
【HTTP】267- HTTP 的15个常见知识点复习
前言
自从入职新公司到现在,我们前端团队内部一直在做 📖每周一练 的知识复习计划,我之前整理了一个 [每周一练 之 数据结构与算法] (https://juejin.im/post/5ce2a20e6fb9a07ebb05061c) 学习内容,大家也快去看看~~
最近三周,主要复习 网络基础 相关的知识,今天我把这三周复习的知识和参考答案,整理成本文,欢迎各位朋友互相学习和指点,觉得本文不错,也欢迎点赞哈💕💕。
特别喜欢现在的每周学习和分享,哈哈哈~~😄
📅推荐一个 github 仓库 —— [《awesome-http》] (https://github.com/semlinker/awesome-http),内容挺棒的。
注:本文整理资料来源网络,有些图片/段落找不到原文出处,如有侵权,联系删除。
一. 简述浏览器输入 URL 地址后发生的事情
1.1 描述
浏览器向 DNS 服务器查找输入 URL 对应的 IP 地址。
NS 服务器返回网站的 IP 地址。
浏览器根据 IP 地址与目标 web 服务器在 80 端口上建立 TCP 连接。
浏览器获取请求页面的 HTML 代码。
浏览器在显示窗口内渲染 HTML 。
窗口关闭时,浏览器终止与服务器的连接。
1.2 TCP 知识点补充
参考文章:[《TCP三次握手和四次挥手协议》] (http://swiftlet.net/archives/1082)
建立 TCP 需要三次握手才能建立,而断开连接则需要四次握手。整个过程如下图所示:
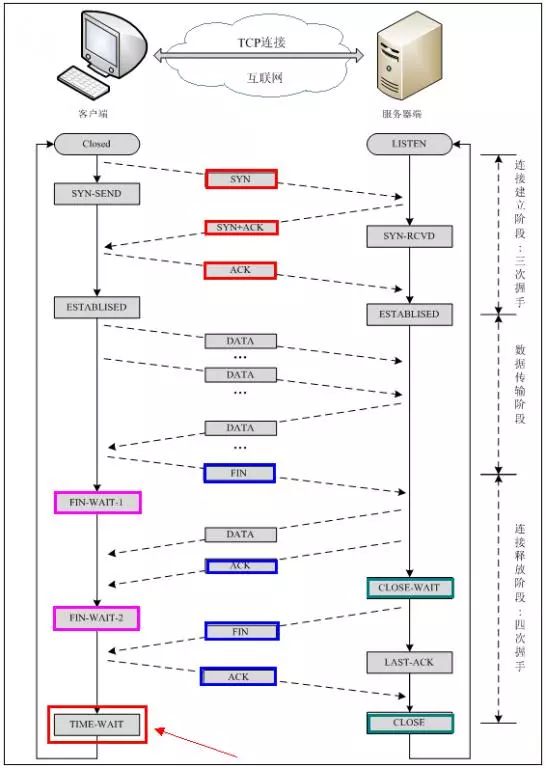
TCP三次握手:
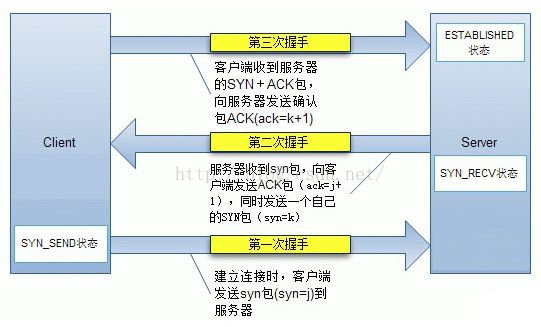
所谓的三次握手,是指建立一个 TCP 连接时,需要客户端和服务器端总共发送三个包,三次握手的目的是连接服务器的指定端口,建立 TCP 连接,并同步连接双方的序列号和确认号并交换 TCP 窗口大小信息,在 SOCKET 编程中,客户端执行 connect() 时,将会触发三次握手:
TCP四次挥手:
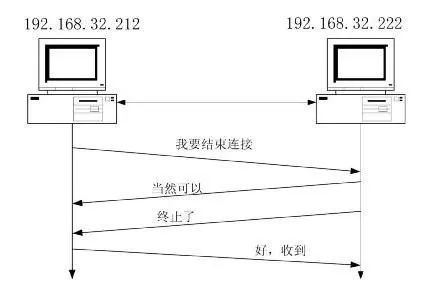
TCP连接的拆除需要发送四个包,客户端或者服务器端均可主动发起挥手动作,在SOCKET编程中,任何一方执行close()即可产生挥手操作。
2. 请介绍常见的 HTTP 状态码(至少五个)
状态码是由 3 位数组成,第一个数字定义了响应的类别,且有五种可能取值:
1xx:指示信息–表示请求已接收,继续处理。
100 客户必须继续发出请求
101 客户要求服务器根据请求转换HTTP协议版本
2xx:成功–表示请求已被成功接收、理解、接受。
200 (成功) 服务器已成功处理了请求。 通常,这表示服务器提供了请求的网页。
201 (已创建) 请求成功并且服务器创建了新的资源。
202 (已接受) 服务器已接受请求,但尚未处理。
3xx:重定向–要完成请求必须进行更进一步的操作。
300 (多种选择) 针对请求,服务器可执行多种操作。 服务器可根据请求者 (user agent) 选择一项操作,或提供操作列表供请求者选择。
301 (永久移动) 请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。
302 (临时移动) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
4xx:客户端错误–请求有语法错误或请求无法实现。
400 (错误请求) 服务器不理解请求的语法。
401 (未授权) 请求要求身份验证。 对于需要登录的网页,服务器可能返回此响应。
403 (禁止) 服务器拒绝请求。
5xx:服务器端错误–服务器未能实现合法的请求。
500 (服务器内部错误) 服务器遇到错误,无法完成请求。
501 (尚未实施) 服务器不具备完成请求的功能。 例如,服务器无法识别请求方法时可能会返回此代码。
502 (错误网关) 服务器作为网关或代理,从上游服务器收到无效响应。
503 (服务不可用) 服务器目前无法使用(由于超载或停机维护)。 通常,这只是暂时状态。
504 (网关超时) 服务器作为网关或代理,但是没有及时从上游服务器收到请求。
505 (HTTP 版本不受支持) 服务器不支持请求中所用的 HTTP 协议版本。
3. 请介绍常见的 HTTP 头部(至少五个)
3.1 HTTP 头部
更多完整内容,可以查看 [《HTTP响应头和请求头信息对照表》] (tools.jb51.net/table/http_header)
| 首部字段名 | 说明 |
|---|---|
Accept | 告诉服务器,客户端支持的数据类型。 |
Accept-Charset | 告诉服务器,客户端采用的编码。 |
Accept-Encoding | 告诉服务器,客户机支持的数据压缩格式。 |
Accept-Language | 告诉服务器,客户机的语言环境。 |
Host | 客户机通过这个头告诉服务器,想访问的主机名。 |
If-Modified-Since | 客户机通过这个头告诉服务器,资源的缓存时间。 |
Referer | 客户机通过这个头告诉服务器,它是从哪个资源来访问服务器的。(一般用于防盗链) |
User-Agent | 客户机通过这个头告诉服务器,客户机的软件环境。 |
Cookie | 客户机通过这个头告诉服务器,可以向服务器带数据。 |
Connection | 客户机通过这个头告诉服务器,请求完后是关闭还是保持链接。 |
Date | 客户机通过这个头告诉服务器,客户机当前请求时间 |
3.2 Request Header
参考文章:[《HTTP常用头部信息》] (https://www.cnblogs.com/amiezhang/p/9389840.html)
举例:
| Request Header | 描述 |
|---|---|
GET/sample.JspHTTP/1.1 | 请求行 |
Host:www.uuid.online/ | 请求的目标域名和端口号 |
Origin:http://localhost:8081/ | 请求的来源域名和端口号 (跨域请求时,浏览器会自动带上这个头信息) |
Referer:https:/localhost:8081/link?query=xxxxx | 请求资源的完整URI |
User-Agent:Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/67.0.3396.99Safari/537.36 | 浏览器信息 |
Cookie:BAIDUID=FA89F036:FG=1;BD_HOME=1;sugstore=0 | 当前域名下的Cookie |
Accept:text/html,image/apng | 代表客户端希望接受的数据类型是html或者是png图片类型 |
Accept-Encoding:gzip,deflate | 代表客户端能支持 gzip 和 deflate 格式的压缩 |
Accept-Language:zh-CN,zh;q=0.9 | 代表客户端可以支持语言 zh-CN 或者 zh (值得一提的是q(0~1)是优先级权重的意思,不写默认为1,这里 zh-CN 是1, zh 是0.9) |
Connection:keep-alive | 告诉服务器,客户端需要的 tcp 连接是一个长连接 |
3.3 Response Header
参考文章:[《HTTP常用头部信息》] (https://www.cnblogs.com/amiezhang/p/9389840.html)
举例:
| Response Header | 描述 |
|---|---|
HTTP/1.1200OK | 响应状态行 |
Date:Mon,30Jul201802:50:55GMT | 服务端发送资源时的服务器时间 |
Expires:Wed,31Dec196923:59:59GMT | 较过时的一种验证缓存的方式,与浏览器(客户端)的时间比较,超过这个时间就不用缓存(不和服务器进行验证),适合版本比较稳定的网页 |
Cache-Control:no-cache | 现在最多使用的控制缓存的方式,会和服务器进行缓存验 |
etag:"fb8ba2f80b1d324bb997cbe188f28187-ssl-df" | 一般是Nginx静态服务器发来的静态文件签名,浏览在没有 “Disabled cache” 情况下,接收到 etag 后,同一个 url 第二次请求就会自动带上 “If-None-Match” |
Last-Modified:Fri,27Jul201811:04:55GMT | 服务器发来的当前资源最后一次修改的时间,下次请求时,如果服务器上当前资源的修改时间大于这个时间,就返回新的资源内容 |
Content-Type:text/html;charset=utf-8 | 如果返回是流式的数据,我们就必须告诉浏览器这个头,不然浏览器会下载这个页面,同时告诉浏览器是utf8编码,否则可能出现乱码 |
Content-Encoding:gzip | 告诉客户端,应该采用gzip对资源进行解码 |
Connection:keep-alive | 告诉客户端服务器的tcp连接也是一个长连接 |
4. 请列举常用的 HTTP 方法,并介绍 GET 与 POST 请求之间的区别
4.1 HTTP Request Method
参考文章:[《HTTP请求方法对照表》] (http://tools.jb51.net/table/httprequestmethod/)
根据 HTTP 标准,HTTP 请求可以使用多种请求方法。 HTTP1.0 定义了三种请求方法: GET, POST 和 HEAD方法。 HTTP/1.1 新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
| 序号 | 方法 | 描述 |
|---|---|---|
| 1 | GET | 请求指定的页面信息,并返回实体主体。 |
| 2 | HEAD | 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| 3 | POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。 |
| 4 | PUT | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| 5 | DELETE | 请求服务器删除指定的页面。 |
| 6 | CONNECT | HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。 |
| 7 | OPTIONS | 允许客户端查看服务器的性能。 |
| 8 | TRACE | 回显服务器收到的请求,主要用于测试或诊断。 |
| 9 | PATCH | 实体中包含一个表,表中说明与该URI所表示的原内容的区别。 |
| 10 | MOVE | 请求服务器将指定的页面移至另一个网络地址。 |
| 11 | COPY | 请求服务器将指定的页面拷贝至另一个网络地址。 |
| 12 | LINK | 请求服务器建立链接关系。 |
| 13 | UNLINK | 断开链接关系。 |
| 14 | WRAPPED | 允许客户端发送经过封装的请求。 |
| 15 | Extension-mothed | 在不改动协议的前提下,可增加另外的方法。 |
4.2 GET 与 POST 请求之间的区别
| 区别内容 | GET | POST |
|---|---|---|
| 点击返回/刷新按钮 | 没有影响 | 数据会重新发送(浏览器将会提示“数据被重新提交”) |
| 添加书签 | 可以 | 不可以 |
| 缓存 | 可以 | 不可以 |
| 编码类型(Encoding type) | application/x-www-form-rulencoded | application/x-www-form-rulencoded or multipart/form-data 请为二进制数据使用 multipart 编码 |
| 历史记录 | 有 | 没有 |
| 长度限制 | 有 | 没有 |
| 数据类型限制 | 只允许 ASCLll 字符类型 | 没有限制,允许二进制数据 |
| 安全性 | 查询字符串会显示在地址栏的 URL 上,不安全,请不要使用 GET 请求提交敏感数据 | 因为数据不会显示在地址栏中,也不会缓存下来或保存在浏览记录中,所以 POST 请求比 GET 请求安全,但也不是最安全的方式,如需要传送敏感数据,请使用数据加密。 |
| 可见性 | 查询字符串在地址栏的 URL 中可见 | 查询字符串在地址栏的 URL 中不可见 |
5. 请分别介绍 Cookie 和 Session 的作用及它们之间的区别
参考文章: [《3分钟搞懂Cookie与Session》] (https://juejin.im/post/5cbf0749e51d456e781f2023)
5.1 Cookie简单介绍
Cookie是存储在用户本地计算机上,用于保存一些用户操作的历史信息,当用户再次访问我们的服务器的时候,浏览器通过HTTP协议,将他们本地的Cookie内容也发到咱们服务器上,从而完成验证。
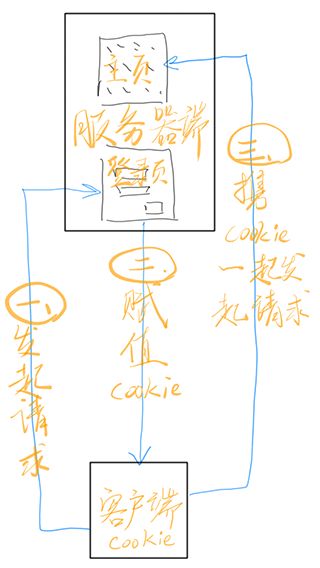
Cookie是存储在浏览器客户的一小片数据;Cookie可以同时被前台与后台操作;Cookie可以跨页面存取;Cookie是不可以跨服务器访问的;Cookie有限制; 每个浏览器存储的个数不能超过300个,每个服务器不能超过20个,数据量不能超过4K;Cookie是有生命周期的,默认与浏览器相同,如果进程退出,cookie会被销毁
5.2 Session
Session 存储在我们的服务器上,就是在我们的服务器上保存用户的操作信息。
当用户访问我们的网站时,我们的服务器会成一个 SessionID,然后把 SessionID 存储起来,再把这个 SessionID发给我们的用户,用户再次访问我们的服务器的时候,拿着这个 SessionID就能验证了,当这个ID能与我们服务器上存储的ID对应起来时,我们就可以认为是自己人。
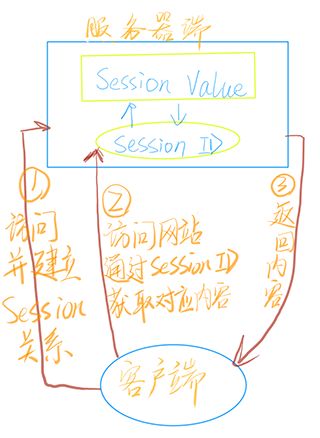
seesion数据存储在服务器端;每一个会话分配一个单独的
session_id;该
session_id通过cookie传送到前台,默认的session_id名称是PHPSESSIONID;前台只能看到
Session的ID,而不能修改Session值;使用
Session之前需要先开启会话;Session存储在Session数组$_SESSION;Session存储方式比较安全,但是如果Session数量过多,会导致服务器性能下降;
5.3 两者区别
| Cookie | session | |
|---|---|---|
| 定义 | 浏览器保存用户信息的文件,存储的数量和字符数都有限制 | 服务器把 sessionID 和用户信息、用户操作,记录在服务器上,这些记录就称为 session |
| 相同点 | 都是为了存储用户相关的信息 | |
| 存储 | 客户端 | 服务器 |
| 安全性 | 安全性不高,任何人都能直接查看 | 安全性高 |
5.4 两者结合使用
存储在服务端:通过
cookie存储一个session_id,然后具体的数据则是保存在session中。如果用户已经登录,则服务器会在cookie中保存一个session_id,下次再次请求的时候,会把该session_id携带上来,服务器根据session_id在session库中获取用户的session数据。就能知道该用户到底是谁,以及之前保存的一些状态信息。这种专业术语叫做server side session。将
session数据加密,然后存储在cookie中。这种专业术语叫做client side session。
6. 请介绍 HTTP 请求报文与响应报文格式
6.1 请求报文
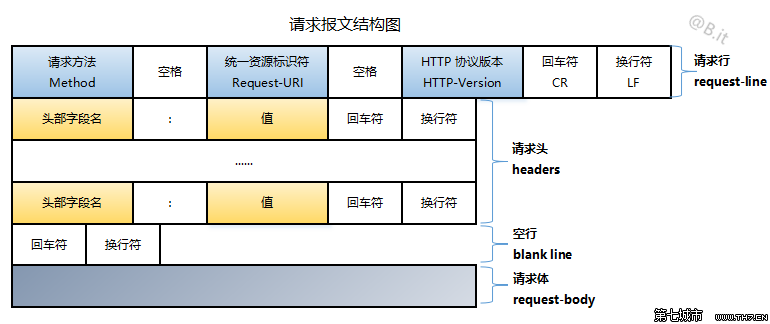
请求报文由请求行、请求头部和请求正文组成:
请求行
格式为:
请求方法+空格+ URL +空格+协议版本+回车符+换行符
例如:
GET www.baidu.com HTTP/1.1
常见的请求方法有:GET,HEAD,PUT,POST,TRACE,OPTIONS,DELETE以及扩展方法。
请求头部
格式为:
头部字段名+冒号(:)+值+回车符+换行符
请求头部为请求报文添加了一些附加信息,由“名/值”对组成,每行一对,名和值之间使用冒号分隔。
并且,在请求头部的最后会有一个空行,表示请求头部结束,这一行必不可少。
典型的请求头部有:
| 请求头部 | 说明 |
|---|---|
| Host | 接受请求的服务器地址,可以是IP:端口号,也可以是域名 |
| User-Agent | 发送请求的应用程序名称 |
| Connection | 指定与连接相关的属性,如Connection:Keep-Alive |
| Accept-Charset | 通知服务端可以发送的编码格式 |
| Accept-Encoding | 通知服务端可以发送的数据压缩格式 |
| Accept-Language | 通知服务端可以发送的语言 |
| |
一般使用在 POST 方法中, GET 方法不存在请求正文。 | |
POST 方法适用于需要客户填写表单的场合。与请求数据相关的最常使用的请求头是 Content-Type 和 Content-Length 。 |
6.2 响应报文
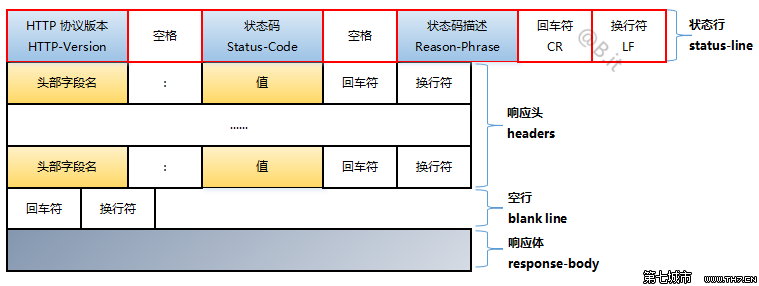
响应报文由状态行、响应头部和响应正文组成:
状态行
格式为:
协议版本+空格+状态码+空格+状态码描述+回车符+换行符
状态码划分:
100〜199的状态码是 HTTP / 1.1 向协议中引入了信息性状态码;
200〜299的状态码表示成功;
300〜399的状态码指资源重定向;
400〜499的状态码指客户端请求出错;
500〜599的状态码指服务端出错;
常见的状态码:
| 状态码 | 说明 |
|---|---|
| 200 | 响应成功 |
| 302 | 跳转,跳转地址通过响应头中的位置属性指定(JSP中Forward和Redirect之间的区别) |
| 400 | 客户端请求有语法错误,不能被服务器识别 |
| 403 | 服务器接收到请求,但是拒绝提供服务(认证失败) |
| 404 | 请求资源不存在 |
| 500 | 服务器内部错误 |
| |
| 格式为: |
头部字段名+冒号(:)+值+回车符+换行符
常见响应头部:
| 响应头部 | 说明 |
|---|---|
Server | 服务器应用程序软件的名称和版本 |
Content-Type | 响应正文的类型(是图片还是二进制字符串) |
Content-Length | 响应正文长度 |
Content-Charset | 响应正文使用的编码 |
Content-Encoding | 响应正文使用的数据压缩格式 |
Content-Language | 响应正文使用的语言 |
7. HTTP/1.1 有什么优缺点
参考文章:[《HTTP/1.0 HTTP/1.1 HTTP/2.0 主要特性对比》] (https://segmentfault.com/a/1190000013028798?utm_source=tag-newest)
对于 HTTP/1.1,不仅继承了 HTTP1.0简单的特点,还克服了诸多 HTTP1.0性能上的问题。
7.1 HTTP/1.1 优点
增加持久性连接
也就是多个请求和响应可以利用同一个 TCP 连接,而不是每一次请求响应都要新建一个TCP连接,减少了建立和关闭连接的消耗和延迟。
Connection: keep-alive
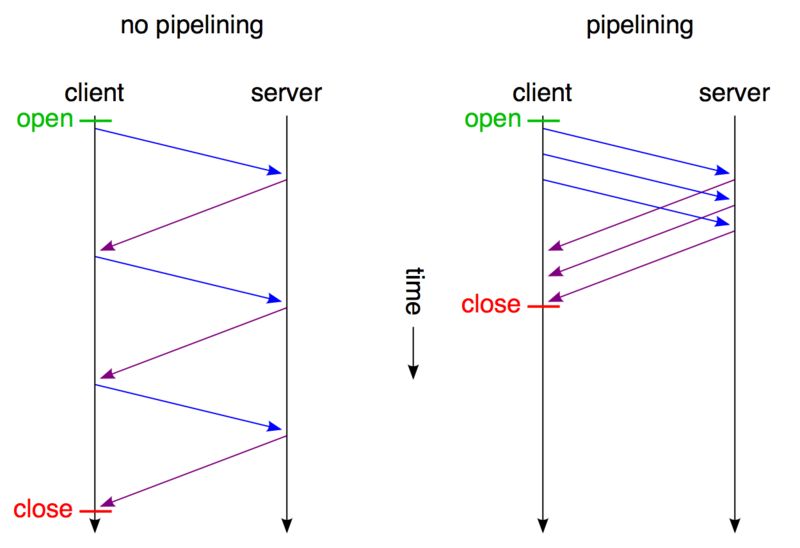
增加管道机制
增加了管道机制,请求可以同时发出,但是响应必须按照请求发出的顺序依次返回,性能在一定程度上得到了改善。
分块传输
在 HTTP/1.1 版本中,可以不必等待数据完全处理完毕再返回,服务器产生部分数据,那么就发送部分数据,很明此种方式更加优秀一些,可以节省很多等待时间。
增加
host字段
使得一个服务器能够用来创建多个 Web 站点。
错误提示
HTTP/1.1 引入了一个 Warning 头域,增加对错误或警告信息的描述,此外,在 HTTP/1.1 中新增了24个状态响应码(100,101,203,205,206,301,305… )。
带宽优化
HTTP/1.1 中在请求消息中引入了 range头域,它允许只请求资源的某个部分。
在响应消息中 Content-Range头域声明了返回的这部分对象的偏移值和长度。如果服务器相应地返回了对象所请求范围的内容,则响应码为 206(PartialContent),它可以防止 Cache将响应误以为是完整的一个对象,HTTP/1.1 加入了一个新的状态码 100(Continue)。客户端事先发送一个只带头域的请求,如果服务器因为权限拒绝了请求,就回送响应码 401(Unauthorized);如果服务器接收此请求就回送响应码 100,客户端就可以继续发送带实体的完整请求了。
注意,HTTP/1.0 的客户端不支持 100 响应码。但可以让客户端在请求消息中加入 Expect头域,并将它的值设置为 100-continue。
7.2 HTTP/1.1 缺点
队头阻塞
此版本的网络延迟问题主要由于队头堵塞导致,虽然通过持久性连接得到改善,但是每一个请求的响应依然需要按照顺序排队,如果前面的响应处理较为耗费时间,那么同样非常耗费性能。
技术不成熟
还有此版本虽然引进了管道机制,但是当前存在诸多问题,且默认处于关闭状态。
浪费资源
http/1.1 请求会携带大量冗余的头信息,浪费了很多宽带资源。
8. 相比 HTTP/1.1,HTTP/2.0 有哪些新特性
参考文章:[《HTTP1.0 HTTP/1.1 HTTP2.0 主要特性对比》] (https://segmentfault.com/a/1190000013028798?utm_source=tag-newest)
二进制分帧
在应用层(HTTP/2.0)和传输层(TCP or UDP)之间增加一个二进制分帧层,从而突破 HTTP1.1 的性能限制,改进传输性能,实现低延迟和高吞吐量。
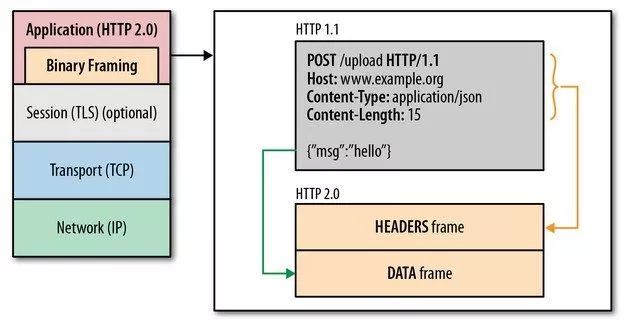
可见,虽然 HTTP/2.0 的协议和 HTTP1.x 协议之间的规范完全不同了,但是实际上 HTTP/2.0并 没有改变 HTTP1.x 的语义。
简单来说,HTTP/2.0 只是把原来 HTTP1.x 的 header 和 body 部分用 frame 重新封装了一层而已。
多路复用(连接共享)
允许同时通过单一的 HTTP/2 连接发起多重的请求-响应消息,这个强大的功能则是基于“二进制分帧”的特性。
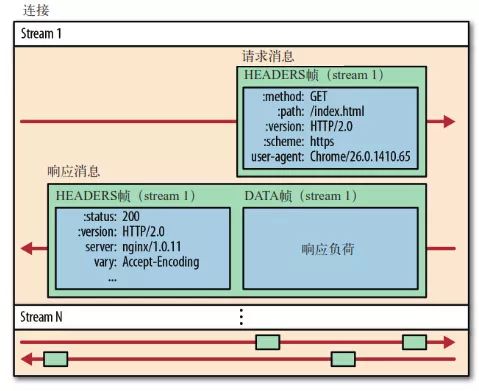
从图中可见,所有的 HTTP/2.0 通信都在一个 TCP 连接上完成,这个连接可以承载任意数量的双向数据流。
每个数据流以消息的形式发送,而消息由一或多个帧组成。这些帧可以乱序发送,然后再根据每个帧头部的流标识符( stream id)重新组装。
首部压缩
HTTP1.1 不支持 header 数据的压缩,HTTP/2.0 使用 HPACK 算法对 header 的数据进行压缩,这样数据体积小了,在网络上传输就会更快。高效的压缩算法可以很大的压缩 header ,减少发送包的数量从而降低延迟。
服务器推送
在 HTTP/2 中,服务器可以对客户端的一个请求发送多个响应,即服务器可以额外的向客户端推送资源,而无需客户端明确的请求。
9. 请简述 HTTPS 工作原理
9.1 HTTPS 简介
参考文章:[《深入浅出讲解HTTPS工作原理》] (developer.51cto.com/art/201812/589283.htm)
HTTPS 并非是应用层的一种新协议。只是 HTTP 通信接口部分用 SSL(Secure Socket Layer)和 TLS(Transport Layer Security)协议代替而已。
通常,HTTP 直接和 TCP 通信。当使用 SSL 时,则演变成先和 SSL 通信,再由 SSL 和 TCP 通信了。简言之,所谓 HTTPS,其实就是身披 SSL 协议这层外壳的 HTTP。
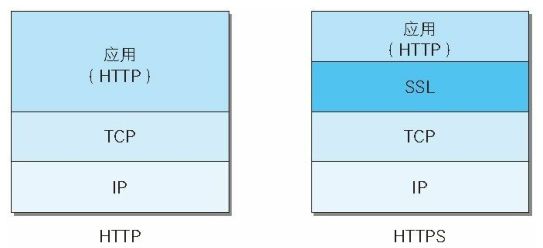
在采用 SSL 后,HTTP 就拥有了 HTTPS 的加密、证书和完整性保护这些功能。也就是说HTTP 加上加密处理和认证以及完整性保护后即是 HTTPS。
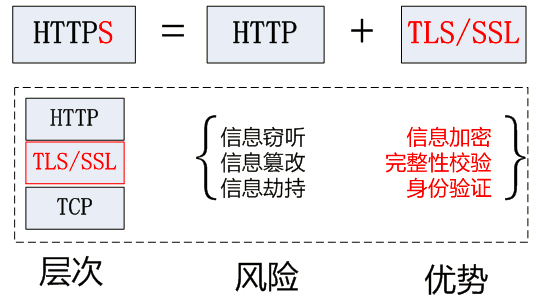
HTTPS 协议的主要功能基本都依赖于 TLS/SSL 协议,TLS/SSL 的功能实现主要依赖于三类基本算法:散列函数 、对称加密和非对称加密,其利用非对称加密实现身份认证和密钥协商,对称加密算法采用协商的密钥对数据加密,基于散列函数验证信息的完整性。
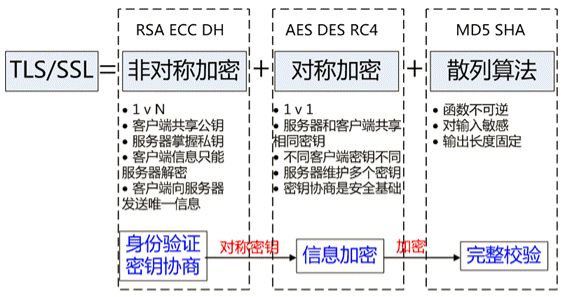
9.2 HTTPS 工作原理
HTTPS 其实是有两部分组成:HTTP + SSL / TLS,也就是在 HTTP 上又加了一层处理加密信息的模块。服务端和客户端的信息传输都会通过 TLS 进行加密,所以传输的数据都是加密后的数据。
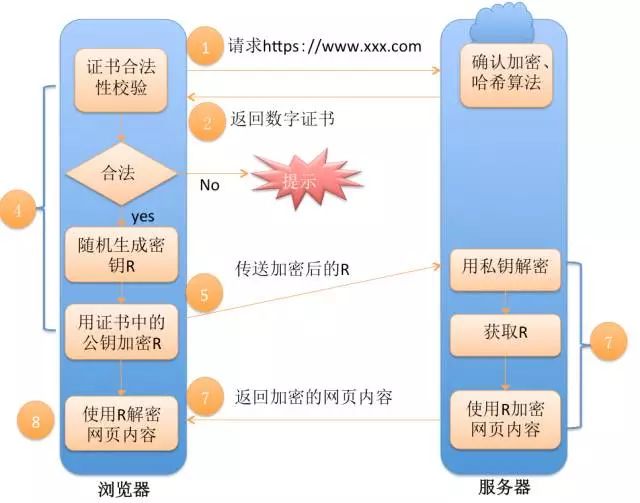
客户端发起HTTPS请求
浏览器里面输入一个HTTPS网址,然后连接到服务端的443端口上。注意这个过程中客户端会发送一个密文族给服务端,密文族是浏览器所支持的加密算法的清单。
服务端配置
采用HTTPS协议的服务器必须要有一套数字证书,可以自己制作,也可以向组织申请。区别就是自己颁发的证书需要客户端验证通过才可以继续访问,而使用受信任的公司申请的证书则不会弹出提示页面。
这套证书其实就是一对公钥和私钥,可以这么理解,公钥就是一把锁头,私钥就是这把锁的钥匙,锁头可以给别人对某个东西进行加锁,但是加锁完毕之后,只有持有这把锁的钥匙才可以解锁看到加锁的内容。
传送证书
这个证书其实就是公钥,只是包含了很多信息,如证书的颁发机构、过期时间等等。
客户端解析证书
这部分工作是由客户端的TLS来完成的,首先会验证公钥是否有效,如颁发机构、过期时间等等,如果发现异常则会弹出一个警告框,提示证书存在问题。如果证书没有问题,那么就生成一个随机值,然后用证书对该随机值进行加密。
注意一下上面提到的"发现异常"。证书中会包含数字签名,该数字签名是加密过的,是用颁发机构的私钥对本证书的公钥、名称及其他信息做hash散列加密而生成的。客户端浏览器会首先找到该证书的根证书颁发机构,如果有,则用该根证书的公钥解密服务器下发的证书,如果不能正常解密,则就是"发现异常",说明该证书是伪造的。
传送加密信息
这部分传送的是用证书加密后的随机值,目的就是让服务端得到这个随机值,然后客户端和服务端的通信就可以通过这个随机值来进行加密和解密了。
服务端解密信息
服务端用私钥解密后,得到了客户端传过来的随机值,至此一个非对称加密的过程结束,看到TLS利用非对称加密实现了身份认证和密钥协商。然后把内容通过该值进行对称加密。
传输加密后的信息
这部分是服务端用随机值加密后的信息,可以在客户端被还原。
客户端解密信息
客户端用之前生成的随机值解密服务端传送过来的信息,于是获取了解密后的内容,至此一个对称加密的过程结束,看到对称加密是用于对服务器待传送给客户端的数据进行加密用的。整个过程即使第三方监听了数据,也束手无策。
10. HTTP 和 HTTPS 的共同点和区别
https 协议需要到 ca 申请证书,一般免费证书较少,因而需要一定费用。
http 是超文本传输协议,信息是明文传输, https 则是具有安全性的ssl加密传输协议。
http 和 https 使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
http 的连接很简单,是无状态的; HTTPS 协议是由 SSL+HTTP 协议构建的可进行加密传输、身份认证的网络协议,比 http 协议安全。
11. 什么是跨域,如何解决跨域
参考文章:[《前端常见跨域解决方案(全)》] (https://segmentfault.com/a/1190000011145364)
11.1 什么是跨域
跨域,指的是浏览器不能执行其他网站的脚本。它是由浏览器的同源策略造成的,是浏览器对JavaScript施加的安全限制。
什么是同源策略?
同源策略/SOP(Same origin policy)是一种约定,由Netscape公司1995年引入浏览器,它是浏览器最核心也最基本的安全功能,如果缺少了同源策略,浏览器很容易受到 XSS 、 CSFR 等攻击。所谓同源是指"协议+域名+端口"三者相同,即便两个不同的域名指向同一个ip地址,也非同源。
同源策略限制了以下行为:
Cookie、LocalStorage和IndexDB无法读取DOM和JS对象无法获取Ajax请求发送不出去
常见跨域场景:
所谓的同源是指:域名、协议、端口均为相同。
http://www.a.cn/index.html调用http://www.a.cn/server.php非跨域。http://www.a.cn/index.html调用http://www.b.cn/server.php跨域,主域不同。http://abc.a.cn/index.html调用http://def.b.cn/server.php跨域,子域名不同。http://www.a.cn:8080/index.html调用http://www.a.cn/server.php跨域,端口不同。https://www.a.cn/index.html调用http://www.a.cn/server.php跨域,协议不同。localhost调用127.0.0.1跨域。
11.2 解决跨域
jsonp跨域document.domain+iframe跨域window.name+iframe跨域location.hash+iframe跨域postMessage跨域跨域资源共享
CORSwithCredentials属性WebSocket协议跨域node代理跨域nginx代理跨域
具体每一种解决方法,可以参考:[《前端常见跨域解决方案(全)》] (https://segmentfault.com/a/1190000011145364)
12. HTTP 中与缓存相关的头部有哪些,它们有什么区别
| 头部 | 优势和特点 | 劣势和问题 |
|---|---|---|
Expires | 1、 HTTP1.0 产物,可以在 HTTP1.0和 1.1中使用,简单易用。2、以时刻标识失效时间。 | 1、时间是由服务器发送的( UTC),如果服务器时间和客户端时间存在不一致,可能会出现问题。2、存在版本问题,到期之前的修改客户端是不可知的。 |
Cache-Control | 1、 HTTP1.1 产物,以时间间隔标识失效时间,解决了 Expires服务器和客户端相对时间的问题。2、比 Expires多了很多选项设置。 | 1、 HTTP1.1才有的内容,不适用于 HTTP1.0。2、存在版本问题,到期之前的修改客户端是不可知的。 |
Last-Modified | 1、不存在版本问题,每次请求都会去服务器进行校验。服务器对比最后修改时间如果相同则返回304,不同返回200以及资源内容。 | 1、只要资源修改,无论内容是否发生实质性的变化,都会将该资源返回客户端。例如周期性重写,这种情况下该资源包含的数据实际上一样的。2、以时刻作为标识,无法识别一秒内进行多次修改的情况。3、某些服务器不能精确的得到文件的最后修改时间。 |
ETag | 1、可以更加精确的判断资源是否被修改,可以识别一秒内多次修改的情况。2、不存在版本问题,每次请求都回去服务器进行校验。 | 1、计算 ETag值需要性能损耗。2、分布式服务器存储的情况下,计算 ETag的算法如果不一样,会导致浏览器从一台服务器上获得页面内容后到另外一台服务器上进行验证时发现 ETag不匹配的情况。 |
13. 分别介绍强缓存和协商缓存
浏览器缓存主要分为强缓存(也称本地缓存)和协商缓存(也称弱缓存)。
13.1 强缓存
强缓存是利用 http 头中的 Expires 和 Cache-Control 两个字段来控制的,用来表示资源的缓存时间。
强缓存中,普通刷新会忽略它,但不会清除它,需要强制刷新。浏览器强制刷新,请求会带上 Cache-Control:no-cache 和 Pragma:no-cache。
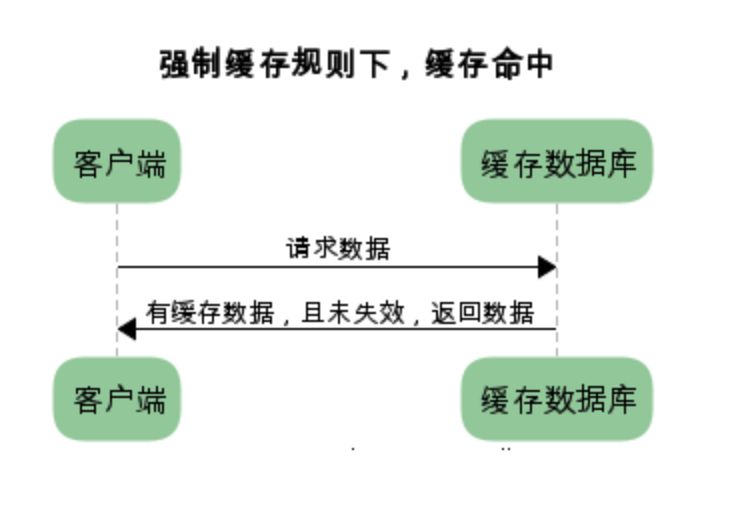
通常,强缓存不会向服务器发送请求,直接从缓存中读取资源,在chrome控制台的network选项中可以看到该请求返回200的状态码。分为 fromdisk cache 和 frommemory cache。
fromdisk cache:一般非脚本会存在内存当中,如css,html等frommemory cache:资源在内存当中,一般脚本、字体、图片会存在内存当
有缓存命中和缓存未命中状态:
13.2 协商缓存
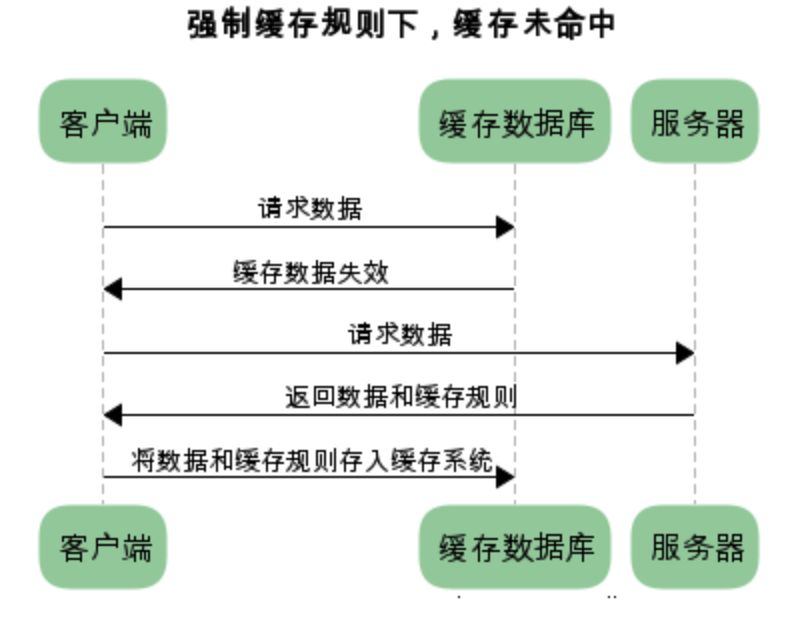
协商缓存就是由服务器来确定缓存资源是否可用,所以客户端与服务器端要通过某种标识来进行通信,从而让服务器判断请求资源是否可以缓存访问。
普通刷新会启用弱缓存,忽略强缓存。只有在地址栏或收藏夹输入网址、通过链接引用资源等情况下,浏览器才会启用强缓存,这也是为什么有时候我们更新一张图片、一个js文件,页面内容依然是旧的,但是直接浏览器访问那个图片或文件,看到的内容却是新的。
这个主要涉及到两组 header 字段: Etag 和 If-None-Match、 Last-Modified和 If-Modified-Since。
向服务器发送请求,服务器会根据这个请求的request header的一些参数来判断是否命中协商缓存。
有缓存命中和缓存未命中状态:
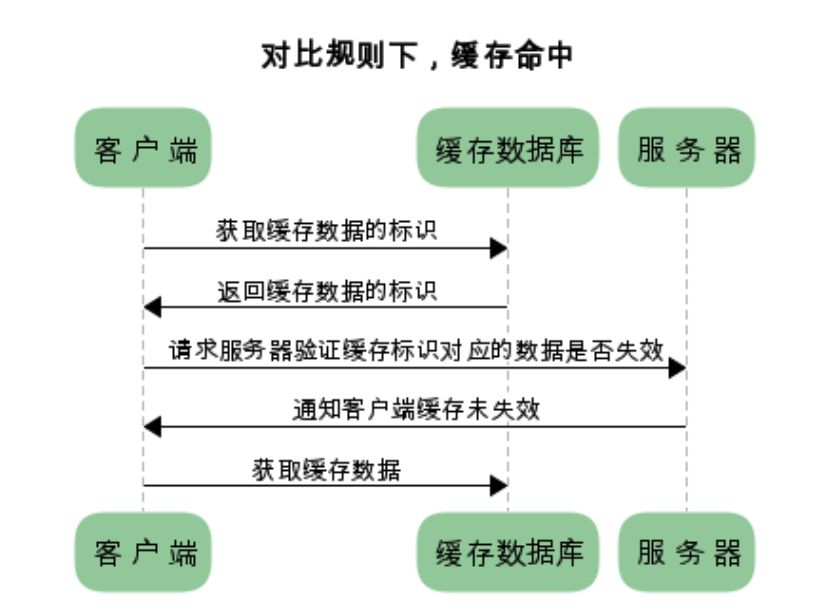
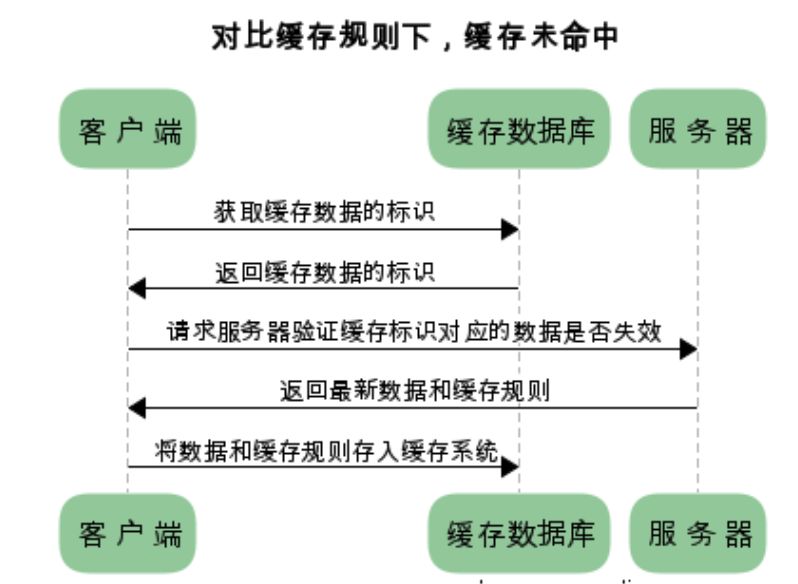
13.3 流程
浏览器第一次发起请求,本地有缓存情况: 在浏览器第一次发起请求时,本地无缓存,向web服务器发送请求,服务器起端响应请求,浏览器端缓存。过程如下:
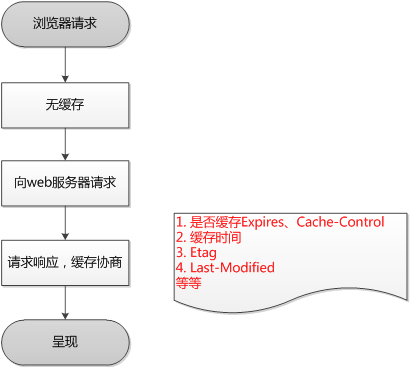
在第一次请求时,服务器会将页面最后修改时间通过 Last-Modified标识由服务器发送给客户端,客户端记录修改时间;服务器还会生成一个Etag,并发送给客户端。
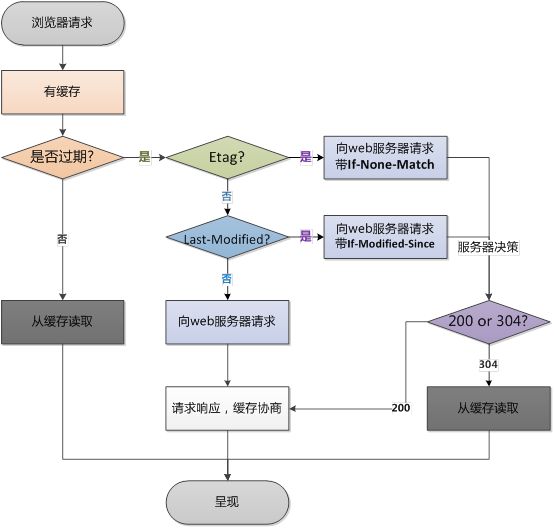
浏览器后续再次进行请求时:
14. 请简单介绍一下 LRU (Least recently used)算法
参考文章:[《LRU算法》] (https://www.jianshu.com/p/d533d8a66795)
14.1 原理
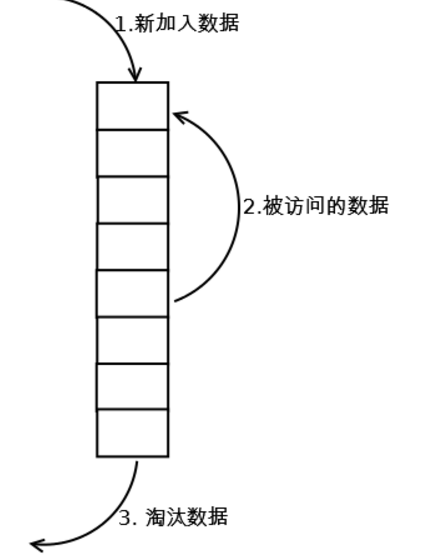
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
这里有一张比较卡通的图片:
14.2 实现
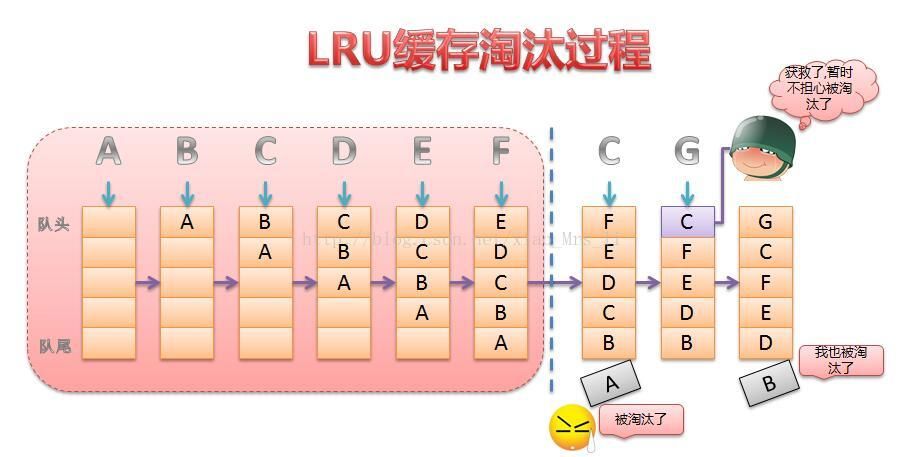
最常见的实现是使用一个链表保存缓存数据,详细算法实现如下:
新数据插入到链表头部;
每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
当链表满的时候,将链表尾部的数据丢弃。
14.3 分析
命中率
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
复杂度
实现简单。
代价
命中时需要遍历链表,找到命中的数据块索引,然后需要将数据移到头部。
结语
本文主要复习了 HTTP/HTTPS 的一些基础知识,还有 HTTP 的其他版本的知识,对于面试也好,知识沉淀也好,这些也是我们作为开发者必须懂的。
作为一名前端开发者,说实话对 HTTP/HTTPS 了解还是太少,可能和平常工作内容有关。
小狮子有话说
你好,我是 Chocolate,一个狮子座的前端攻城狮,希望成为优秀的前端博主,每周都会更新文章,与你一起变优秀~
- 关注
小狮子前端,回复【小狮子】获取为大家整理好的文章、资源合集 - 我的博客地址:
yangchaoyi.vip欢迎收藏,可在博客留言板留下你的足迹,一起交流~ - 觉得文章不错,【
点赞】【在看】支持一波 ✿✿ヽ(°▽°)ノ✿
叮咚~ 可以给小狮子加
星标,便于查找。感谢加入小狮子前端,最好的我们最美的遇见,我们下期再见~