
只用一张训练图像进行图像的恢复
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:George Seif
编译:ronghuaiyang
计算机视觉的深度学习应用往往需要大量的图像数据集,现在我告诉你,只有一张图像也可以训练,是不是非常神奇?
电影的画面很炫,但是计算机视觉可以让它们变得更炫!
电影中使用计算机视觉进行各种各样的事情,如动作捕捉、特效和计算机生成图像(CGI)。最常见和最老套的用法之一是在动作片中的“can you enhance that?”。这通常是一些联邦调查局/中央情报局/酷酷的特工,在看到他们需要追捕的人的照片时说的。图像被质量很差,很难看清楚,所以他们告诉技术人员需要“增强”,这样他们就能看到坏人的脸。这种“增强”效果在电影中看起来相当强烈,几乎就像戴上一副没有眼镜就看不见的眼镜!

但你可能已经猜到了,真实的情况并不总是像电影那么容易!人工智能(AI)和计算机视觉还没有达到那个阶段,但我们正在接近这个阶段。
通常,当我们训练一个深度神经网络进行图像恢复时,我们需要训练数据……大量的训练数据,成千上万甚至上百万的训练图像。这使得个人和组织都很难建立健壮的图像恢复系统,因为获取培训数据在时间和金钱上都是昂贵的。
幸运的是,现在这个成本和对大型训练数据集的需求有望降低。最近的计算机视觉研究Deep Image Prior将帮助我们解决这个问题。
一个标准的图像恢复pipeline的工作如下。我们收集大量损坏和未损坏的图像对数据集,简单地说,这基本上就是难看和好看的图像对。接下来的想法是训练一个深度网络来学习坏图像和好图像之间的映射。一旦经过训练,网络就会理想地知道,当你给它一个糟糕的图像时,它应该输出同一个图像的一个改进版本:更清晰、更清晰、更美观。
这些网络很容易训练。使用Keras、TensorFlow或Pytorch在Python中编程非常简单,我们使用一个简单的均方误差作为损失函数,定义为:
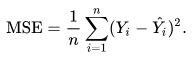
其中n为训练集中的图像个数,Y为ground truth good image, Y-hat为网络预测的good image。传统方法上,训练网络需要收集大量的训练图像,然后等待很长时间让网络完成训练。
现在有了Deep Image Prior就不用这样了。作者只使用一张损坏的图像来训练他们的网络。网络的输入是损坏的图像,输出也是同样损坏的图像。我们训练网络优化这个映射来预测它自己的输入。
那么,为什么这样可以有用呢?这里是作者非常聪明的观察。
当我们试图恢复一个图像时,我们实际上是在努力平衡两件事:(1)使我们损坏的图像不那么损坏,例如通过减少噪声,这使得图像看起来更自然,因为它是无噪音的(2)仍然保持整个图像的结构。
例如,如果我们想从输入图像中去除所有的噪声,我们可以从技术上使输出图像全部为黑色,一个全黑的图像没有任何噪音!但我们不只是想去除噪音,我们还想保持图像的结构,如果我们的输入图像是一辆车,我们仍然希望输出看起来像同一辆车,只是去除噪声。
均方误差函数将确保图像结构得到维护,我们的车仍然看起来像一辆车,因为当像素接近ground truth时,误差会很小。
为了去除噪声并使图像看起来“自然”,我们实际上可以利用深层网络的“结构”来强制输出“自然”。作者注意到,通过他们的观察,他们发现网络本身的结构可以驱动输出自然的,未损坏的图像。这篇论文的主旨是,卷积神经网络(CNNs)在某种程度上与自然图像“相似”,或者至少偏向于自然图像。
所以当你训练的时候,取任何你想要恢复的损坏的图像。使用它作为你的单一训练图像,既作为输入,也作为ground truth。误差函数为预测图像与ground truth之间的MSE(与输入相同),MSE负责维护图像结构。由于我们的网络倾向于输出一个自然的图像,我们可以相信它能输出我们想要的无噪声图像。当只使用一个“单一”图像进行训练时,请查看以下针对不同恢复任务的结果。

感谢AI社区中开源思想的美妙之处,这里有一个可以公开使用的Deep Image Prior实现(https://github.com/DmitryUlyanov/deep-image-prior)!下面是如何使用它的方法。
首先克隆仓库
git clone https://github.com/DmitryUlyanov/deep-image-prior安装需要的库
pip install numpy
pip install scipy
pip install matplotlib
pip install jupyter
pip install scikit-image
pip install torch torchvision不需要任何预训练的模型,因为只有一个图像,训练超级快!
启动Jupyter notebook
jupyter notebook现在你可以为你想要尝试的任何任务选择一个notebook!notebook超短,使用方便!如果你希望恢复你自己损坏的图像(并将其用于训练),那么你将希望使用你自己的图像替换net_input数组。读取损坏的图像并将其传递给net_input。
看到了吧!图像恢复只有一个训练图像!

英文原文:https://towardsdatascience.com/can-you-enhance-that-image-restoration-with-1-training-image-b54989a57b4d
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~