思路在 v3.x 依旧适用。限于篇幅,本文仅呈现部分核心代码,完整代码及测试项目源码下载见文末。
裁剪区域共享
玩家操控人物在地图上移动的时候,地图显示的内容也需要跟随人物的位置发生改变。此时,为了优化性能,引擎会计算屏幕的可视范围,只有在可视范围内的图块才会被渲染。
研究引擎中 TiledMap 地图的渲染流程后我们发现,其实 TiledMap 本身并不是渲染组件,地图的渲染是通过图层 TiledLayer 实现的,其对应的渲染器是 TmxAssembler。渲染时,渲染流会逐个调用 TmxAssembler 的 fillBuffers 函数进行渲染数据填充,此函数中会调用 CCTiledLayer 的 _updateCulling 函数进行可视范围,只有可视范围发生改变才会进行渲染。
但是,在计算的时候,由于每个图层都有对应的 Assembler,所以每个图层都会单独计算一次。而一般情况下我们每个图层显示的范围是一致的,所以我们希望它只计算一次就好了。
接下来我们就来实现裁剪区域共享(Share Culling),让不同 TiledLayer 间,共享可视区域的裁剪计算结果,以此节约性能。
实现过程
首先我们继承 TiledMap,重写创建图层的 _buildLayerAndGroup 函数,实现创建自定义的 ShareCullingTiledLayer。
因为相对来说记录第一个图层实现起来更方便,所以我们缓存第一个图层,并将首个 TieldLayer 传递给后面的图层,方便后面去读取计算结果。
_buildLayerAndGroup() {
for (let i = 0, len = layerInfos.length; i < len; i++) {
if (layerInfo instanceof cc.TMXLayerInfo) {
// 创建自定义的ShareCullingTiledLayer
let layer = child.getComponent(ShareCullingTiledLayer);
// 传递、记录首个TiledLayer
layer._init(layerInfo, firstLayer);
firstLayer = firstLayer || layer;
}
}
}
接着修改 TiledLayer 的裁剪函数,一样通过重写的方式实现。
这里我们进行判断,如果是首个图层,我们才让他进行计算,并把结果缓存起来;如果不是首个图层,我们就直接读取首个图层的计算结果。
最后重写 TiledLayer 的裁剪函数,实现复用裁剪区域的功能。
_updateCulling() {
// this._firstLayer为空时 表示为首个layer
let firstLayer = this._firstLayer;
if (!firstLayer) {
// 进行裁剪区域计算
this._updateViewPort();
this._cacheCullingDirty = this._cullingDirty;
} else {
// 直接复用firstLayer的结果
this._cullingRect = firstLayer._cullingRect;
this._cullingDirty = firstLayer._cacheCullingDirty;
return;
}
}
很简单地我们就完成了这个优化。Share Culling 实现起来并不麻烦,但效果是显著的。
优化效果
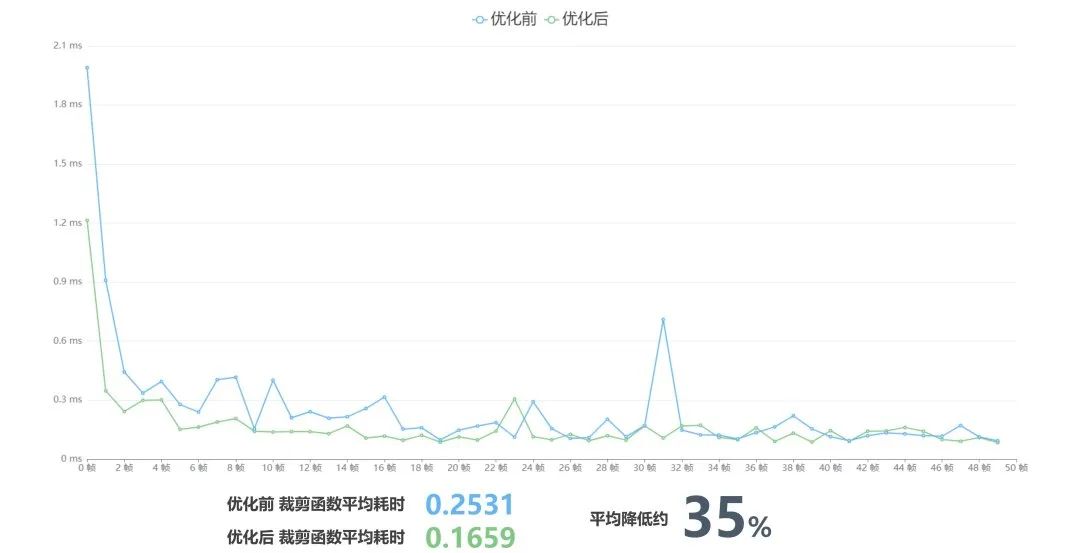
优化前后
可以看到即使只有6个图层的情况下,裁剪函数的平均耗时降低了35%左右,当图层数量增加的时候,优化效率会更高。
讲到裁剪区域,这里还有一个优化点。在初始化图块图层时,引擎会遍历整个地图的图块,将所有图块的信息保存起来,方便后续使用。这里可以改成区域加载,一开始只解析当前屏幕中的图块,随后在移动的时候,再动态解析行动方向上的图块——当然这个方案也有缺点,就是我们需要额外的内存空间保存对应的坐标是否已经解析过。
Sprite 颜色数据去除
接下来是物件颜色去除,这里我们用在地图物件上,但其实这个优化在所有 Sprite 组件中都是可以适用的。
Sprite 默认的渲染顶点数据中包含了颜色数据,但大部分情况下,美术给我们的素材我们都是直接放到游戏里,不会再对颜色做修改,此时 Color 数据似乎成了一个非必要的东西,将其去除掉可以减少 CPU 和 GPU 的数据传输,也可以省去着色器中对颜色的计算。
简单讲一下 Sprite 渲染流程。Sprite 组件会通过 resetAssembler 取得一个默认的 Assembler,而 Assembler 会通过 updateRenderData 函数,把 Sprite 的数据填充到 RenderData 中。最后引擎会帮我们把渲染数据传递给材质,进而进行渲染。
接着我们来看看怎么实现这个优化。
实现过程
我们从底层步骤往上看,首先是着色器。仿照内置的 Effect 及 Material 创建 Effect 和 Material,因为我们不再需要颜色了,所以只要把着色器中关于颜色的输入输出、计算等的代码去除即可。
// 删除颜色相关输入输出处理
CCProgram vs %{
in vec3 a_position;
// in vec4 a_color;
// out vec4 v_color;
void main () {
// v_color = a_color;
gl_Position = pos;
}
}%
// 删除颜色相关输入、计算
CCProgram fs %{
precision highp float;
// in vec4 v_color;
void main () {
vec4 o = vec4(1, 1, 1, 1);
CCTexture(texture, v_uv0, o);
// o *= v_color;
gl_FragColor = o;
}
}%
接着我们要提供不带颜色的渲染数据。继承 cc.Assembler 实现一个新的 Assembler。在 Assembler 中,首先要新建一个顶点数据格式,将默认的顶点格式中的颜色属性去掉。随后,为我们的新格式创建对应的顶点数据容器。
// 自定义顶点格式,去掉默认的颜色字段
let gfx = cc.gfx;
let vfmtNoColor = new gfx.VertexFormat([
{ name: gfx.ATTR_POSITION, type: gfx.ATTR_TYPE_FLOAT32, num: 2 },
{ name: gfx.ATTR_UV0, type: gfx.ATTR_TYPE_FLOAT32, num: 2 },
// { name: gfx.ATTR_COLOR, …},
]);/**
* 初始化this._renderData 创建自定义格式的renderData
*/
initData() {
let data = this._renderData = new cc.RenderData();
this._renderData.init(this);
// 按我们自己的格式创建renderData
data.createFlexData(0, 4, 6, vfmtNoColor);
}
最后,把渲染颜色的函数也移除掉。这样就完成了一个不带颜色的 Assembler。
/**
* 更新颜色 拜拜了😆
*/
// updateColor () {
// }
接着我们需要使用这个 Assembler。重写 Sprite 的 resetAssembler 函数,将默认的 Assembler 改成上面的 Assembler。
/**
* 修改默认Assembler
*/
_resetAssembler() {
let assembler = this._assembler = new NoColorSpriteAssembler();
assembler.init(this);
this.setVertsDirty();
},
如果你要运用在其他地方,只要给 Sprite 换上前面的 material 就可以了。
那么如何运用在地图物件中呢?我们通过继承实现一个 TiledObjectGroup,并重写 _init 函数。在里面,我们将默认的 Sprite 组件改成我们自定义的组件,并赋予对应的去除颜色的材质即可。
_init(groupInfo, mapInfo, texGrids, noColorMaterial) {
let objects = groupInfo._objects;
for (let i = 0, l = objects.length; i < l; i++) {
imgNode = new cc.Node();
let sp = imgNode.addComponent("NoColorSprite");
sp.setMaterial(0, noColorMaterial);
}
}
优化效果
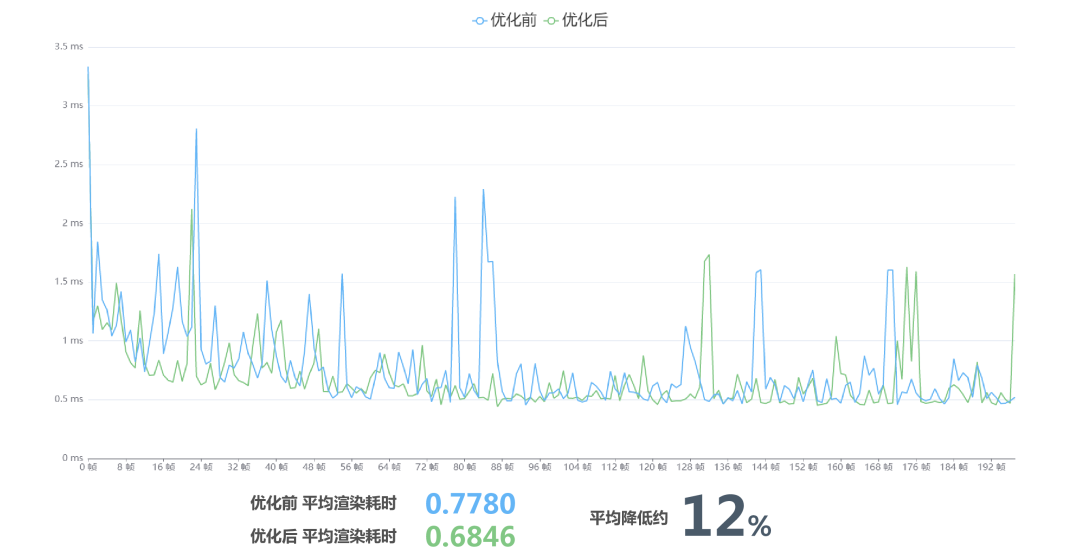
优化前后
最终优化效果,在大约有100多个组件的情况下,渲染耗时降低了约12%。我在测试优化效果的时候,发现这个数据有较大的浮动,范围大约是5-15%。
在逻辑层面,我们减少了颜色数据的填充,本身优化效果其实并不算大。其次,数据统计监听不到 CPU 和 GPU 数据传输的部分,也监听不到着色器优化的部分。
另外,颜色数据的去除还可以为我们接下来的地图物件多图集渲染合批做准备。
多图集渲染合批
物件常常是地图中不可或缺的一部分,世界观丰富起来之后,物件来自不同的图集也是很常见的,这个时候如果还要对物件进行排序,图集交错的情况下,非常容易产生大量的 DC。
优化 DC 的常见方案是打包图集,但当图片来自不同图集的时候,这个方案就无法进行了。多图集渲染合批是一个类似于打包图集的方案,我们在渲染的时候,一次传递多张图集,把原本的判断图片是否来自于同一张图集,转换为判断图片是否来自于同一批图集。
大部分手机设备都可以支持8张图集,所以理论上,只要使用的图集不超过8张,就可以只要1次 DC。
实现过程
首先一样需要修改着色器相关代码。我们同样复制一份内置 Effect,之后在 Effect 的声明中,增加一些 texture 参数,来接收多张图集数据。
CCEffect %{
techniques:
- passes:
- vert: vs
properties:
texture: { value: white }
texture1: { value: white }
texture2: { value: white }
texture3: { value: white }
// 4 5 6...
}%
随后,通过顶点数据传递 texture_index,表示当前使用的是哪张图集。这里在着色器代码中根据 texture_index 从不同的图集取值就可以了。
CCProgram fs %{
precision highp float;
in float texture_idx;
void main () {
vec4 o = vec4(1, 1, 1, 1);
#if USE_TEXTURE
if (texture_idx <= 1.0) {
CCTexture(texture, v_uv0, o);
} else if (texture_idx <= 2.0) {
CCTexture(texture1, v_uv0, o);
} else if (texture_idx <= 3.0) {
CCTexture(texture2, v_uv0, o);
}
// else ...
#endif
gl_FragColor = o;
}
}%
现在我们要想办法把这些数据传递给材质。
先说 texture_index。这个部分和前面的组件颜色去除有点类似,不过这次是增加数据。我们自定义新的顶点数据格式,在里面增加一个 a_texture_index 属性,之后创建一个新的顶点数据容器(注意 texture_index 声明的位置,一会儿我们会用到)。
let gfx = cc.gfx;
var vfmtPosUvColorIndex = new gfx.VertexFormat([
{ name: gfx.ATTR_POSITION, type: gfx.ATTR_TYPE_FLOAT32, num: 2 },
{ name: gfx.ATTR_UV0, type: gfx.ATTR_TYPE_FLOAT32, num: 2 },
{ name: "a_texture_idx", type: gfx.ATTR_TYPE_FLOAT32, num: 1 },
{ name: gfx.ATTR_COLOR, type: gfx.ATTR_TYPE_UINT8, num: 4, normalize: true },
]);
initData() {
let data = this._renderData = new cc.RenderData();
this._renderData.init(this);
data.createFlexData(0, 4, 6, vfmtPosUvColorIndex);
}
完事之后,我们就要往这个容器中写值,把数据传递给着色器。
新建 updateTextureIdx 函数,进行数据的填充。按照我们定义的顶点格式,在每个顶点的对应位置填充 texture_index 属性值。
随后找出填充顶点数据的 updateRenderData 函数,在里面增加对 updateTextureIdx 函数的调用,这样就完成了数据的填充。
// 填充textureIndex数据
updateTextureIdx(sprite) {
let textureIdx = sprite._textureIdx;
let verts = this._renderData.vDatas[0];
let verticesCount = this.verticesCount;
let floatsPerVert = this.floatsPerVert;
for (let i = 0; i < verticesCount; i++) {
let index = i * floatsPerVert + 4;
verts[index] = textureIdx;
}
}
updateRenderData(sprite) {
if (sprite._vertsDirty) {
this.updateUVs(sprite);
this.updateVerts(sprite);
this.updateTextureIdx(sprite);
sprite._vertsDirty = false;
}
}
接着是传递图集,我们为 objectGroup 传递一个 texture 变量,来保存所有物件图层使用到的图集。在创建完 objectGroup 之后,再按顺序地把图集传递给材质。
_buildLayerAndGroup: function () {
let layerInfos = mapInfo.getAllChildren ();
let textureSet = new Set();
for (let i = 0, len = layerInfos.length; i < len; i++) {
let layerInfo = layerInfos[i];
let group = child.getComponent("MutilObjectGroup");
group._init(this.objectMaterial, textureSet);
}
// 设置材质的texture属性
let objectTextures = Array.from(textureSet);
for (let i = 0; i < objectTextures.length; i++) {
let idx = i === 0 ? '' : i;
this.objectMaterial.setProperty(`texture${idx}`, objectTextures[i], 0);
}
}
接着看一下 objectGroup的部分。
我们实现新的 TiledObjectGroup,重写 _init 函数。
除了 textureSet,我们同时维护一个 textureIndexMap,来记录图集在 set 中的位置。新建 Sprite 组件的时候,动态地去更新 TextureSet 和 TextureIndexMap。
然后,我们利用 map 来获得 Sprite 的 texture_index。
需要注意的是,我们需要将材质的哈希值写死,否则更新图集后,一样会判定为不可合批。
_init(groupInfo, mapInfo, texGrids, material, textureSet) {
// texture资源 -> textureIndex
let textureIndexMap = new Map();
Array.from(textureSet).forEach((texture, idx) => textureIndexMap.set(texture, idx));
for (let i = 0, l = objects.length; i < l; i++) {
let sp = imgNode.getComponent("MutilSprite");
let spf = sp.spriteFrame;
// 收集所有图集
let size = textureSet.size;
textureSet.add(grid.tileset.sourceImage);
// 更新Map
if (size !== textureSet.size) {
textureIndexMap.set(grid.tileset.sourceImage, size)
}
sp.setMaterial(0, material);
// 设置textureIndex
let index = textureIndexMap.get(sp.spriteFrame._texture);
// 写死哈希值 使其可以合批
sp.getMaterial(0).updateHash(9999);
sp.setTextureIdx(index + 1);
}
}
优化效果
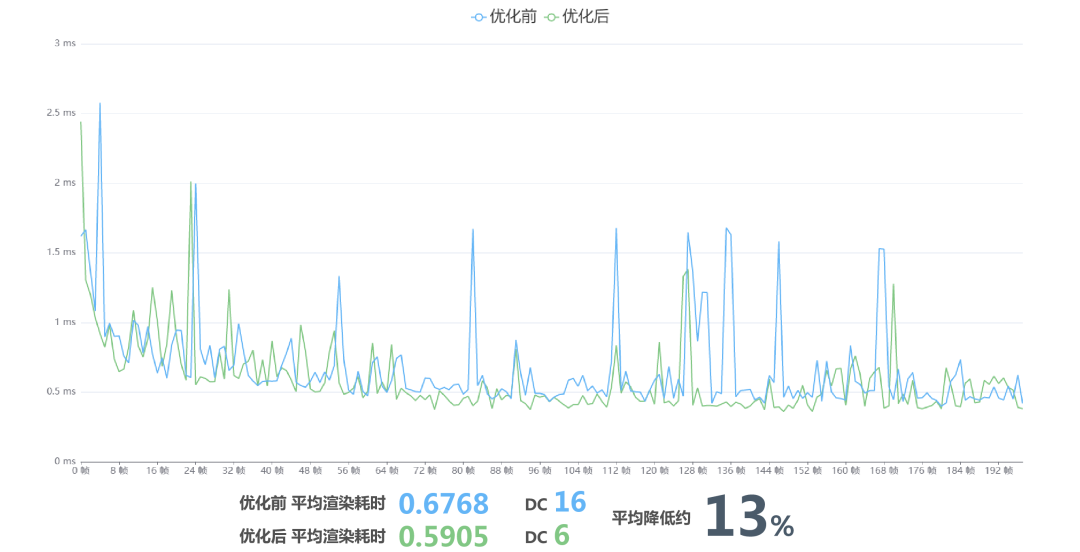
优化后,DC 从16降到了6,平均降低了13%的渲染耗时。而在复杂的环境下,不论物件产生了多少次 DC,最后的 DC 都会是6次,优化效果也会提升。
因为相对默认的渲染方式,我们额外增加了 texture_index 这个数据,这会有一点性能损耗。但是如果和前面的颜色去除结合起来使用,就可以抵消这个损耗,达到更好的优化效果。
此外,在图块图层也有类似记录图集的操作。
初始化时,需要获取图层用到的所有图集,并为他们创建对应的材质,这里需要遍历整张地图。这里是一个优化点,首先我们可以要求策划拼地图的时候每个图层只使用一个图集,这也可以避免多个图集导致的 DC 上升。在这之后,我们可以修改对应的代码,只要找到一个图集,就可以停止遍历了,避免多次完整遍历整张地图。
分帧寻路
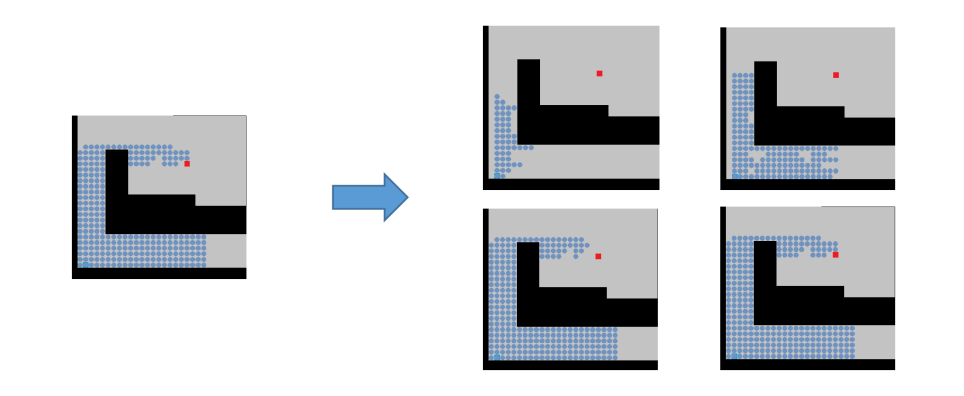
寻路是游戏中的重要部分,当地图面积增加时,寻路算法的损耗也会变成一个不可小视的部分。分帧的思路也是一个常见的优化方法,我们把一件复杂的工作拆成好几段,每帧做一段。它本身并没有减少运算的数量,但是可以帮你压平 CPU 的使用率曲线,避免突发的计算占用导致掉帧。
实现过程
在我们的寻路工具类里面提供一个接口,来进行寻路任务的提交。
因为分帧处理后,代码的执行变成异步的了,所以我们需要缓存寻路任务的数据以及进度,才能正确地接着上一帧的结果继续处理。
之后,我们在游戏中每帧调用对应的寻路函数,进行寻路的计算。
在进行路径计算的时候,我们每次访问路径点前,都先判断已访问的路径点数量,如果超出了数量,就不再进行寻路,等待下一帧的调用。
/**
* 开始一个寻路任务。此函数为外部调用入口
*/
findRoad(start, target, wall, callback, config) {
const { maxWalkPerFrame } = config;
this._maxWalkPointAmount = maxWalkPerFrame || Number.MAX_VALUE;
// ...存储数据
// 立即执行一次寻路
this._findPath();
}
/**
* 此函数应由外部引用者每帧调用
*/
update() {
this._findPath();
}
/**
* 执行一次寻路
*/
_findPath() {
let walkPointAmount = 0;
while (walkPointAmount++ < this._maxWalkPointAmount) {
// 访问路径点...
const point = this._waitQueue.poll();
}
}
优化效果
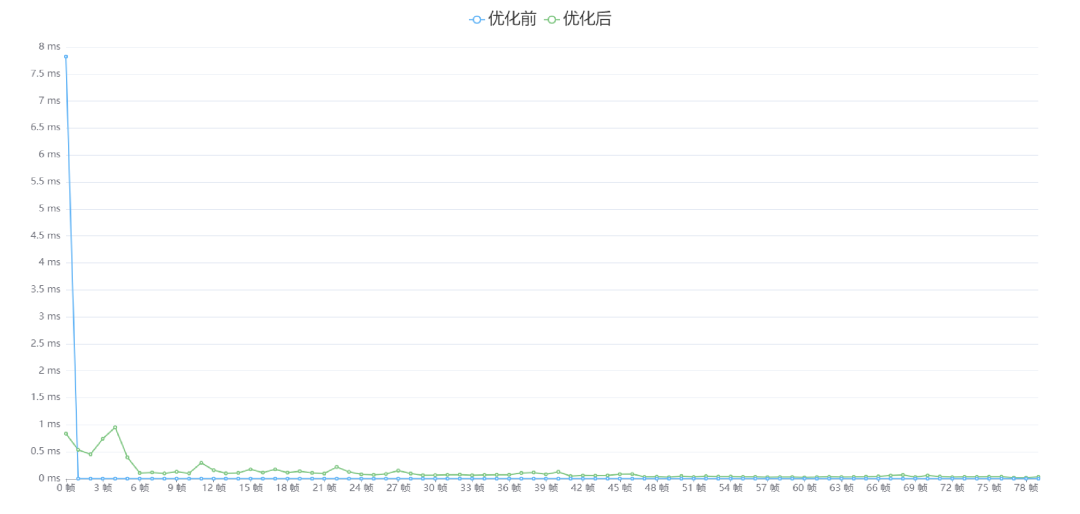
优化前后
测试用例是在游戏开始时,提交了四个寻路任务。可以看到优化前的时间消耗接近 8ms,这对我们来说是不可接受的。在优化后,最高的耗时也不过 1ms。相对来说是一个可以接受的数字。
除了分帧处理,我们还可以再进一步地进行优化。
比如游戏世界刚启动的时候,所有的 NPC 都需要进行随机移动,这个时候会有大量的 NPC 需要同时进行寻路运算,仍然会导致 CPU 占用率过高。这里有两个方案,一个是让 NPC 在不同的时机点开始移动,另一个是对寻路任务进行统一的管理。这里介绍一下后一个方案。
我们可以将提交的寻路任务保存到队列中。只有当寻路任务完成的时候,我们才从队列中取出新的任务。
/**
* 添加一个寻路任务。此函数为外部调用入口
* @param {FindRoadTask} task 寻路任务
*/
addFindRoadTask(task) {
if (this._finding) {
this._taskList.push(task);
} else {
this._startFindRoadTask(task);
}
}/**
* 寻路任务结束回调。不论寻路成功或失败都会调用本函数
*/
_onFindOver() {
if (!!this._taskList.length) {
this._startFindRoadTask(this._taskList.shift());
} else {
this._finding = false;
}
}
如此一来,就可以保证我们每帧同时只会执行一个任务,进一步地压平曲线。我们用同样的测试用例进行测试,结果如下。
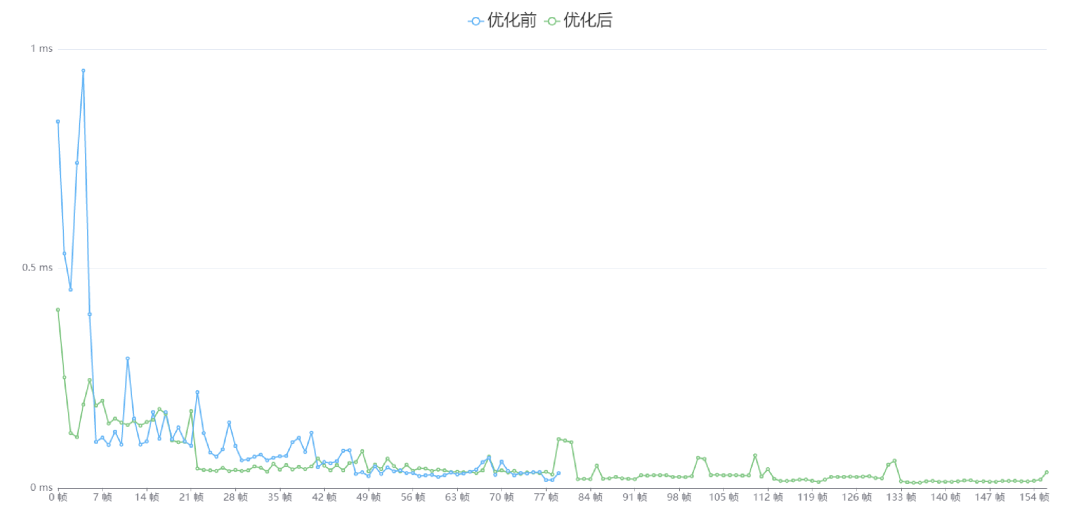
优化前后
需要注意一下,这里的蓝色线就是刚刚优化后的绿色线。可以看到绿色线又进一步地更平缓了,最高也不超过 0.5ms,我们可以不用再担心寻路会对帧数造成影响了。
总结与资源下载
如果把本文介绍的优化全做了是什么效果?
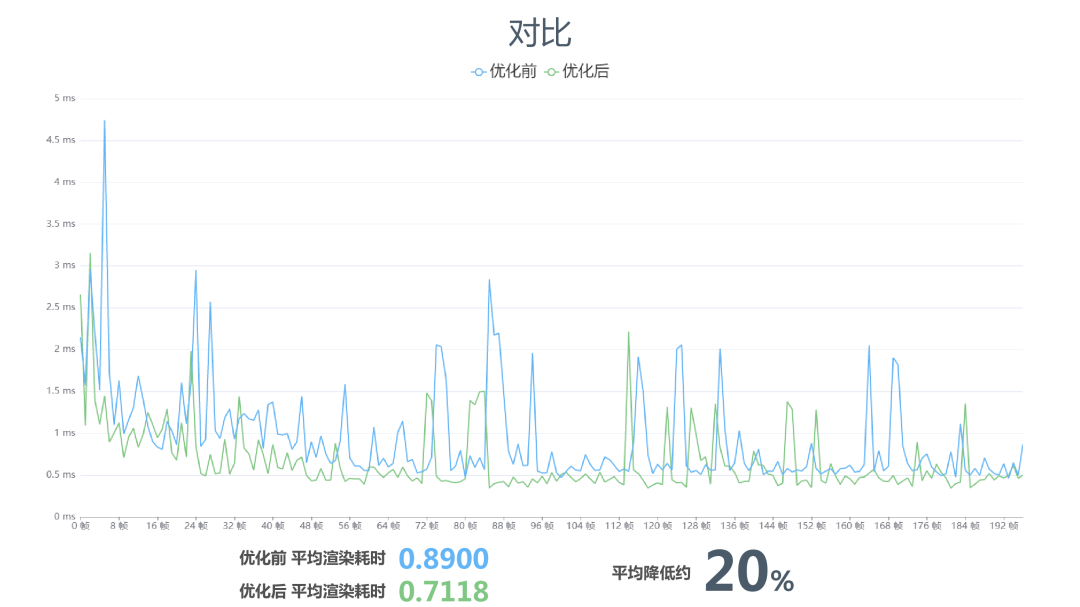
开头提到,这里我们测试了裁剪区域共享+颜色去除+多图集渲染合批,渲染耗时大约降低了20%左右。
完整代码与测试项目欢迎移步下方论坛专贴查看与下载,如有疑问、或是其他好的优化方案,都可以在论坛一起交流!
论坛专贴地址
裁剪区域共享(Share Culling):
https://forum.cocos.org/t/topic/134525
Sprite 颜色数据去除:
https://forum.cocos.org/t/topic/135235
多图渲染合批:
https://forum.cocos.org/t/topic/136349
分帧寻路+寻路任务统一管理:
https://forum.cocos.org/t/topic/134884
往期精彩