
详解DPU三大应用场景及架构(下)


上一期分享了“详解DPU三大应用场景及架构(上)”,今天接着DPU话题,继续聊聊DPU另外的两大应用场景。
DPU数据平面需要一种大规模敏捷异构的计算架构。这一部分的实现也处在“百家争鸣”的阶段,各家的实现方式差别较大,有基于通用处理器核的方式,有基于可编程门阵列FPGA的方式,也有基于异构众核的方式,还有待探索。
下载地址:
NVMe over Fabric(又名NVMe-oF)是一个相对较新的协议规范,旨在使用NVMe通过网络结构将主机连接到存储,支持对数据中心的计算和存储进行分解。NVMe-oF协议定义了使用各种通用的传输协议来实现NVMe功能的方式。在NVMe-oF诞生之前,数据存储协议可以分为三种:
(1)iSCSI:是一种基于IP的存储网络标准,在TCP/IP网络上通过发送 SCSI命令来访问块存储服务。
(2)光纤通道(Fibre Channel):是一种高速的数据传输协议,提供有序无损的块数据传输。主要用于关键高可靠要求的业务上。
(3)SAS(Serial Attached SCSI):一种点对点串行协议,通过SAS线缆传 输数据。
上述数据存储协议,在当今数据爆发的时代,已经无法满足大数据量的传 输。NVMe-oF的出现,不仅解决了上述协议的性能瓶颈问题,它还允许组织为 高度分布式、高度可用的应用程序实施横向扩展的存储。通过将NVMe协议扩展到SAN设备,NVMe-oF提高了CPU的使用效率,同时提高了服务器和存储应用程序之间的连接速度。
NVMe-oF主要支持三大类Fabric传输选项,分别是FC、RDMA和TCP,其中RDMA支持InfiniBand、RoCEv2和iWARP。
NVMe-oF/FC和第六代FC可以共存于同一基础设施中,避免了数据中心的叉车升级。但是,NVMe-oF/FC不具有软件定义存储的能力。NVMe-oF/RDMA利用了RDMA网络的优势,是理想的Fabric,提供了低延 迟、低抖动和低CPU使用率低传输层协议,可以最大限度利用硬件加速,避免软件协议栈开销。同时,由于RDMA是一种内存读写技术,可以应用在众多场景中,如GPUDirect Storage的应用场景。
NVMe-oF/TCP利用了TCP协议的可靠性传输的特点,以及TCP/IP网络的通用性和良好的互操作性,可以完美的应用于现代数据中心网络。在相对性能要求不是非常高的场景,NVMe-oF/TCP可作为备选。
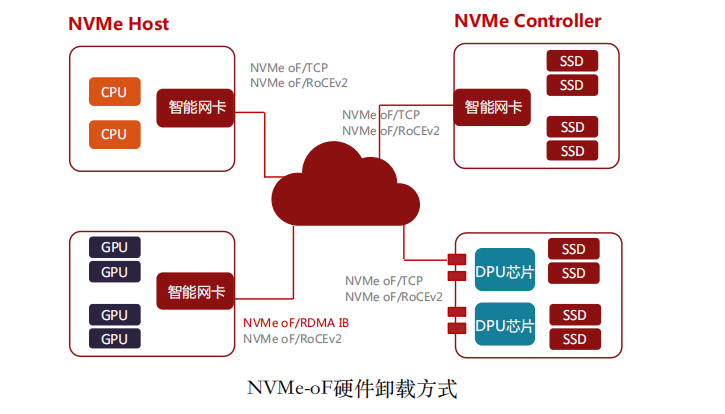
NVMe支持Host端(Initiator或Client)和Controller端(Target或Server),目 前DPU智能网卡硬件加速的场景中,包括如下四中情况:
(1)普通智能网卡硬件加速NVMe-oF Initiator。智能网卡支持NVMe-oF/TCP和NVMe-oF/RoCEv2作为Initiator,通过硬件卸载NVMe-oF/TCP或NVMe- oF/RoCEv2,用于计算和存储之间,来达到较高性能。
(2)支持GPUDirect Storage的智能网卡加速NVMe-oF Initiator和Target。GPUDirect Storage是NVIDIA提出的GPU可以绕过CPU直接访问存储磁盘的技术,RDMA技术是GPUDirect Storage的基础。这类网卡可以通过硬件卸载NVMe- oF/RDMA来实现GPU与远端存储服务的直接访问。常见的如NVMe-oF/RDMA IB和NVMe-oF/RoCEv2。
(3)智能网卡硬件加速NVMe-oF Target。该场景主要是通过智能网卡提供PCIe Root Complex能力和NVMe-oF Controller端的硬件卸载加速,来实现NVMe存储服务器。如Broadcom Stingray PS1100R是这个场景的代表之一。
(4)DPU芯片硬件加速NVMe-oF Target。该场景是通过DPU芯片提供多个PCIe Root Complex通道以及多个100Gbps的网卡实现的超大吞吐的存储服务器。Fungible FS1600 12x100Gbps带宽吞吐的存储服务器是这个场景的典型代表。
OpenStack从Rocky版本已经支持了NVMe-oF,通过OpenStack Cinder通过消息在NVMe-oF Target上来创建,查询和删除卷等,OpenStack Nova在主机上通过NVMe-oF Initiator发现NVMe-oF存储设备,并将存储设备信息传递给Hypervisor来实现虚拟机挂载磁盘。另外,OpenStack集成Ceph做块存储和对象存储已经非常成熟,Ceph的后端存储也渐渐的从使用本地磁盘的方式转向远端NVMe存储,这样NVMe-oF为Ceph存储服务提供了容量可伸缩的能力。
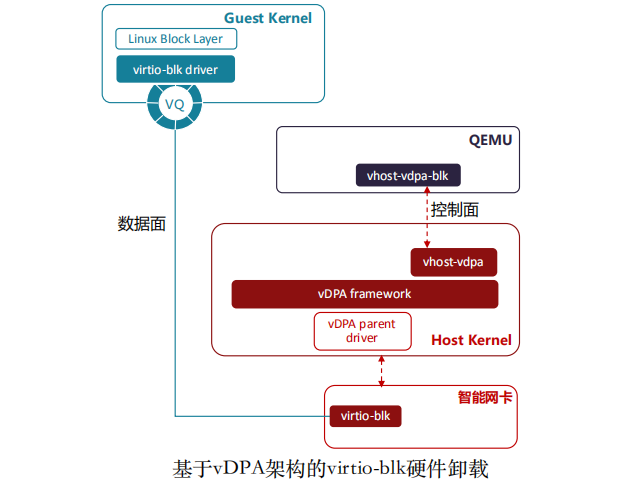
由于virtio机制通过硬件实现加速已经是通用做法,所以利用这个优势,virtio-blk卸载到硬件,已经是必然趋势。在智能网卡中,将virtio-blk到后端映射到如NVMe-oF的远端磁盘上,这样相比较当前virtio-blk的用法,不需要在主机系统中挂载很多的远端NVMe磁盘,由智能网卡直接完成映射,更加安全。
硬件信任根在安全领域是其它安全功能的基础,主要表现如下方面:
(1)硬件信任根(Root-Of-Trust):硬件信任根提供更离散的密钥生成算法,并且与主机操作系统相隔离,可以做到硬件防破解。硬件信任根实现私有 密钥存储,可以反克隆和签名。通过硬件信任根认证授权实现访问受控。
(2)加密解密(Encryption/Decryption):数据加密解密算法完全卸载到硬件网卡,无需主机CPU资源,效率更高更可靠。可以实现通用加密算法和国 密算法等。
(3)密钥证书管理(KMS):密钥证书管理卸载到智能网卡,与主机系统相隔离;支持多种密钥交换算法,如D-H密钥交换等。
(4)动态数据安全(Secure Data-in-Motion):利用硬件级加解密算法,对 传输通道上的数据做加解密处理,如IPSec和TLS等。硬件处理可以实现更高吞 吐量。
(5)静态数据安全(Secure Data-at-Rest):在存储服务中,永久存盘的数据需要进行加密,防止被窃取,硬件级数据加解密在存储服务中可以提供更高效的数据读取,并保证数据安全。
(6)流日志和流分析(Flowlog):流分析和流日志监控,对数据中心流量做精细监控,有效识别,可以及时识别DDoS攻击,并做出响应。
在安全领域,还有很多的安全功能产品,如NGFW,WAF,IPS/IDS,DDoS防御设备等。随着云和虚拟化技术的发展,越来越多的安全功能产品的实 现方式转为虚拟化方式,并通过云平台来部署管理。这些安全功能产品由于部署在数据中心流量的主要路径上,转发性能对整体网络的吞吐量和时延具有重要的影响。基于X86的软件实现方式,需要大量CPU资源来处理对应的业务逻 辑,性能上的瓶颈已经愈发明显。通过智能网卡对这些安全功能产品做硬件加速,已经是必然趋势。
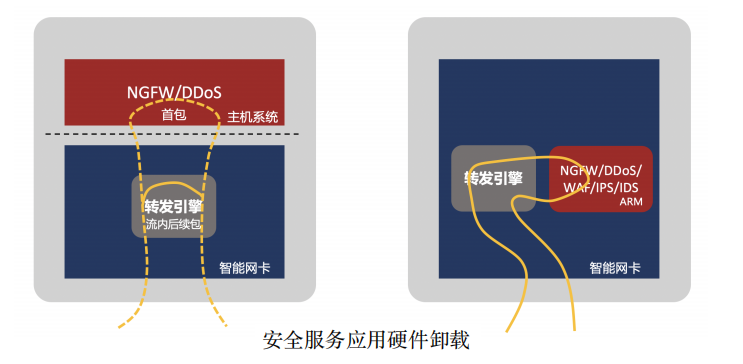
由于安全功能产品对报文处理的深度不同,有些只需要在二至四层处理,有些则需要在七层进行处理,所以在智能网卡的卸载方式上,也存在不同。如NGFW和DDoS等设备,可以通过流表卸载的方式,对流量进行拦截,来加速运行在主机系统中的安全服务应用。如IPS/IDS等,需要对报文内容做深度检测, 则可以通过in-line的方式将数据深度检测功能卸载到智能网卡的CPU上,这时需要智能网卡的CPU具有较强的性能。
在传统的网卡上做云平台虚拟化,Hypervisor以及对应的虚拟化网络的实现,都是在主机操作系统上实现的。这样如果黑客如果攻陷了Hypervisor并拿到 主机操作系统的root权限,就可以通过篡改虚拟化网络配置,来对租户网络进行攻击,甚至可以渗透到其它计算节点,进行更大范围的攻击。
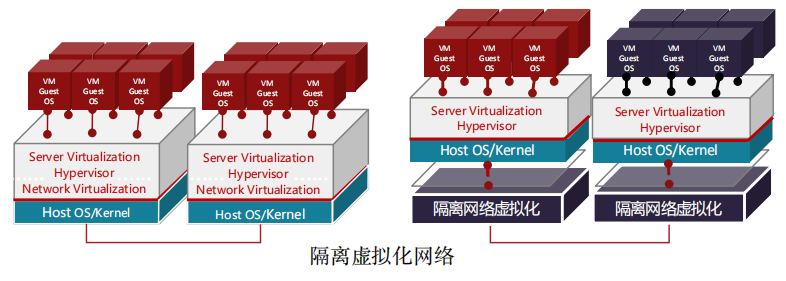
引入DPU智能网卡之后,将虚拟化网络的控制平面完全卸载到智能网卡 上,与主机操作系统相隔离。即使黑客攻陷了Hypervisor,获取了主机操作系统的root权限,也无法篡改虚拟化网络的配置,这样可以将黑客的攻击范围限制在 主机操作系统上,不会影响到虚拟化网络以及其它主机。进而达到了安全隔离的效果。
下载地址:
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
电子书<服务器基础知识全解(终极版)>更新完毕,知识点深度讲解,提供182页完整版下载。
获取方式:点击“阅读原文”即可查看PPT可编辑版本和PDF阅读版本详情。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。
