
Pandas知识点-Series数据结构介绍

一、Series数据结构介绍
# coding=utf-8
import pandas as pd
df = pd.read_csv('600519.csv', encoding='gbk')
data = df['收盘价']
print(data)
print(type(data))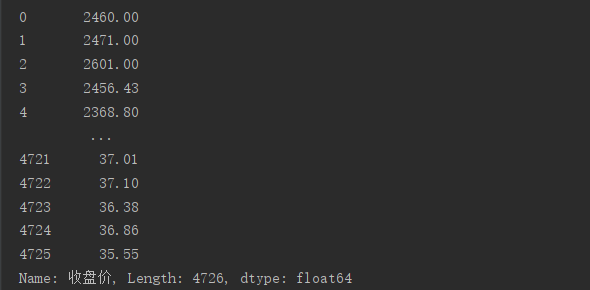
<class 'pandas.core.series.Series'>
二、创建Series和DataFrame
1. 创建Series
s1 = pd.Series({'a': 10, 'b': 20, 'c': 30, 'd': 40})
print(s1)
print(type(s1))a 10
b 20
c 30
d 40
dtype: int64
<class 'pandas.core.series.Series'>
import numpy as np
s2 = pd.Series(np.random.rand(5), index=[alpha for alpha in 'abcde'])
print(s2)
print(type(s2))a 0.269565
b 0.520705
c 0.419913
d 0.182670
e 0.031500
dtype: float64
<class 'pandas.core.series.Series'>
实例化一个Pandas中的Series类对象,即可创建出一个Series数据。传入Series中的数据时,可以传入一个字典,每个键值对的key是行索引,value是对应的数据,如上面的s1。也可以传入一个一维数组,然后用index参数设置行索引,不设置行索引时默认为数值型索引,即从0开始的整数,如上面的s2。
df1 = pd.DataFrame({
'one': s2,
'two': pd.Series(np.random.rand(4), index=[alpha for alpha in 'abcd'])
})
print(df1)
print(type(df1)) one two
a 0.988763 0.592909
b 0.093969 0.674316
c 0.593211 0.253496
d 0.374765 0.565424
e 0.850890 NaN
<class 'pandas.core.frame.DataFrame'>
df2 = pd.DataFrame(np.random.randn(3, 3), index=pd.date_range('1/1/2021', periods=3), columns=['one', 'two', 'three'])
print(df2)
print(type(df2)) one two three
2021-01-01 0.736518 -0.012771 0.459488
2021-01-02 0.665910 0.700380 -1.124228
2021-01-03 -0.418457 -1.907136 -0.207422
<class 'pandas.core.frame.DataFrame'>
三、Series的基本属性
df = pd.read_csv('600519.csv', encoding='gbk')
s = df['涨跌幅']
print(s.index)RangeIndex(start=0, stop=4726, step=1)
df = pd.read_csv('600519.csv', encoding='gbk')
s = df['涨跌幅']
print(s.values)
print(type(s.values))
print(s.array)['-0.4452' '-4.9981' '5.8854' ... '-1.3022' '3.685' '13.2526']
<class 'numpy.ndarray'>
<PandasArray>
['-0.4452', '-4.9981', '5.8854', '3.6993', '2.4125', '-0.3382', '5.9792',
'2.0937', '1.6915', '-0.3242',
...
'-2.7793', '-1.9765', '-0.0534', '1.2706', '-0.2965', '-0.2426', '1.9791',
'-1.3022', '3.685', '13.2526']
Length: 4726, dtype: object
df = pd.read_csv('600519.csv', encoding='gbk')
s = df['涨跌幅']
print("形状:", s.shape)
s2 = s.T
print("转置后形状:", s2.shape)形状:(4726,)
转置后形状:(4726,)
四、Series的索引设置
df = pd.read_csv('600519.csv', encoding='gbk')
s = df['涨跌幅'].head(3)
print(s)
s.index = [alpha for alpha in 'abc']
print(s)0 -0.4452
1 -4.9981
2 5.8854
Name: 涨跌幅, dtype: object
a -0.4452
b -4.9981
c 5.8854
Name: 涨跌幅, dtype: object
s2 = s.reset_index()
print(s2)
print(type(s2))
s3 = s.reset_index(drop=True)
print(s3)
print(type(s3)) index 涨跌幅
0 a -0.4452
1 b -4.9981
2 c 5.8854
<class 'pandas.core.frame.DataFrame'>
0 -0.4452
1 -4.9981
2 5.8854
Name: 涨跌幅, dtype: object
<class 'pandas.core.series.Series'>
评论