
(附代码)Kaggle竞赛中使用YoloV5将物体检测的性能翻倍的心路历程
全网搜集目标检测文章,人工筛选最优价值知识,避免垃圾信息轰炸
作者 | Mostafa Ibrahim
编译 | ronghuaiyang
我花了三个月的时间深入研究物体检测。我尝试了很多方法,从实现最先进的模型,如YoloV5、VFNets、DETR,到将目标检测模型与图像分类模型融合以提高性能。在比赛的早期阶段,我努力提高基准模型的分数,但我找不到有用的在线资源,这就是我写这篇文章的原因。我想带你们踏上一段从头到尾的旅程,简要地向你们展示我所走的每一步,我的成绩几乎翻了一倍。
官方的竞赛指标是(mean) Average Precision,这是最常用的目标检测指标之一。为了向你展示每一步的进步,我将在旁边加上它的分数。
1、第一步是建立一个简单的基线,0.126 mAP
我敢肯定,这是大量数据科学家早前落入的陷阱。我们总是很兴奋地用我们能想到的每一种技术来做最复杂的模型。这是一个巨大的错误,你最终会感到沮丧并离开ML项目,即使你不这样做,你也很可能会过拟合。
我经历了惨痛的教训,但最终还是用以下规范构建了一个初始模型:
YoloV5-XL 图像的分辨率从3K调整为512
我知道这听起来很简单,一开始我也是这么想的。但是,实际上,构建基线可能是最烦人的步骤之一。因为有很多步骤,比如将输出处理成竞赛的格式等等(我不想深入讨论)。
另外,我实际的初始YoloV5-XL模型只有0.064(上面的一半),我花了2周的时间调试它,结果发现我没有正确地归一化输入数据!
2、去掉一个输入类别!0.143 mAP (+13%)
这个trick当时对我来说没有多大意义。14个输入类别,13种不同疾病,1个“No Finding”类别。大约70%的数据集属于“No Finding”类,只有30%属于其他类。有个参赛者发现,你可以去掉这个类,并使用“2 class filter”技巧来预测它(见下文)。这使得数据集的倾斜度大大降低。此外,它允许训练明显更快(因为你将训练更少的图像)。
3、增加训练和推理图像的分辨率,0.169 mAP (+18%)
第二步是将图像分辨率从512提高到1024。这是一个微不足道的改进,但我想在这里传达的重点是,如果我以这个分辨率开始,我可能不会进一步提高我的分数。原因很简单,因为在这个更高的分辨率上进行训练会导致批大小从16减少到4(为了不耗尽GPU内存),这大大减慢了训练过程。这意味着更慢的实验,你不会想用更慢的实验来比赛……
4、融合EfficientNet和YoloV5,0.196 mAP (+16%)
这不是我的主意,我是从一个public kernel中得到的想法。但是,这是我在Kaggle比赛中遇到的最好的主意之一。我想强调的是,在Kaggle上进行比赛的一个主要好处是你可以从社区中学到很多东西。
这里的主要思想是训练一个图像分类模型(EfficientNet),它可以实现非常高的AUC(约0.99),并找到一种方法将其与目标检测模型融合。这被称为“2 class filter”,比赛中的每个人都采用了这个方法,因为它大大提高了分数。我会在下一篇文章中介绍。
5、加权框融合(WBF)后处理,0.226 mAP (+15%)
这对我来说也是一个全新的想法,在网上很难找到。加权框融合是一种对目标检测模型产生的框进行过滤,从而使结果更加准确和正确的技术。它的性能超过了现有的类似方法,如NMS和soft-NMS。具体内容我会在另一篇文章介绍。
应用WBF的结果是这样的:
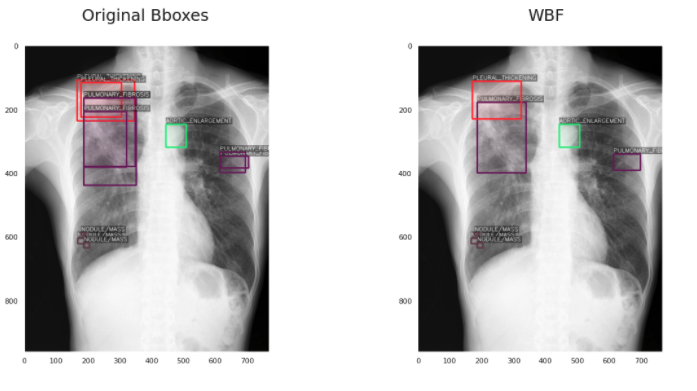
6、用5折交叉验证使用WBF融合,0.256 mAP (+13%)
我犯过的一个最大的错误是我忘记做交叉验证,这也是我写这篇文章的主要原因之一,就是为了强调ML基础知识的重要性。我太专注于应用新技术和提高性能,以至于忘记了应用这个基本的ML技术。
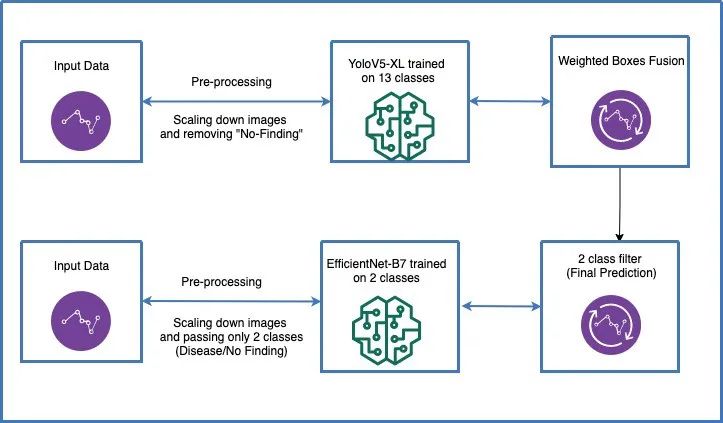
如果你想知道我是如何得到0.256的,那是因为我读了一些在竞赛结束后发布的解决方案,这是在类似于我的模型的交叉验证后他们大多数能得到的结果。最终的pipeline可以在这里看到:
7、我尝试过的其他的东西,但是没有成功
DETR训练。DETR是一个了不起的目标检测transformer ,我想把它实践,但是,我没有发现他们提供的代码文档有什么帮助,我也找不到很多有用的资源。此外,我花了大约3周的时间(大约是比赛持续时间的四分之一)尝试让它工作。我这么说的原因是,虽然离开你一直在研究的解决方案可能很难,但在实验性ML的世界里,这有时不得不做,说实话,我希望我可以早一点离开。但是,好的一面是,我发现另一个名为MMDetection的库提供了DETR,而且使用起来容易得多。 WBF预处理,虽然很多竞争对手都说这提高了他们的分数,但并没有提高我的分数。这就是ML的特点,并不是所有的技术都能以同样的方式使不同的模型受益。
我最终的代码:https://github.com/mostafaibrahim17/VinBigData-Chest-Xrays-Object-detection-
双一流高校研究生团队创建 ↓
专注于目标检测原创并分享相关知识 ☞
整理不易,点赞三连!