
GitHub Star 13.9k,顶级项目全新开源表格识别算法
1
导 读
相信大家在工作生活中经常会遇到表格识别的问题,比如导师说,把下面 PDF 文件里面的表格取出来整理成 Excel 表。

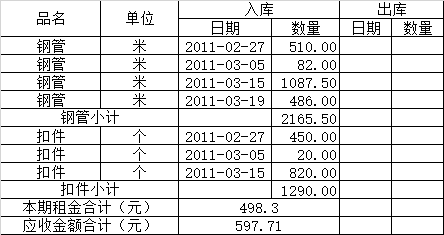
这种情况下你会怎么做呢,新建一个 Excel 一个一个数据敲么,辛辛苦苦半天赶出来,领导还会来一句,怎么这么慢,简直郁闷死……

2
效果展示
版面分析 + 表格识别
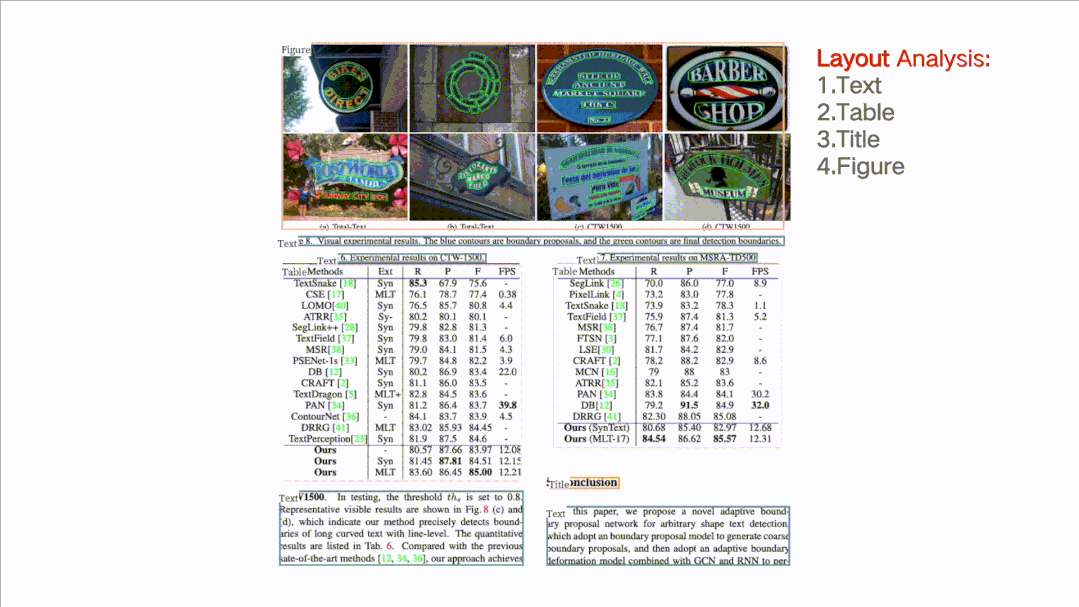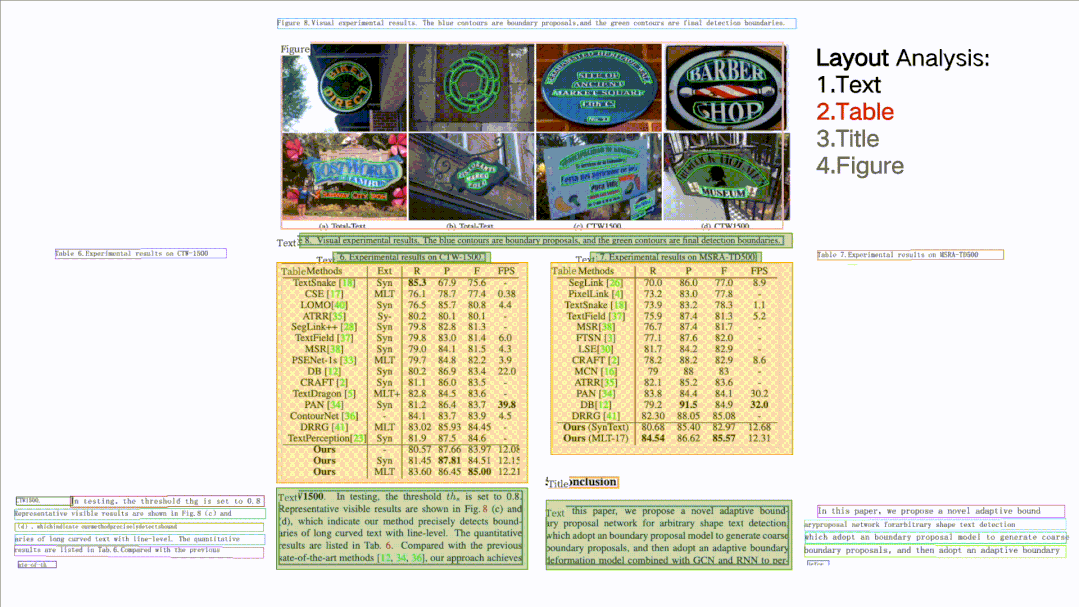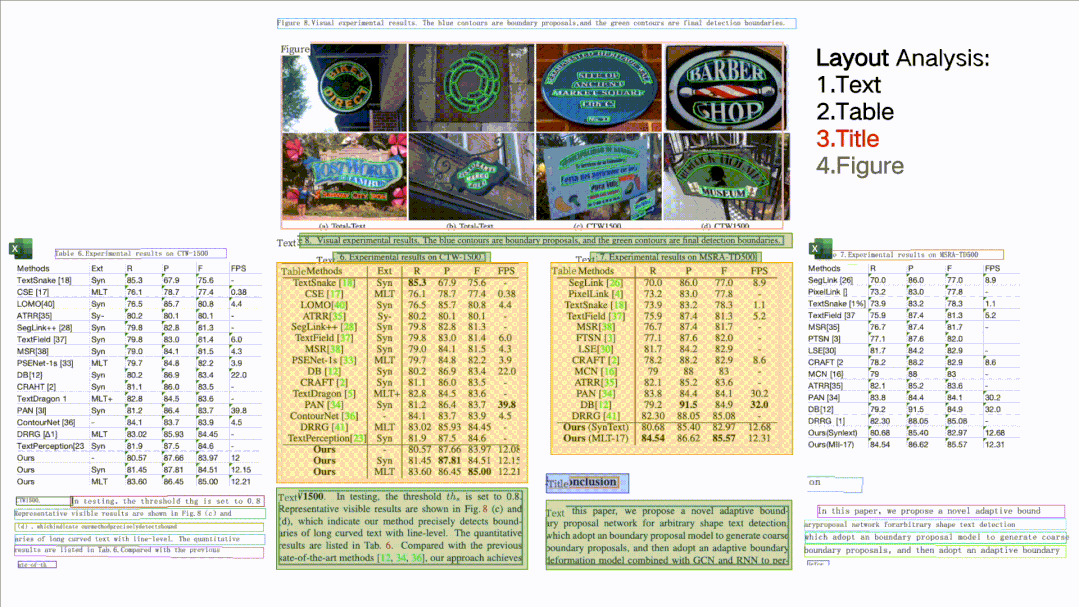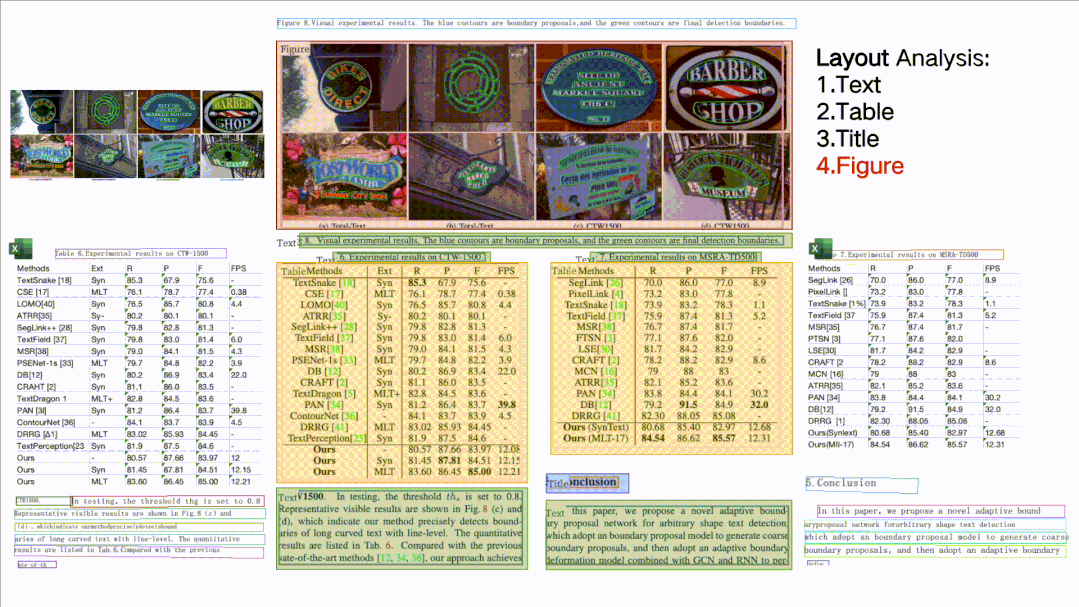
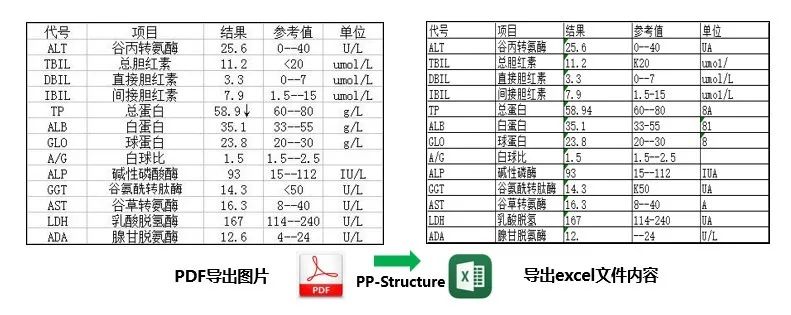
如图所示,针对一张完整的 PDF 图片,这个开源项目可以对文档图片中的文本、表格、图片、标题与列表区域进行分类。同时还可以利用表格识别技术完整地提取表格结构信息,使得表格图片变为可编辑的 Excel 文件。
不仅仅是 PDF 文件转 excel,如果编程能力再强一些,结合版面分析技术,PDF 转 Word 都不在话下。
而且使用也是非常方便,在完成 Python whl 包安装之后,简单几行代码即可完成快速试用。
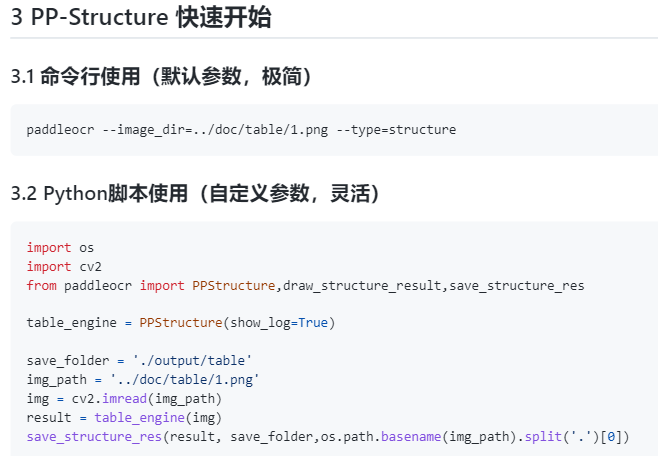
最终结果会输出图片文件夹,Excel 表和文字识别结果,确实是非常方便。
传送门:
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.2/ppstructure/README_ch.md
3
版面分析与表格识别核心技术概述
(1)传统方法:版面分析比较著名的是 O’Gorman 在 1993 年 TPAMI 中发表的算法 Docstrum。通过自下而上的方法依次将图像中的黑白连通域划分为文字、文本行与文本块,从而得到版面布局。表格识别的传统方法通过腐蚀、膨胀等操作获得表格线、划分行列区域,然后将单元格与文本内容相结合重构为表格对象。但是传统算法主要问题在于,对于版面布局分析和表格结构的提取,图像处理的方法依赖各种阈值和参数的选择,对于不同场景下的文档图片难以保证泛化性。
(2)深度学习方法:除了直接使用检测模型来对版面内容进行分类以外,还融合了检测、分割、图神经网络、注意力机制等众多前沿技术能力。依赖算法工程师对于深度神经网络的精心设计,可以不再依赖阈值与参数,具有更好的泛化性。
4
PP-Structure核心技术解读
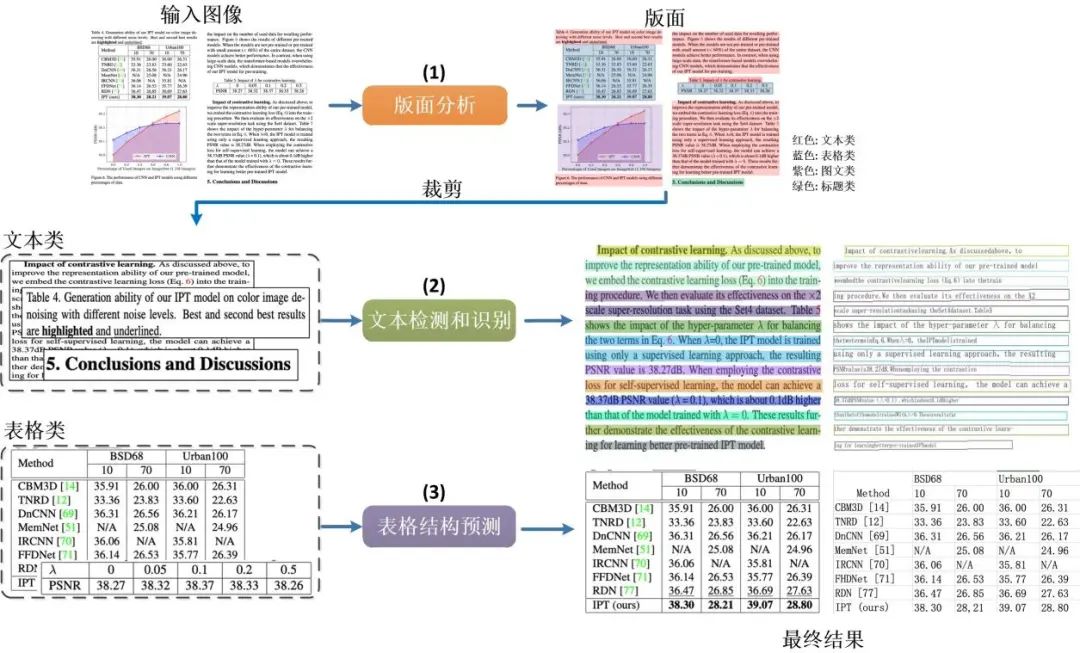
版面分析技术
Layout-Parser 是开源的基于深度学习的文档图像分析工具箱,可用于布局检测,字符识别和许多其他文档处理任务,包含大量丰富模型,支持自定义 DL 模型,支持多个文档布局检测数据集。
GitHub 地址:
https://github.com/Layout-Parser/layout-parser
表格识别技术
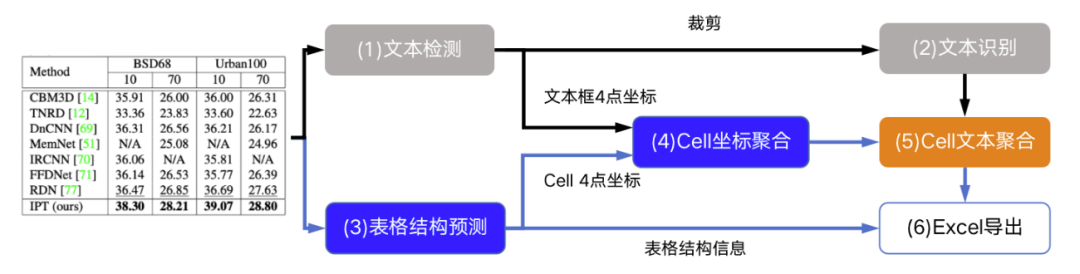

(4)Cell 坐标聚合模块,主要用来解决如何将跨行单元格的文本重新拼接在一个单元格内的问题。它通过计算由文本检测算法获得的文本框坐标(红色框)与表格结构预测模块得到的 Cell 坐标(蓝色框)之间的 IOU 和顶点距离来进行单行到多行的聚合。使用 IOU 判断哪些红色框同属于一个蓝色框,使用顶点距离和 IOU 判断红色框的排列顺序。
(5)Cell 文本聚合模块,根据已有的红色文本框顺序,按照从上到下从左到右顺序利用(4)Cell 坐标聚合模块的结果将(2)文本识别结果和进行拼接,这样对于多行文本的单元格内容即可拼接成一个字符串。
(6)Excel 导出模块,将(3)表格结构预测结果 html 结果与(5)Cell 文本聚合模块文本结果结合,最终导出为 Excel 输出。
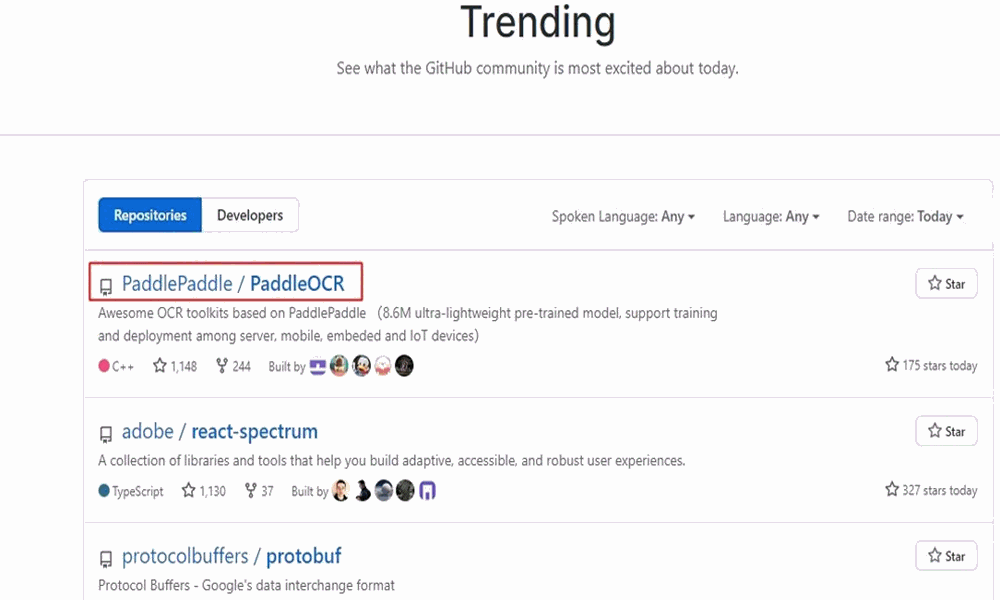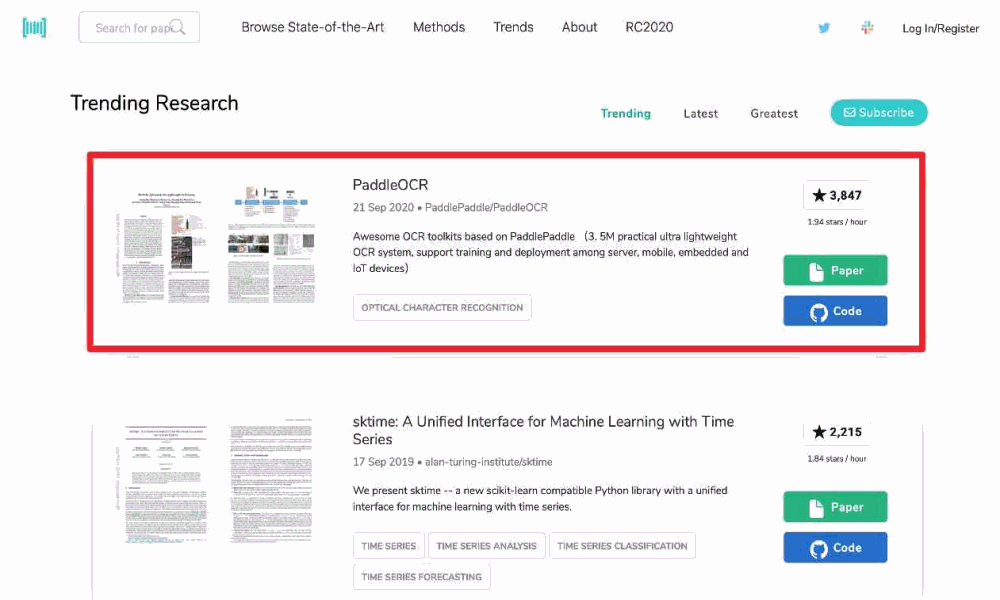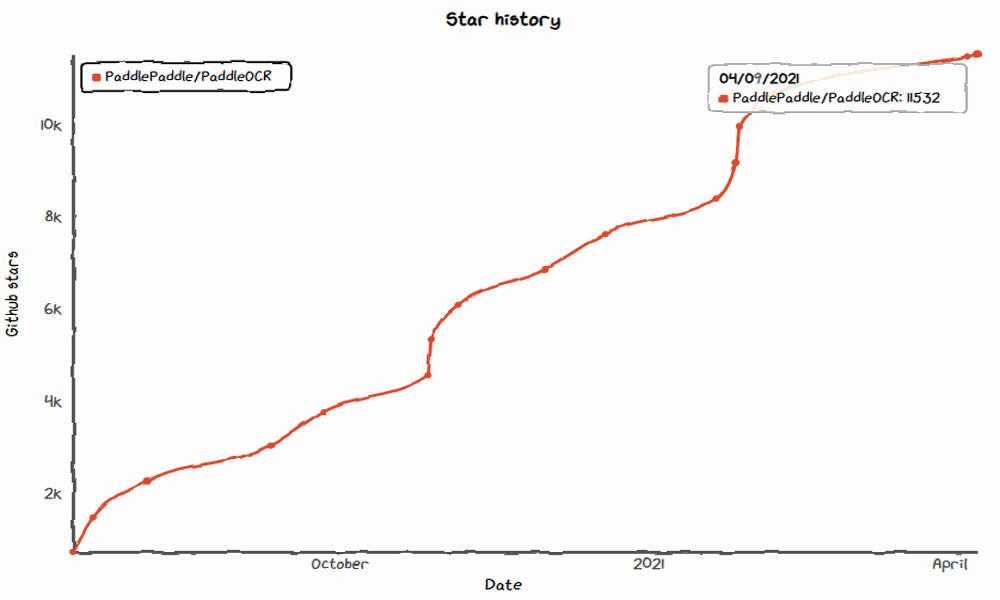
以上所有内容均在 PaddleOCR 项目开源,目前 star 数量超过 13.5k
5
相关延伸阅读:PaddleOCR历史表现回顾
2020 年 6 月,8.6M 超轻量模型发布,GitHub Trending 全球趋势榜日榜第一。
2020 年 8 月,开源 CVPR2020 顶会算法,再上 GitHub 趋势榜单!
2020 年 10 月,发布 PP-OCR 算法,开源 3.5M 超超轻量模型,再下 Paperswithcode 趋势榜第一
2021 年 1 月,发布 Style-Text 文本合成算法,PPOCRLabel 数据标注工具,star 数量突破 10000+,截至目前已经达到 11.5k,在《Github 2020 数字洞察报告》中被评为中国 GithubTop20 活跃项目。
2021 年 4 月,开源 AAAI 顶会论文 PGNet 端到端识别算法,Star 突破 13k
2021 年 8 月,开源版面分析与表格识别算法
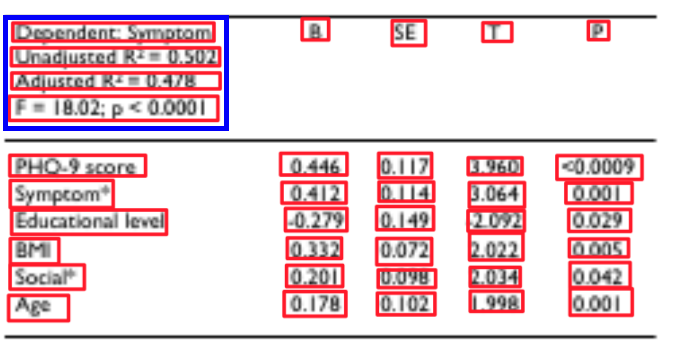
文本检测识别效果:

这个最强 OCR 项目,你值得拥有:
https://github.com/PaddlePaddle/PaddleOCR

8 月 12 日(周四)20:15-21:30 百度高级研发工程师将带我们解读文档分析技术 PP-Structure 及 PaddleOCR 应用落地经验,欢迎大家踊跃报名直播课!
扫描二维码报名,立即加入交流群

・PaddleOCR 项目地址・
Gitee:
https://gitee.com/paddlepaddle/PaddleOCR
