
【机器学习】使用MLflow管理机器学习模型版本
作者 | Àlex Escolà Nixon
编译 | VK
来源 | Towards Data Science

在机器学习项目中工作通常需要大量的实验,例如尝试不同的模型、特征、不同的编码方法等。
我们都遇到过一个非常常见的问题,就是改变模型中的一些设置或参数,并意识到我们之前的运行可能会产生更好的结果。我们可以回到过去并不容易。或者由于其他原因,我们的可追溯性可能会发生变化,或者因为其他原因,我们的模型会发生变化。
这就是MLflow发挥作用的地方,在我们的机器学习生命周期中带来可追溯性和可再现性。
在这篇文章中,我将向你展示如何在本地设置MLflow以及使用PostgreSQL注册模型和管理端到端机器学习生命周期的数据库备份存储。
另外,在这里有一个笔记本,上面有所有的代码和解释:https://github.com/AlexanderNixon/Machine-learning-reads/blob/master/Model_versioning_with_MLflow.ipynb
介绍
MLflow提供了四个主要组件:跟踪、项目、模型和注册表。在这篇文章中,我们将关注所有组件。项目,这是一个用于打包数据科学代码的更通用的工具思想。而下面简要概述了其他组件的目标:
MLflow跟踪:记录和查询实验:代码、数据、配置和结果
MLflow模型:在不同的服务环境中记录和部署机器学习模型
模型注册表:在中央存储库中存储、注释、发现和管理模型
换句话说,「MLflow跟踪」将允许我们记录模型运行的所有参数、指标等。
我们将使用「MLflow模型」来记录给定的模型(尽管这个组件也用于部署ML模型)。而「模型注册表」可以对现有模型进行“版本化”,将它们从发布过渡到生产,并更好地管理ML项目的生命周期。
模型注册表,需要为要存储的所有数据设置一个数据库。在后端存储区中说明:
❝为了使用模型注册表功能,必须使用支持的数据库来运行服务器
❞
我们可以在本地文件中记录所有的度量和模型,但是如果我们想利用MLflow的模型注册表组件,我们需要建立一个数据库。
在本文中,我们将学习如何:
设置本地postgreSQL数据库作为MLflow的后端存储
创建MLflow实验并跟踪参数、度量和其他
注册模型,允许阶段转换和模型版本控制
安装程序
我将使用WSL来处理一个Ubuntu终端环境,这将使后端存储的设置更加容易,conda将创建一个具有我们所需依赖关系的环境。
让我们先用python 3.8创建一个环境,以及我们将要使用的一些基本依赖项:
conda create --name mlflow python==3.8 matplotlib scikit-learn
然后通过conda安装postgresql:
conda install -y -c conda-forge postgresql
设置postgreSQL
然后,我们需要做的第一件事是通过initdb创建一个新的PostgreSQL数据库集群,并使用以下命令启动de database server:
initdb
pg_ctl -D /home//pgdata -l logfile start
现在我们将使用psql来启动PostgreSQL交互终端。我们可以通过访问postgres数据库来完成此操作,该数据库已在安装中提供:
psql --dbname postgres
我们需要指定一些现有的数据库(例如postgres),因为默认情况下psql将尝试连接到与你的用户同名的数据库,由于它不存在,它将返回一个错误。
进入交互终端后,为mlflow创建一个新的数据库,以存储所有注册的模型:
postgres=# CREATE DATABASE mlflow_db;
并添加新的用户和密码以在访问数据库时进行身份验证:
CREATE USER mlflow WITH ENCRYPTED PASSWORD 'mlflow';
GRANT ALL PRIVILEGES ON DATABASE mlflow_db TO mlflow;
我们可以看到,用户已正确创建为:
postgres=# \du

我们还可以检查数据库是否已正确创建,并且用户mlflow可以访问:
\list
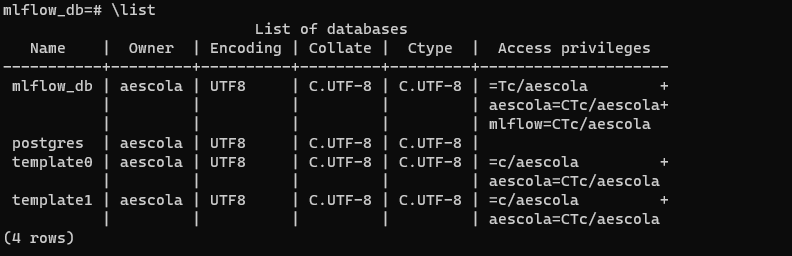
如果一切正常,现在可以退出控制台:
postgres=# \q
「postgreSQL中到底有哪些内容?」
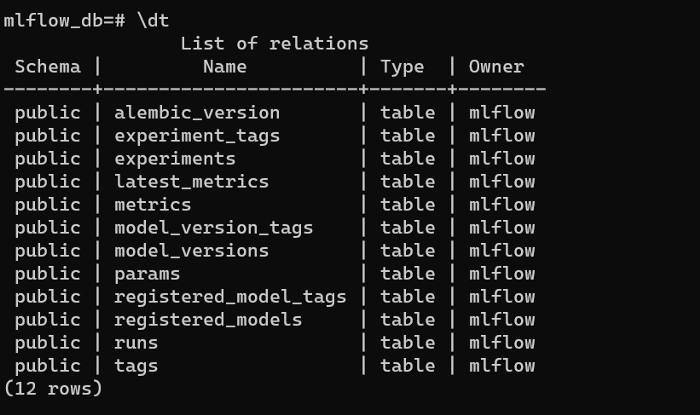
我们建立的本地数据库将包含与我们注册的模型相关的数据。我们可以通过使用psql--dbname mlflow_db连接到数据库来查看其内容。然后,我们可以使用\dt查看MLflow正在创建的表:
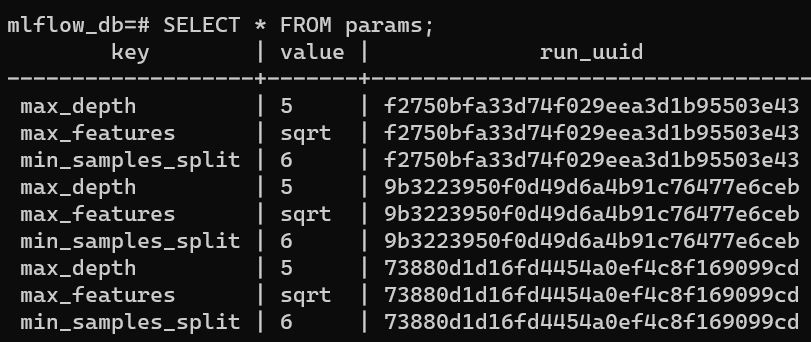
例如,params表包含注册模型版本的所有生成参数:
MLflow
现在是时候开始MLflow了。让我们从pip安装mlflow和psycolpg2开始,这是一个针对Python的PostgreSQL适配器,我们将需要:
pip install mlflow
pip install psycopg2-binary
并为MLflow创建一个目录,以存储每次运行中生成的所有文件:
mkdir ~/mlruns
现在一切都准备好运行MLflow跟踪服务器了!为此,运行mlflow server,将postgreSQL指定为--backend-store-uri,其格式通常为--default-artifact-root,其中包含我们创建mlruns文件夹的路径:
mlflow server --backend-store-uri postgresql://mlflow:mlflow@localhost/mlflow_db --default-artifact-root file:/home//mlruns -h 0.0.0.0 -p 8000
你应该会看到这样的东西:

现在可以访问指定地址中的MLflow UIhttp://localhost:8000,并应看到:

请注意,有两个主要部分:
实验:你将保存你的不同的“项目”
模型:包含所有已注册的模型(下一节将对此进行详细说明)
请注意,每个实验都与一个实验ID相关联,这一点很重要,因为MLflow将在mlruns下创建一个新的文件夹,其中包含每次运行中生成的模型和工件。
在讨论MLflow的跟踪和模型组件的一些示例之前,让我们先用我们创建的环境设置一个笔记本。
Jupyter笔记本设置
如果还没有安装jupyter,我们首先需要在环境中安装jupyter:
conda install jupyter
设置——没有浏览器会阻止浏览器在笔记本被服务后自动打开,如果通过WSL执行,则会引发错误。
jupyter notebook --port=8889 --no-browser
现在复制指定的url,其格式为http://localhost:8889/?token=。进入浏览器并创建一个笔记本。你会注意到你创建的conda环境不能作为内核使用。为此,你必须先安装它。运行:
sudo /home//anaconda3/envs/mlflow_training/bin/python -m ipykernel install --name mlflow
如果你现在刷新笔记本,你应该可以看到环境。
登录MLflow
要开始登录MLflow,你需要将MLflow_TRACKING_URI环境变量设置为MLflow正在服务的跟踪操作系统环境os.environ['MLFLOW_TRACKING_URI'] = 'http://localhost:8000/'。
让我们创建一个虚拟示例,将DecisionTreeClassifier拟合到iris数据集:
from matplotlib import pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree, export_graphviz
from sklearn.metrics import accuracy_score
import os
os.environ['MLFLOW_TRACKING_URI'] = 'http://localhost:8000/'
# 加载iris数据集
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=.3)
# 分类器的拟合与测试
dt_params = {'max_depth': 5, 'max_features': 'sqrt', 'min_samples_split':6}
dt = DecisionTreeClassifier(**dt_params)
dt.fit(X_train, y_train)
y_pred = dt.predict(X_test)
acc = accuracy_score(y_test, y_pred).round(3)
# 保存
plt.figure(figsize=(10,10))
t = plot_tree(dt,
feature_names=['sepal length', 'sepal width', 'petal length', 'petal width'],
class_names=load_iris()['target_names'],
filled=True,
label='all',
rounded=True)
tree_plot_path = "dtree.jpg"
plt.savefig(tree_plot_path)
现在让我们创建一个MLflow实验,并记录模型、其参数和我们获得的度量:
import mlflow
mlflow.set_experiment('DecisionTreeClassifier')
with mlflow.start_run(run_name='basic parameters'):
mlflow.sklearn.log_model(sk_model=dt,
artifact_path='',
registered_model_name='tree_model')
mlflow.log_params(dt_params)
mlflow.log_metric('Accuracy', acc)
mlflow.log_artifact(tree_plot_path, artifact_path='plots')
使用with语句,我们记录的所有内容都将与同一次运行相关,并且一旦退出子句,就结束MLflow。
MLflow有一组内置的模型风格,这正是我们在这里通过mlflow.sklearn.log_model注销scikit-learn模型所使用的风格。在部署这些模型时,这很方便,因为MLflow为每种风格添加了许多专门考虑的工具。
注意,除了将上述所有内容记录到运行中,我们还将这个模型注册为一个新版本(如果它不存在,它将创建这个模型和一个0版本),因为我们在mlflow.sklearn.log_model中使用了参数registered_model_name。
首先让我们看看记录的运行在UI中是什么样子:
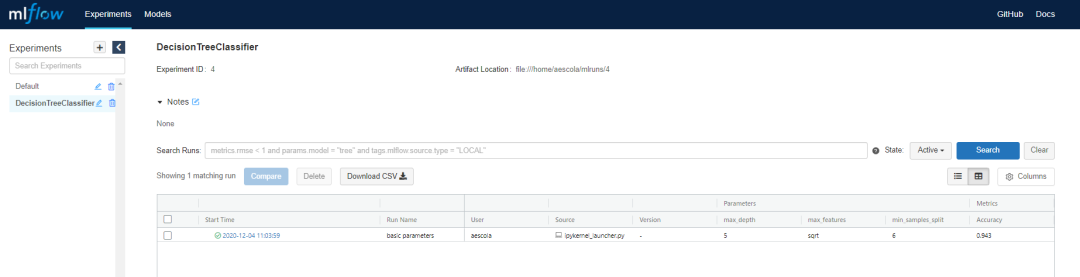
现在,你将在创建的决策树分类器实验中看到一个新的运行,其中包含所有记录的信息。我们可以通过单击“开始时间”下的实际运行来查看更多详细信息。在这里,我们将看到有关参数和指标的更多信息:

以及其他一些字段,如日志记录、自动生成的conda环境(如果我们想部署模型,则非常有用)和序列化模型:
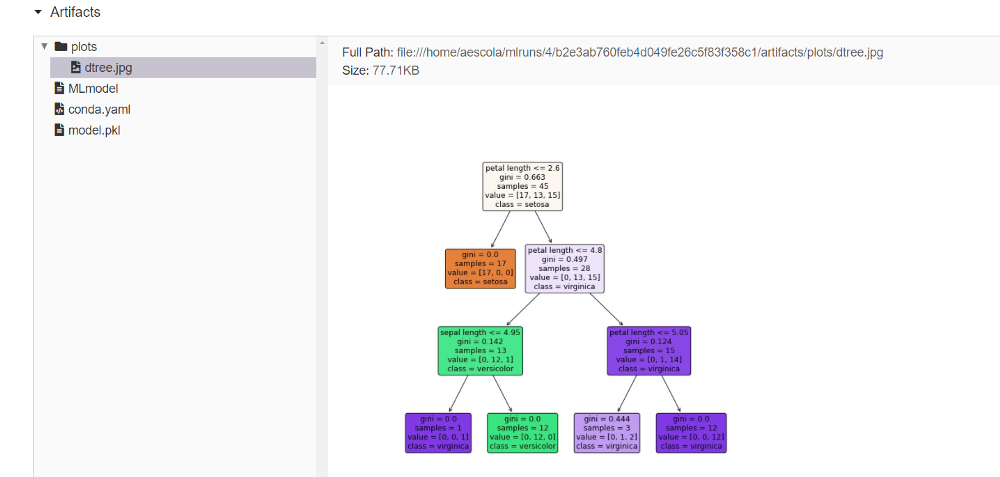
MLflow模型
在“模型”部分,你将找到已注册的所有模型。通过选择其中一个,本例中的tree_model,你将看到该模型的所有现有版本。请注意,每次以相同的名称注册新模型时,都会创建一个新版本。
一旦运行了一些已注册的模型,你将得到如下内容:
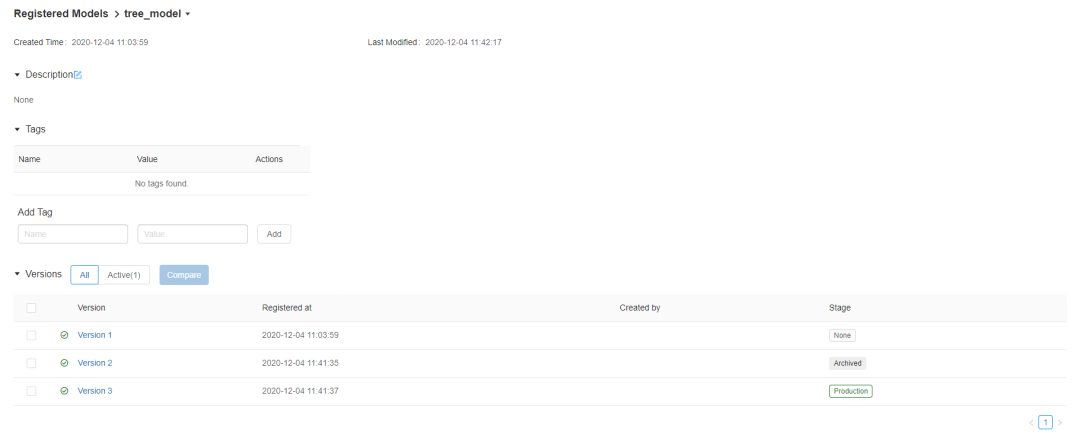
通过选择特定模型并单击“阶段”部分,可以将模型从一个阶段过渡到另一个阶段:

在一篇文章中,这些知识可能已经足够了:)
在下一篇文章中,我将向你展示使用MLflow的一些更高级的示例,展示它的一些其他特性,例如自动日志记录,或者如何为注册的模型提供服务。
非常感谢你抽出时间阅读这篇文章。
往期精彩回顾
本站知识星球“黄博的机器学习圈子”(92416895)
本站qq群704220115。
加入微信群请扫码: