
揭晓飞桨平台提速秘诀:INT8量化加速实现“事半功倍”
视学算法
共 7183字,需浏览 15分钟
·
2021-09-18 02:28
在图像分类等深度学习应用中,使用 INT8 替代 FP32 来提升推理效率、降低功耗和部署复杂度,是目前 AI 技术发展的重要方向。飞桨基于第二代英特尔® 至强® 可扩展处理器的高性能算力以及英特尔® 深度学习加速( VNNI 指令集)的技术,对应的 INT8 方案在不影响推理准确度的情况下,推理速度实现显著的提升。 -- 高铁柱 高级经理 百度深度学习平台部

百度飞桨开源深度学习平台实现的解决方案优势:
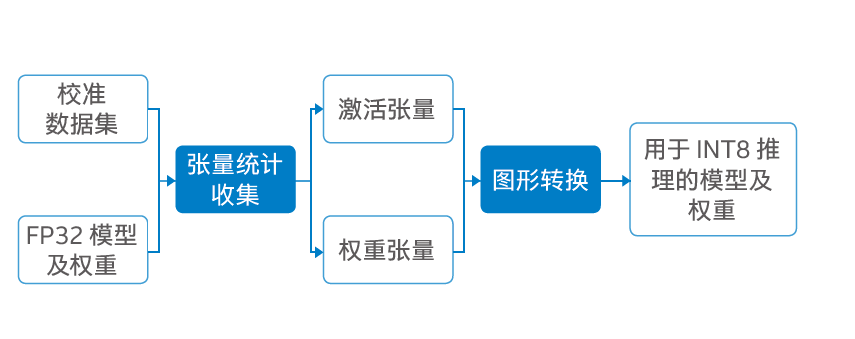
• 在图像分类等场景所用的深度学习模型中,采用 INT8 等低精度定点计算方式,可以更高效地利用高速缓存,减少带宽瓶颈,并更大限度地利用计算资源,降低功率消耗;
• 在 ResNet-50* 和 MobileNet-V1* 等多个深度学习模型上的实践表明,基于第二代英特尔® 至强® 可扩展处理器,特别是它所集成的英特尔® 深度学习技术的支持,INT8可以实现与 FP32 相近的深度学习模型推理准确度,两者差值在 1% 以内2;
• 在这些深度学习模型上的实践,同时还表明,基于第二代英特尔® 至强® 可扩展处理器及英特尔®深度学习技术的支持,INT8 可实现更快的深度学习模型推理速度,其推理速度约为 FP32 的 2.2 倍~2.79倍3。







分享

点收藏

点点赞

点在看
评论