
小哥质疑谷歌顶会论文有错,并且拿出了复现代码来证明

极市导读
快速拯救拍照手抖。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
景色很好看,可是手机相机分辨率太低,照不出清晰的照片?
没关系,试试这个超分辨率算法,让AI“自动”帮你调整分辨率。
经过算法调整后,照片几乎立刻就清晰了数倍,连角落里模糊的文字都看得清:

这是来自谷歌的一个手机超分辨率算法,此前登上过SIGGRAPH 2019顶会,阐述的是自家手机Pixel 3中使用的超分技术。
现在,这个算法确实被复现了出来,然而,方法却与论文不全一致(复现的作者Michael Kunz认为,论文有些地方写错了)。
来看看这是怎么回事。
多帧合一帧,效果更清晰
论文中,这个用手机实现超分辨率的原理,是这样的:
在用手机拍照的过程中,手部会出现轻微的震颤。

△手抖示例
这导致在连续拍摄同一景象的过程中,每张照片都会有一个微小的偏移量,这些小偏移量,恰好能提供超分辨率所需要的亚像素信息。
然后,将这些彼此之间略有差异的图像帧,进行对齐、融合,就可以得到一张每个像素位置都有红、绿、蓝三通道值的图像。
具体算法是这样的:
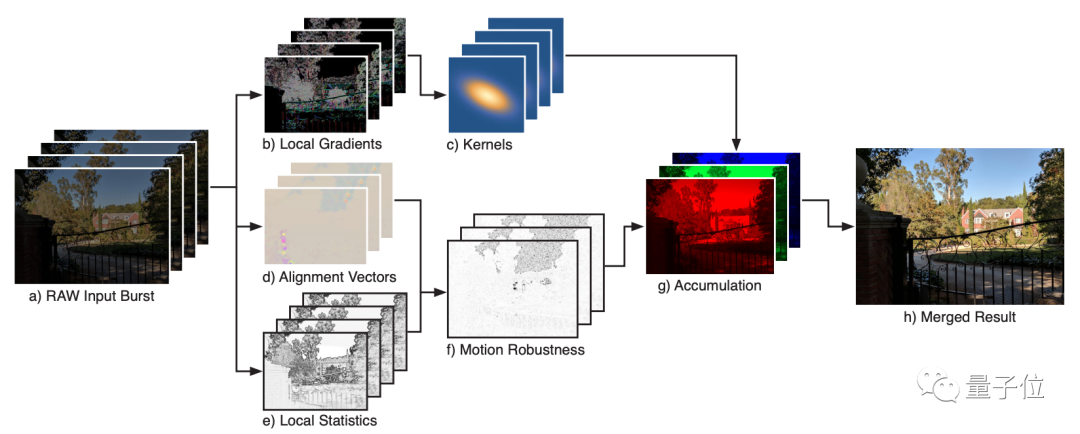
首先,获取多帧RAW图像;然后,选择其中一帧作为基准帧,其余图像进行局部对齐,并通过核回归,估计每一帧对结果的局部贡献度;最后,分成RGB三种颜色通道,将贡献进行叠加。
在训练过程中,图像的局部特征会对核形状进行调整,并对采样值进行加权。
最后,对每个颜色通道进行归一化,获得最后的RGB图像。
整体来说,就是用多帧融合算法,代替了去马赛克的传统超分辨率算法。

然而,听起来非常完美的算法,有人在复现的过程中,却发现了一些问题。
实际复现并不容易
项目的作者表示,在复现这篇论文的过程中,发现了一些bug,但目前论文原作者、发行方都还没回应他。
再来看看这个算法:
首先,在图像帧的获取上,如果采用谷歌相机的单反模式进行拍摄,由于时间间隔较长,手部产生的“震颤”可能比想象得大,需要再通过全局的预对齐来弥补缺陷。
然后,主要的问题出在b、c两个步骤上。
第一个不准确的问题,是具体采用的帧数。论文表明“通过分析每个帧的局部梯度结构张量,来计算核的协方差矩阵”,然而作者发现,对每一帧都这样操作其实毫无意义。
作者放弃了像论文所述那样进行采样,选择了5×5而非3×3的核,并对梯度进行了高斯平滑,在全分辨率下计算每个像素的结构张量。
此外,则是步骤d的情况,经过长时间曝光的图像,包含许多低频噪声,使得精确跟踪无法实现。因此,作者在跟踪步骤前面还加入了一个高通滤波器。
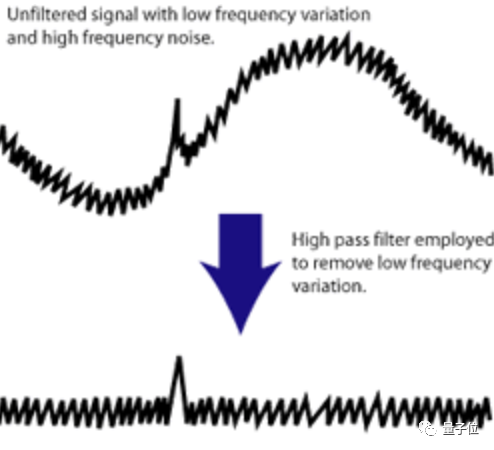
然而,论文却完全没有提到“高通滤波器”这种东西。
到了步骤e和f,谷歌论文的作者用了一个专业术语“Wiener shrinkage” ,但这个术语在引用论文中完全没有出现,无法得知具体含义。
因此,复现的作者,只能根据自己的猜测,结合引用的论文来复现。
其他还有一些细节上的错误,例如把公式搞错了的情况也有发生:

好在,最后他还是将这篇论文复现了出来:
而且做成了一个完整的项目,来看看具体效果。
具体效果
先来看看论文中所展示的效果,看上去还是非常不错的:

不仅噪点去除了不少,边缘也很平滑,没有放大后物体轮廓凸显的棱角。
而且,看起来也比其他的论文算法要更好:

那么,实际上复现出来的效果如何呢?

整体好像不太看得出效果,放大一点试试:

单栋大楼的窗子确实清晰了不少,原本是模糊一片,现在几乎能数得出数量了。
不过,相比于论文中的效果,复现出来的实际结果,似乎并没有那么“完美”。
但用来拍摄风景,效果还挺好:

拍照如果手抖的话,可以将它装到手机里试一试了~
项目地址:
https://github.com/kunzmi/ImageStackAlignator
论文地址:
https://dl.acm.org/doi/10.1145/3306346.3323024
推荐阅读
