
分库分表中间件常见方案对比分析
点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
1.为什么需要分库分库分表?
1.1 数据库性能瓶颈的出现
最直观的表现就是对数据库的各种操作变慢,在高并发的场景下出现应用无法获取数据库连接,
1.2 数据库优化方案对比
1.2.1 SQL 与索引
在程序中对 SQL 语句进行优化,在数据库中添加索引。
这个是我们这边最常用的手段,也是成本低,效果明显的手段,但是过多的索引也会带来一些问题,不可盲目添加。个人理解是需要建立收益大的索引,建立最优的索引,一个索引可以对多个sql起作用,同时命中后对有效的减小数据集,所以建立索引也是一个值得探讨问题。
1.2.2 引擎和配置层面优化
选用特定的存储引擎,或者对表进行分区,对表结构进行拆分或者冗余处理,
或者对表结构比如字段的定义进行优化。
数据库配置的优化,比如连接数,缓冲区大小等等,优化配置的目的都是为了更高效地利用硬件。
1.2.3 操作系统与硬件
操作系统和硬件的优化,增加cpu,增加内存。
是否需要提升硬件,需要视情况而定,主要看导致数据库慢的原因是什么,盲目的叠加配置是不可取的。
1.2.4 数据库架构优化
读写分离
数据分片
当前面三种的收益不大时候,我们就要开始考虑在架构层面进行优化了,而架构层面最为有效的方法
就是进行分库分表,我的理解是,使用分库分表使用的恰当获得的收益十分显著
2 .分库分表的类型和特点
2.1分库分表的类型
垂直切分:基于表或字段划分,表结构不同。我们有单库的分表,也有多库的分库。
水平切分:基于数据划分,表结构相同,数据不同,也有同库的水平切分和多库的 切分
垂直拆分:
单库垂直分表 : 将一张表中的数据差分的得更加的细粒度,如:将用户信息表,拆分成基本信息表,联系方式表等
多库垂直分表:多库垂直分表就是把原来存储在一个库的不同的表,拆分到不同的数据库。个人理解微服务划分数据库的思想和这个类似,按照业务分到不同的数据库
垂直拆分还是由于业务量大的业务导致数据库数据量大,没有从根本上解决问题
水平拆分:
单库水平分表 :将一张表按照字段值的来划分到不同的表中
多库水平分表:将一张表按照字段值的来划分到不同的库中,例如:按照租户分库
2.2分库分表的带来的问题
分完库分完表之后,之前在单库的的不会存在的问题都暴露出来了:
跨库关联查询:
如何解决跨数据关联查询的问题
(1)字段冗余:将需要跨库查询查询的字段进行冗余处理
(2)数据同步:采用etl方式将需要关联的查询的数据进行同步
(3)广播表:将一些多个数据库都需要用到表在操作的时候进行广播,例如表单表
(4)绑定表:将相同分片值相同的数据
(5)系统层面封装:在不同的数据库节点把符合条件数据的数据查询出来,然后重新组装,返回给客户端。
分布式事务
如果在一个数 据库里面,我们可以用本地事务来控制,但是在不同的数据库里面就不行了。所以分布式环境里面的事务,我们也需要通过一些方案来解决.
全局事务
基于可靠消息服务的分布式事务
柔性事务 TCC
最大努力通知,通过消息中间件向其他系统发送消息
排序、翻页、函数等计算问题
max、min、sum、count 之类的函数在进行计算的时候,也需要先在每个分片上执行相应的函数,然后将各个分片的结果集进行汇总和再次计算,最终将结果返回
全局主键避重问题
使用主键自增策略,在不同的数据库会出现主键冲突问题,该如何解决:
UUID
Snowflake
使用redis来做自增策略
现在的一些开源产品来解决分库分表带来的问题,也大多采用以上一些解决方案
3.分库分表的方案设计与对比
思考一个sql执行的流程: DAO——Mapper(ORM)——JDBC——代理——数据库服务
当前市面的解决方案基本都是从这个流程入手,下面我们将一一为其做探讨:
3.1 DAO层
在这一层主要是做数据源的路由,一般也是多数据路由的选择方案,Spring 中提供了一个抽象类
AbstractRoutingDataSource,可以实现数据源的动态切换.
这种实现方案目前在我们这边也是有应用的,在shc中的patient-document中对多数据源的路由就采取了这种方式
优点: 不需要依赖 ORM 框架,即使替换了 ORM 框架也不受影响。实现简单(不需要解析 SQL 和路由规则),可以灵活地定制。
缺点:不能复用,不能跨语言,对于以上出现的问题都需要自己手动来进行处理
3.2 ORM 框架层
如我们用 MyBatis 连接数据库,也可以指定数据源。我们可以基于 MyBatis 插件的拦截机制(拦截 query 和 update 方法),实现数据源的选择.
缺点: 很明显同上
3.3 驱动层
不管是MyBatis 还是Hibernate,还是Spring 的JdbcTemplate,本质上都是对JDBC的封装,所以第三层就是驱动层。比如 Sharding-JDBC,就是对 JDBC 的对象进行了封装。
JDBC 的核心对象:
DataSource:数据源
Connection:数据库连接
Statement:语句对象
ResultSet:结果集
只要对这几个对象进行封装或者拦截或者代理,就可以实现分片的操作.
缺点:
1.仅支持JAVA
2.占用较多的数据库连接
3.数据聚合在业务实例执行
4.版本升级较为麻烦
优点: 相对灵活,性能高,支持丰富的DB
例如:TDDL、ShardingJDBC
3.4代理层
前面三种都是在客户端实现的,也就是说不同的项目都要做同样的改动,不同的编程语言也有不同的实现,代理层。代理层的数据库中间件,将自己伪装成一个数据库,接受业务端的链接。然后负载业务端的请求,解析或者转发到真正的数据库中,其实是基于协议层面的,可以看后续的对比。
缺点:
异构支持,DB支持有限
运维负担大,需要高可用,单独部署,稳定性高,配置后需要重启
优点: 无代码入侵
比如 Mycat ,Sharding-Proxy和一些云厂商的分布式数据库都是属于这一层。
3.5 数据库层面
最后一层就是在数据库服务上实现,也就是服务层,某些特定的数据库或者数据库的特定版本可以实现这个功能。
缺点: 受限于使用数据库的类型
例如很多非关系型数据库, redis,mongodb等
3.6方案对比
目前主流的分库分表方案就是sharding-jdbc和mycat,为此做了一个对比
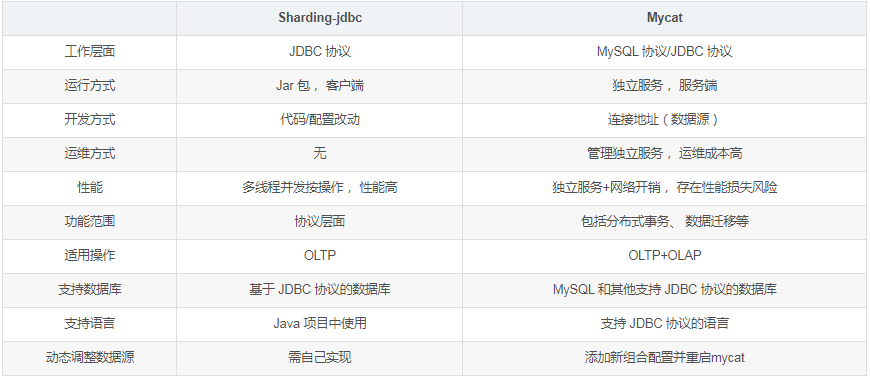
由于我们这边需要采用动态的配置,以及更加个性化的实现,所以选择sharding-jdbc
————————————————
版权声明:本文为CSDN博主「永恒1996」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:
https://blog.csdn.net/weixin_38437520/article/details/106610213
锋哥最新SpringCloud分布式电商秒杀课程发布
👇👇👇
👆长按上方微信二维码 2 秒
感谢点赞支持下哈 