
网易游戏 Flink SQL 平台化实践
01
网易游戏 Flink SQL 发展历程

网易游戏实时计算平台叫做 Streamfly,这个名字取名自电影《驯龙高手》中的 Stormfly。由于我们已经在从 Storm 迁移到 Flink,所以将 Stormfly 中的 Storm 替换成了更为通用的 Stream。
Streamfly 前身是离线作业平台 Omega 下的名为 Lambda 的子系统,它负责了所有实时作业的调度,最开始开始支持 Storm 和 Spark Streaming,后来改为只支持 Flink。在 2019 年的时候我们将 Lambda 独立出来以此为基础建立了 Streamfly 计算平台。随后,我们在 2019 年底开发并上线了第一个版本 Flink SQL 平台 StreamflySQL。这个版本基于模板 jar 提供了基本 Flink SQL 的功能,但是用户体验还有待提升,因此我们在 2021 年年初从零开始重新建设了第二个版本的 StreamflySQL,而第二个版本是基于 SQL Gateway。
要了解这两个版本的不同,我们需要先回顾下 Flink SQL 的基本工作流程。
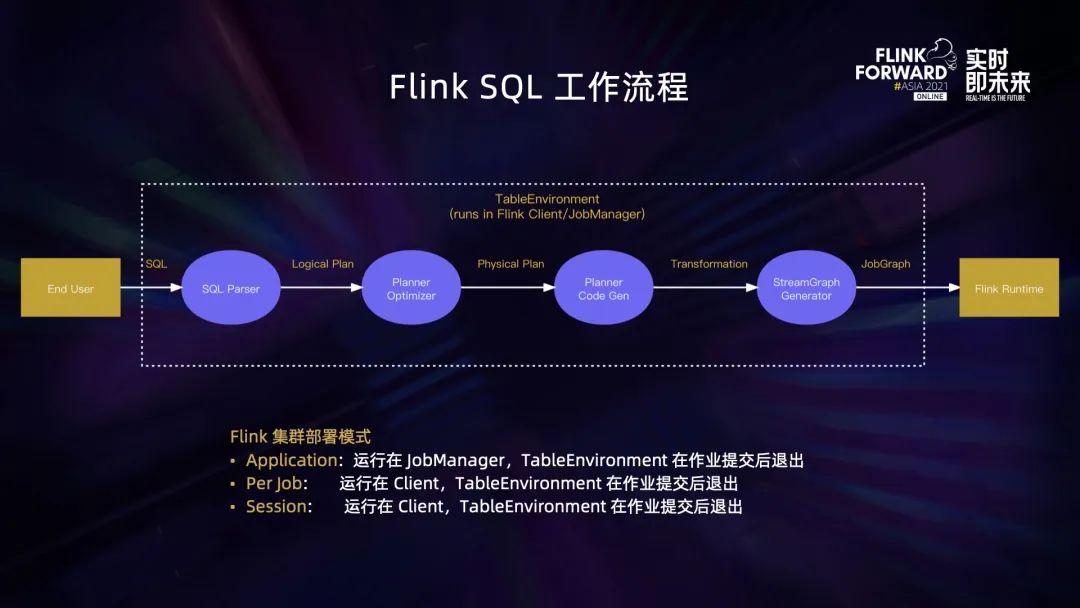
用户提交的 SQL 首先会被 Parser 解析为逻辑执行计划;逻辑执行计划经过 Planner Optimizer 优化,会生成物理执行计划;物理执行计划再通过 Planner CodeGen 代码生成,翻译为 DataStream API 常见的 Transformation;最后 StreamGraphGenerator 会将这些 Transformation 转换为 Flink 作业的最终表示 JobGraph 提交到 Flink 集群。
上述一系列过程都发生在 TableEnvironment 里面。取决于部署模式的不同,TableEnvironment 可能运行在 Flink Client 或者 JobManager 里。Flink 现在支持 3 种集群部署模式,包括 Application、 Per-Job 和 Session 模式。在 Application 模式下,TableEnvironment 会在 JobManager 端运行,而在其余两种模式下,TableEnvironment 都运行在 Client 端。不过这三种模式都有一个共同的特点,TableEnvironment 都是一次性的,会在提交 JobGraph 之后自动退出。

为了更好地复用 TableEnvironment 提高效率和提供有状态的操作,有的项目会将 TableEnvironment 放到一个新的独立 Server 端进程里面去运行,由此产生了一种新的架构,我们称之为 Server 端 SQL 编译。相对地,还有 Client 端 SQL 编译。
有同学可能会问,为什么没有 JobManager 端 SQL 编译,这是因为 JobManager 是相对封闭的组件,不适合拓展,而且即使做了达到的效果跟 Client 端编译效果基本一样。所以总体来看,一般就有 Client 和 Server 两种常见的 Flink SQL 平台架构。
Client 端 SQL 编译,顾名思义就是 SQL 的解析翻译优化都在 Client 端里进行(这里的 Client 是广义的 Client,并不一定是 Flink Client)。典型的案例就是通用模板 jar 和 Flink 的 SQL Client。这种架构的优点是开箱即用,开发成本低,而且使用的是 Flink public 的 API,版本升级比较容易;缺点是难以支持高级的功能,而且每次都要先启动一个比较重的 TableEnvironment 所以性能比较差。
然后是 Server 端 SQL 编辑。这种架构将 SQL 解析翻译优化逻辑放到一个独立的 Server 进程去进行,让 Client 变得非常轻,比较接近于传统数据库的架构。典型的案例是 Ververica 的 SQL Gateway。这种架构的优点是可拓展性好,可以支持很多定制化功能,而且性能好;缺点则是现在开源界没有成熟的解决方案,像上面提到 SQL Gateway 只是一个比较初期的原型系统,缺乏很多企业级特性,如果用到生产环境需要经过一定的改造,而且这些改造涉及比较多 Flink 内部 API,需要比较多 Flink 的背景知识,总体来说开发成本比较高,而且后续版本升级工作量也比较大。
编者按:Apache Flink 社区目前正在开发 SQL Gateway 组件,将原生提供 Flink SQL 服务化的能力,并兼容 HiveServer2 协议,计划于 1.16 版本中发布,敬请期待。感兴趣的同学可以关注 FLIP-91[1] 和 FLIP-223[2] 了解更多,也非常欢迎大家参与贡献。
[1] https://cwiki.apache.org/confluence/display/FLINK/FLIP-91%3A+Support+SQL+Gateway
[2] https://cwiki.apache.org/confluence/display/FLINK/FLIP-223%3A+Support+HiveServer2+Endpoint
回到我们 Flink SQL 平台,我们 StreamflySQL v1 是基于 Client 端 SQL 编译,而 v2 是基于 Server 端的 SQL 编译。下面就让我逐个介绍一下。
02
基于模板 jar 的 StreamflySQL v1
StreamflySQL v1 选择 Client 端 SQL 编译的主要原因有三个:

首先是平台集成。不同于很多公司的作业调度器用大数据中比较主流的 Java 编写,我们的 Lambda 调度器是用 Go 开发的。这是因为 Lambda 在设计之初支持了多种实时计算框架,出于松耦合和公司技术栈的考虑,Lambda 以 Go 作为开发语言,会采用与 YARN 类似的动态生成 Shell 脚本的方式来调用不同框架的命令行接口。这样松耦合的接口方式给我们带来很大的灵活性,比如我们可以轻松支持多个版本的 Flink,不需要强制用户随着系统版本升级,但同时也导致没办法直接去调用 Flink 原生的 Java API。
- 第二个原因是松耦合。开发的时候 Flink 版本是1.9,当时 Client API 比较复杂,不太适合平台集成,并且当时社区也在推动 Client 的重构,所以我们尽量避免依赖 Client API去开发 Flink SQL 平台。
- 第三个原因是实践经验。因为模板 jar + 配置中心模式在网易游戏内部已经有了比较多的应用,所以我们在这方面积累了很多实践经验。综合之下我们很自然地采用了模板 jar + 配置中心的架构来实现 v1 版本。
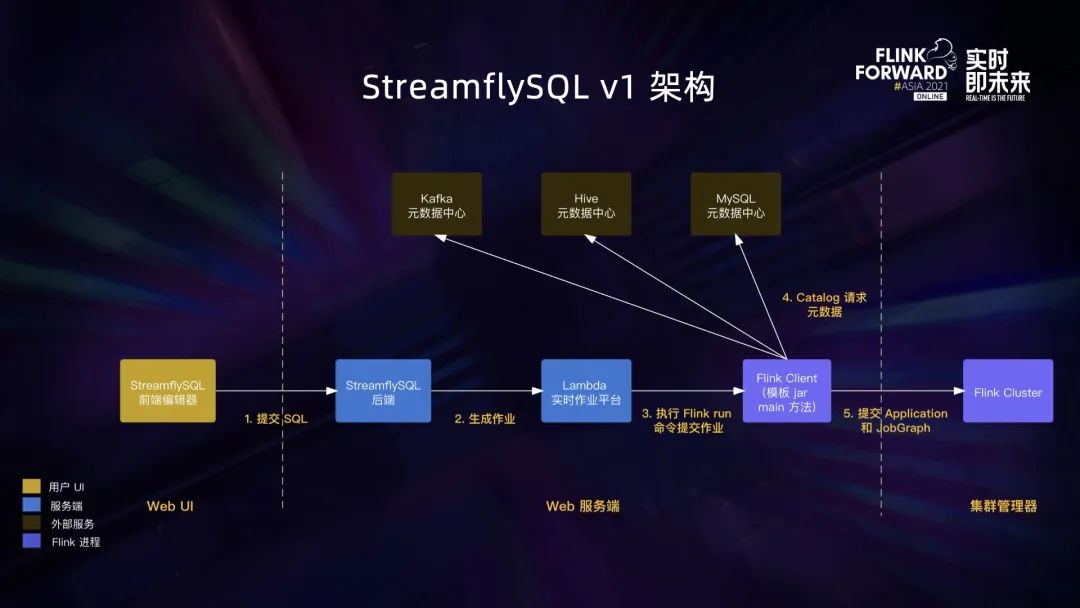
上图是 v1 版本的整体架构图。我们在主要在 Lambda 作业平台的基础上新增了 StreamflySQL 后端作为配置中心,负责根据用户提交的 SQL 和作业运行配置加上通用的模板 jar 来生成一个 Lambda 作业。
总体的作业提交流程如下:
- 用户在前端的 SQL 编辑器提交 SQL 和运行配置。
- StreamflySQL 后端收到请求后生成一个 Lambda 作业并传递配置 ID。
- 然后 Lambda 启动作业,背后是执行 Flink CLI run 命令来提交作业。、
- Flink CLI run 命令会启动 Flink Client 来加载并执行模版 jar 的 main 函数,这时会读取 SQL 和配置,并初始化 TableEnvironment。
- TableEnvironment 会从 Catalog 读取必要的 Database/Table 等元信息。这里顺带一提是,在网易游戏我们没有使用统一的 Catalog 来维护不同组件的元信息,而是不同组件有自己的元数据中心,对应不同的 Catalog。
- 最后 TableEnvironment 编译好 JobGraph,以 Per-Job Cluster 的方式部署作业。
StreamflySQL v1 实现了 Flink SQL 平台从零到一的建设,满足了部分业务需求,但仍有不少痛点。
第一个痛点是响应慢。

以一个比较典型的 SQL 来说,以模板 jar 的方式启动作业需要准备 TableEnviroment,这可能会花费 5 秒钟,然后执行 SQL 的编译优化包括与 Catalog 交互去获取元数据,也可能会花费 5 秒钟;编译得到jobgraph之后还需要准备 per-job cluster,一般来说也会花费 20 秒以上;最后还需要等待 Flink job的调度,也就是作业从 scheduled 变成 running 的状态,这个可能也需要 10 秒钟。
总体来说,v1 版本启动一个 Flink SQL 作业至少需要 40 秒的时间,这样的耗时相对来说是比较长的。但是仔细分析这些步骤,只有 SQL的编译优化和 job 调度是不可避免的,其他的比如 TableEnvironment 和 Flink cluster 其实都可以提前准备,这里的慢就慢在资源是懒初始化的,而且几乎没有复用。
第二个痛点是调试难。

我们对 SQL 调试的需求有以下几点:
- 第一点是调试的 SQL 与线上的 SQL 要基本一致。
- 第二点是调试 SQL 不能对线上的数据产生影响,它可以去读线上的数据,但不能去写。
- 第三点,因为调试的 SQL 通常只需要抽取少量的数据样本就可以验证 SQL 的正确性,所以我们希望限制调试 SQL 的资源,一方面是出于成本的考虑,另外一方面也是为了防止调试的 SQL 与线上作业产生资源竞争。
- 第四点,因为调试 SQL 处理的数据量比较少,我们希望以更快更便捷的方式获取到结果。
在 v1 版本中,我们对上述需求设计了如下解决方案:
- 首先对于调试的 SQL,系统会在 SQL 翻译的时候将原来的一个 Sink 替换为专用的 PrintSink,这解决了需求中的前两点。
- 然后对 PrintSink 进行限流,通过 Flink 的反压机制达到总体的限流,并且会限制作业的最长执行时间,超时之后系统会自动把作业结束掉,这解决了需求中的资源限制这点。
- 最后为了更快地响应,调试的作业并不会提交到 YARN 集群上去运行,而是会在 Lamdba 服务器本地开启开启一个 MiniCluster 去执行,同时也方便我们从标准输出去提取 PrintSink 的结果,这点解决了需求中的最后一点。
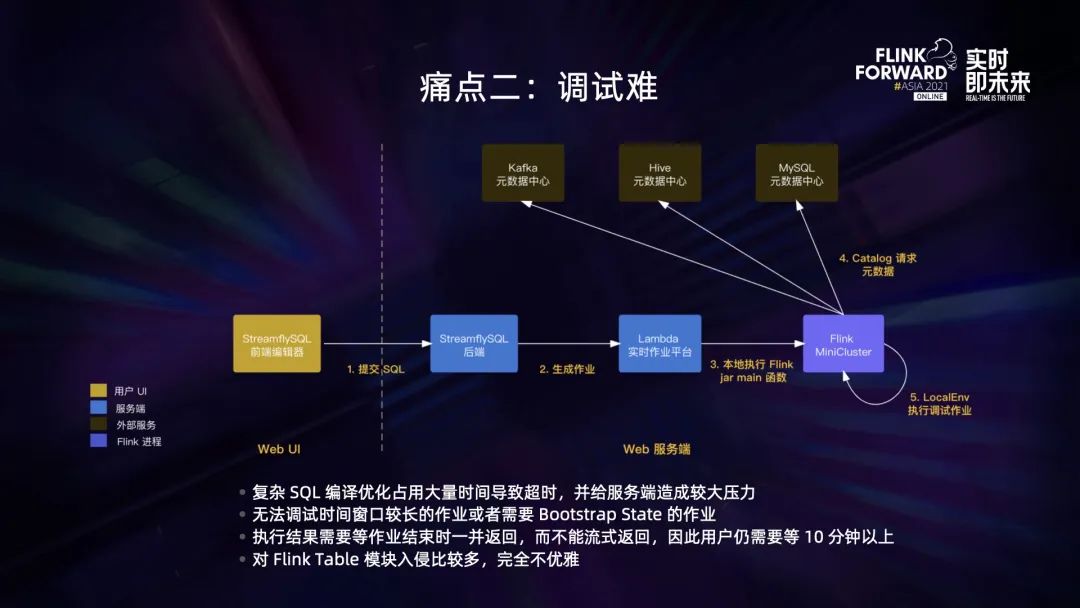
调试模式的架构如上图所示,比起一般的 SQL 提交流程,主要区别在于作业不会提交到 YARN 上,而是在 Lambda 服务器的本地执行,从而节省了准备 Flink 集群的开销,并且更容易管控资源和获取结果。
上述调试解决方案基本可用,但是实际使用过程中依然存在不少问题。
- 第一,如果用户提交的 SQL 比较复杂,那么 SQL 的编译优化可能会耗费比较久的时间,这会导致作业很容易超时,在有结果输出之前可能就被系统结束掉,同时这样的 SQL 也会给服务器造成比较大的压力。
- 第二,该架构没法去调试时间窗口比较长的作业或者需要 Bootstrap State 的作业。
- 第三,因为执行结果是在作业结束之后才批量返回的,不是在作业执行过程中就流式返回,因此用户需要等到作业结束——通常是 10 分钟以上才可以看到结果。
- 第四,在 SQL 的翻译阶段把调试 SQL 的 Sink 替换掉,这个功能是通过改造 Flink 的 Planner 来实现的,相当于业务逻辑入侵到了 Planner 里面,这样并不优雅。
第三个痛点是 v1 版本只允许单条 DML。
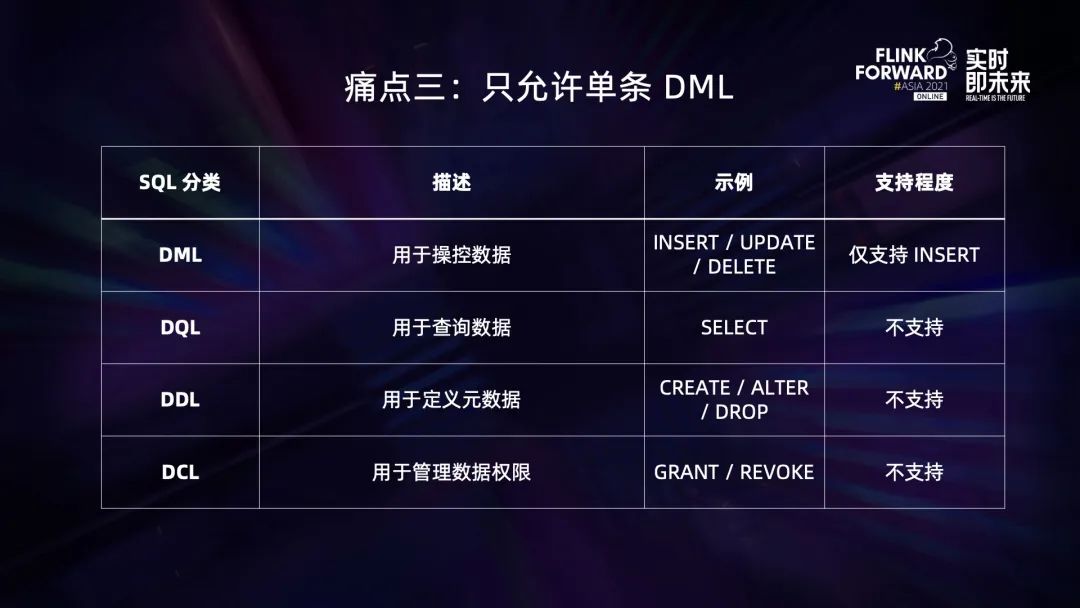
相比传统的数据库,我们支持的 SQL 语句是很有限的,比如,MySQL 的 SQL 可以分成 DML、DQL、DDL 和 DCL。
- DML 用于操控数据,常见的语句有 INSERT / UPDATE / DELETE。StreamflySQL v1 只支持了 INSERT,这和 Flink SQL 是保持一致的。Flink SQL 用 Retract 模式 — 也就是类似 Changelog 的方式 — 来表示 UPDATE/DELETE,所以只支持 INSERT,这点其实没有问题。
- DQL 用于查询数据,常见语句是 SELECT。这在 Flink SQL 是支持的,但因为缺乏 Sink 不能生成一个有意义的 Flink 作业,所以 StreamflySQL v1 不支持 DQL。
- DDL 用于定义元数据,常见语句是 CREATE / ALTER /DROP 等。这在 StreamflySQL v1 版本是不支持的,因为模板 jar 调用 SQL 的入口是 sqlUpdate,不支持纯元数据的操作,而且为纯元数据的操作单独启动一个 TableEnvironment 来执行也是完全不划算。
- 最后是 DCL,用于管理数据权限,比如 GRANT 跟 REVOKE 语句。这个 Flink SQL 是不支持的,原因是 Flink 目前只是数据的用户而不是管理者,DCL 并没有意义。
综合来看,v1 版本只支持了单条 DML,这让我们很漂亮的 SQL 编辑器变得空有其表。基于以上这些痛点,我们在今年调研并开发了 StreamflySQL v2。v2 采用的是 Server 端 SQL 编译的架构。
03
基于 SQL Gateway 的 StreamflySQL v2

我们的核心需求是解决 v1 版本的几个痛点,包括改善用户体验和提供更完整的 SQL 支持。总体的思路是采用 Server 端的 SQL 编译的架构,提高可拓展性和性能。此外,我们的集群部署模式也改成 Session Cluster,预先准备好集群资源,省去启动 YARN application 的时间。
这里会有两个关键问题。
- 首先是我们要完全自研还是基于开源项目?在调研期间我们发现 Ververica 的 SQL Gateway 项目很符合我们需求,容易拓展而且是 Flink 社区 FLIP-91 SQL Gateway 的一个基础实现,后续也容易与社区的发展方向融合。
- 第二个问题是,SQL Gateway 本身有提交作业的能力,这点跟我们已有的 Lambda 平台是重合的,会造成重复建设和难以统一管理的问题,比如认证授权、资源管理、监控告警等都会有两个入口。那么两者应当如何进行分工?我们最终的解决方案是,利用 Session Cluster 的两阶段调度,即资源初始化和作业执行是分离的,所以我们可以让 Lambda 负责 Session Cluster 的管理,而 StreamflySQL 负责 SQL 作业的管理,这样能复用 Lambda 大部分的基础能力。
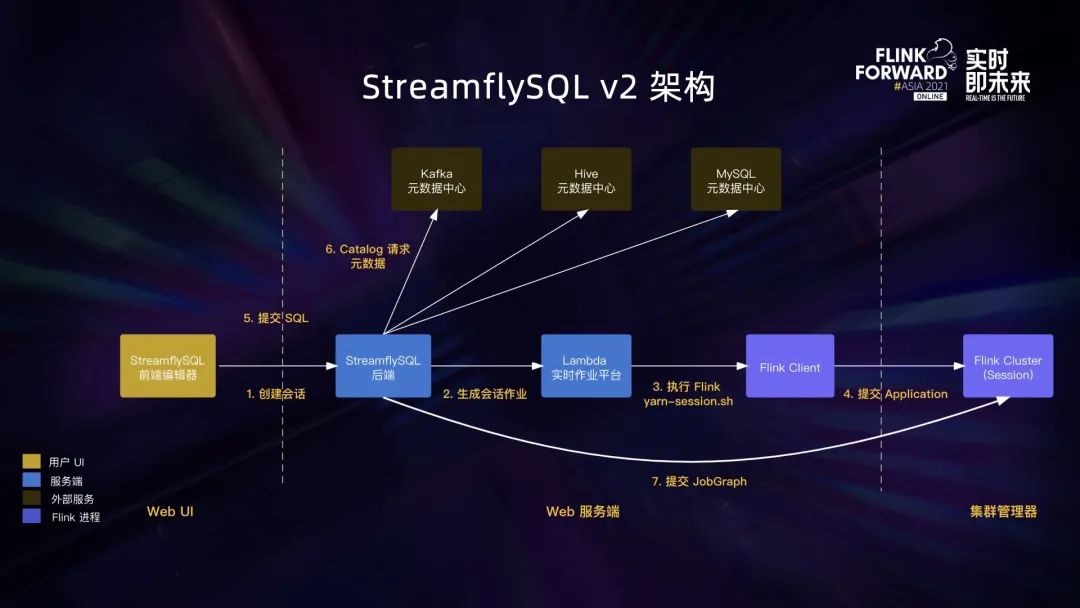
这是 StreamflySQL v2 的架构图。我们将 SQL Gateway 内嵌到 SpringBoot 应用中,开发了新的后端。总体看起来比 v1 版本要复杂,原因是原本的一级调度变成了会话和作业的两级调度。
首先用户需要创建一个 SQL 会话,StreamflySQL 后端会生成一个会话作业。在 Lambda 看来会话作业是一种特殊作业,启动时会使用 yarn-session 的脚本来启动一个 Flink Session Cluster。在 Session Cluster 初始化之后,用户就可以在会话内去提交 SQL。StreamflySQL 后端会给每个会话开启一个 TableEnvironment,负责执行 SQL 语句。如果是只涉及元数据的 SQL,会直接调用 Catalog 接口完成,如果是作业类型的 SQL,会编译成 JobGraph 提交到 Session Cluster 去执行。

v2 版本很大程度上解决了 v1 版本的几个痛点:
- 在响应时间方面,v1 常常会需要 1 分钟左右,而 v2 版本通常在 10 秒内完成。
- 在调试预览方面,v2 不需要等作业结束,而是在作业运行时,将结果通过 socket 流式地返回。这点是依赖了 SQL gateway 比较巧妙的设计。对于 select 语句,SQL Gateway 会自动注册一个基于 socket 的临时表,并将 select 结果写入到这个表。
- 在 SQL 支持方面,v1 只支持 DML,而 v2 借助于 SQL Gateway 可以支持 DML/DQL/DDL。
不过 SQL Gateway 虽然有不错的核心功能,但我们使用起来并不是一帆风顺,也遇到一些挑战。
首先最为重要的是元数据的持久化。

SQL Gateway 本身的元数据只保存在内存中,如果进程重启或是遇到异常崩溃,就会导致元数据丢失,这在企业的生产环境里面是不可接受的。因此我们将 SQL Gateway 集成到 SpringBoot 程序之后,很自然地就将元数据保存到了数据库。
元数据主要是会话元数据,包括会话的 Catalog、Function、Table 和作业等等。这些元数据按照作用范围可以分为 4 层。底下的两层是全局的配置,以配置文件的形式存在;上面两层是运行时动态生成的元数据,存在数据库中。上层的配置项优先级更高,可以用于覆盖下层的配置。
我们从下往上看这些元数据:
- 最底层是全局的默认 Flink Configuration,也就是我们在 Flink Home 下的 flink-conf yaml 配置。
- 再上面一层是 Gateway 自身的配置,比如部署模式(比如是 YARN 还是 K8S),比如默认要出册的 Catalog 和 Function 等等。
- 第三层是 Session 会话级别的 Session Configuraion,比如会话对应的 Session Cluster 的集群 ID 或者 TaskManager 的资源配置等等。
- 最上面一层是 Job 级别的配置,包括作业动态生成的元数据,比如作业 ID、用户设置 checkpoint 周期等等。
这样比较灵活的设计除了解决了元数据持久化的问题,也为我们的多租户特性奠定了基础。
第二个挑战是多租户。
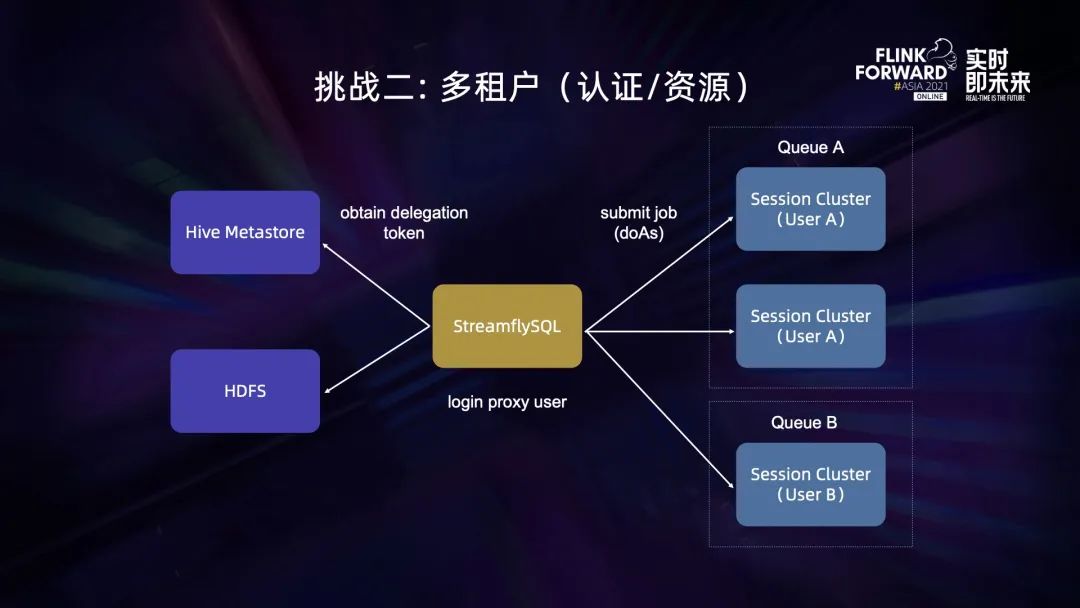
多租户分为资源和认证两个方面:
- 在资源方面,StreamflySQL 利用 Lambda 作业平台可以在不同的队列启动 Session Cluster,它们的 Master 节点和资源很自然就是隔离的,所以没有像 Spark Thrift Server 那样不同用户共用一个 Master 节点和混用资源的问题。
- 在认证方面,因为 Session Cluster 属于不同用户,所以 StreamflySQL 后端需要实现多租户的伪装。在网易游戏,组件一般会使用 Kerberos 认证。我们采用多租户实现的方式是使用 Hadoop 的 Proxy User,先登录为超级用户,然后伪装成项目用户来向不同组件获取 delegation token,这里的组件主要是 Hive MetaStore 跟 HDFS,最后把这些 token 存到 UGI 里面并用 doAS 的方式来提交作业。
第三个挑战是水平拓展。
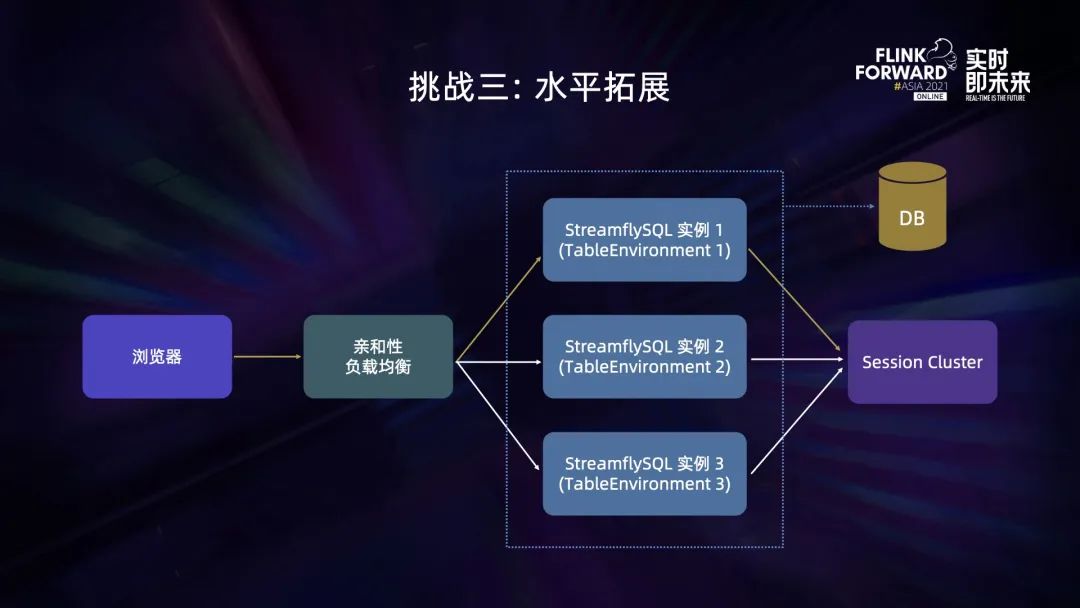
为了高可用和拓展服务能力,StreamflySQL 很自然需要以多实例的架构部署。因为我们已经将主要的状态元数据存到数据库,我们可以随时从数据库构建出一个新的 TableEnvironment,所以 StreamflySQL 实例类似普通 Web 服务一样非常轻,可以很容易地扩容缩容。
但是并不是所有状态都可以持久化的,另外有些状态我们故意会不持久化。比如用户使用 SET 命令来改变 TableEnvironment 的属性,比如开启 Table Hints,这些属于临时属性,会在重建 TableEnvironment 后被重置。这是符合预期的。再比如用户提交 select 查询做调试预览时,TaskManager 会与 StreamflySQL 后端建立 socket 链接,而 socket 链接显然也是不可持久化的。因此我们在 StreamflySQL 的多实例前加了亲和性的负载均衡,按照 Session ID 来调度流量,让在正常情况下同一个用户的请求都落到同一个实例上,确保用户使用体验的连续性。
第四个挑战是作业状态管理。

其实这里的状态一词是双关,有两个含义:
- 第一个含义是作业的运行状态。SQL gateway 目前只是提交 SQL 并不监控后续的运行状态。因此,StreamflySQL 设置了监控线程池来定时轮询并更新作业状态。因为 StreamflySQL 是多实例的,它们的监控线程同时操作同一个作业的话,可能会有更新丢失的问题,所以我们这里使用了 CAS 乐观锁来保证过时的更新不会生效。然后我们会在作业异常退出或者无法获取状态时进行告警,比如 JobManager 进行 failover 的情况下,我们无法得知 Flink 作业的状态,这时系统就会发出 disconnected 的异常状态告警。
- 第二个含义是 Flink 的持久化状态,即 Flink State。原生的 SQL gateway 并没有管理 Flink 的 Savepoint 和 Checkpoint,因此我们加上了 stop 和 stop-with-savepoint 的功能,并强制开启 retained checkpoint。这使得在作业遇到异常终止或者简单 stop 之后,再次重启时系统可以自动查找到最新的 checkpoint。
这里我可以分享下我们的算法。其实自动查找最新 checkpoint 的功能 Lambda 也有提供,但是 Lambda 假设作业都是 Per-Job Cluster,因此只要查找集群 checkpoint 目录里最新的一个 checkpoint 就可以了。但这样的算法对 StreamflySQL 却不适用,因为 Session Cluster 有多个作业,最新的 checkpoint 并不一定是我们目标作业的。因此,我们改为了使用类似 JobManager HA 的查找方式,先读取作业归档目录元数据,从里面提取最新的一个 checkpoint。
04
未来工作

- 未来我们首先要解决的一个问题是 State 迁移的问题,即用户对 SQL 进行变更后,如何从原先的 Savepoint 进行恢复。目前只能通过变更类型来告知用户风险,比如通常而言加减字段不会造成 Savepoint 的不兼容,但如果新增一个 join 表,造成的影响就很难说了。因此后续我们计划通过分析 SQL 变更前后的执行计划,来预先告知用户变更前后的状态兼容性。
- 第二个问题是细粒度的资源管理。目前我们并不能在作业编译时去指定 SQL 的资源,比如 TaskManager 的 CPU 和内存在 Session Cluster 启动之后就确定了,是会话级别的。目前调整资源只能通过作业并行度调整,很不灵活并且容易造成浪费。现在 Flink 1.14 已经支持了 DataStream API 的细粒度资源管理,可以在算子级别设置资源,但 SQL API 现在还没有计划,后续我们可能参与进去推动相关议案的进展。
- 最后是社区贡献。我们对 SQL Gateway 有一定使用经验,而且也对其进行了不少的改进,后续希望这些改进能回馈给 Flink 社区,推动 FLIP-91 SQL Gateway 的进展。