
GitHub 编程神器 Copilot被斥「盗版」大量开源代码,面临90亿美元集...
 大数据文摘作品
作者:Mickey
大数据文摘作品
作者:Mickey
自诞生之日起就饱受争议的微软代码工具Copilot近期又遭遇了新的问题。 一名程序员就该工具正式起诉了微软、GitHub 和 OpenAI,寻求对微软和其他设计部署 Copilot 的公司进行集体诉讼,并要求赔偿。目前诉讼已经提交到了美国加州北区地方法院,要求批准 9,000,000,000 美元的法定赔偿金。
让程序员们早下班的AI工具
Copilot到底何方神器? 今年6 月下旬,微软发布了一种可以自动生成计算机代码的新型人工智能技术。 该工具名为 Copilot,旨在让专业程序员更快地工作。当他们工作时,Copilot会给出代码建议,程序员可以直接将copilot展示的建议的代码块直接添加到自己的代码中,快速完成工作,这一工具也因此被很多媒体誉为“让程序员早下班的工具”。
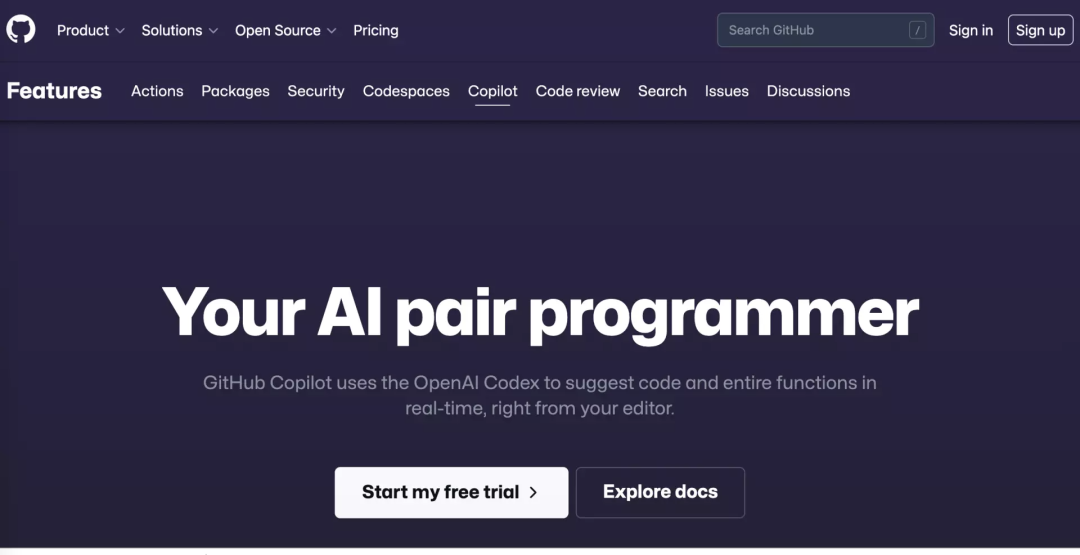 据 Copilot 网站称,Copilot基于Codex 模型产生,其由“互联网上的公共代码和文本”训练,“既能理解编程,也能理解人类语言”。作为 Visual Studio Code 的扩展,Copilot “将你的评论和代码发送到 GitHub Copilot 服务,然后它会使用 OpenAI Codex 来合成并建议个别行和整个函数”。
许多程序员喜欢这个新工具,有开发者表示: “使用 Copilot,我能尽量少把精力浪费在枯燥重复的工作身上。它点燃的灵感火花,让我感到编码过程更有趣、更高效了。”但也有不少人不买账,洛杉矶的程序员、设计师、作家和律师Matthew Butterick就是其中之一。本月,他和其他律师团队提起诉讼,寻求对微软和其他设计和部署 Copilot 的知名公司的集体诉讼地位。
据 Copilot 网站称,Copilot基于Codex 模型产生,其由“互联网上的公共代码和文本”训练,“既能理解编程,也能理解人类语言”。作为 Visual Studio Code 的扩展,Copilot “将你的评论和代码发送到 GitHub Copilot 服务,然后它会使用 OpenAI Codex 来合成并建议个别行和整个函数”。
许多程序员喜欢这个新工具,有开发者表示: “使用 Copilot,我能尽量少把精力浪费在枯燥重复的工作身上。它点燃的灵感火花,让我感到编码过程更有趣、更高效了。”但也有不少人不买账,洛杉矶的程序员、设计师、作家和律师Matthew Butterick就是其中之一。本月,他和其他律师团队提起诉讼,寻求对微软和其他设计和部署 Copilot 的知名公司的集体诉讼地位。
前程序员律师发起集体诉讼: 与盗版无异
与许多尖端人工智能技术一样,Copilot 通过分析大量数据来发展其技能 。在这种情况下,它依赖于 发布到互联网上的数十亿行计算机代码 。52 岁的 Butterick认为此过程等同于盗版,因为该系统不会展示任何版权来源。他的诉讼声称微软及其合作者侵犯了数百万、花费数年时间敲下原始代码的程序员的合法权利。 这起诉讼被认为是对称为“AI训练”类技术的首次法律诉讼。通过大量公开数据进行训练,让ai学习并生成自己的产物,这是一种 构建人工智能 的方式,有望重塑科技行业。这些所谓产物包括画作、文字、和代码。近年来,许多艺术家、作家、专家和隐私活动家抱怨说,公司正在使用不属于他们的数据来训练他们的人工智能系统。
 程序员兼律师马修·巴特里克 (Matthew Butterick) 表示,他担心自己所做的工作在新的人工智能系统中被不当使用。
在过去几十年的技术发展中,这一诉讼并不是首例。在 1990 年代和 2000 年代,微软与开源软件的兴起作斗争,将其视为对公司业务未来的生存威胁。随着开源的重要性与日俱增,微软欣然接受它,后来还收购了开源程序员的家园——GitHub。
几乎每一代新技术,甚至是在线搜索引擎,都面临着类似的法律挑战。通常,“没有任何成文法或判例法对其有效,”专门研究这一法律领域的知识产权律师Bradley J. Hulbert说。
这起诉讼是人工智能发展途中的重要里程碑。艺术家、作家、作曲家和其他创意类型越来越担心公司和研究人员在未经他们同意且不提供报酬的情况下使用他们的作品来创造新技术。公司以这种方式训练各种各样的系统,包括
艺术生成器、
Siri 和 Alexa 等语音识别系统,甚至无人驾驶汽车。
Copilot 基于由 OpenAI 构建的技术,在微软和 GitHub 发布 Copilot 后,GitHub 的首席执行官 Nat Friedman 在
推特
上表示,根据版权法,使用现有代码来训练系统是对材料的“合理使用”,构建这些系统的公司和研究人员经常使用这一论点。但目前还没有法庭案件检验过这一论点。
“微软和 OpenAI 的野心远远超出了 GitHub 和 Copilot,”Butterick在接受采访时说。“他们想在任何地方免费训练任何数据,无需同意,永远。”
程序员兼律师马修·巴特里克 (Matthew Butterick) 表示,他担心自己所做的工作在新的人工智能系统中被不当使用。
在过去几十年的技术发展中,这一诉讼并不是首例。在 1990 年代和 2000 年代,微软与开源软件的兴起作斗争,将其视为对公司业务未来的生存威胁。随着开源的重要性与日俱增,微软欣然接受它,后来还收购了开源程序员的家园——GitHub。
几乎每一代新技术,甚至是在线搜索引擎,都面临着类似的法律挑战。通常,“没有任何成文法或判例法对其有效,”专门研究这一法律领域的知识产权律师Bradley J. Hulbert说。
这起诉讼是人工智能发展途中的重要里程碑。艺术家、作家、作曲家和其他创意类型越来越担心公司和研究人员在未经他们同意且不提供报酬的情况下使用他们的作品来创造新技术。公司以这种方式训练各种各样的系统,包括
艺术生成器、
Siri 和 Alexa 等语音识别系统,甚至无人驾驶汽车。
Copilot 基于由 OpenAI 构建的技术,在微软和 GitHub 发布 Copilot 后,GitHub 的首席执行官 Nat Friedman 在
推特
上表示,根据版权法,使用现有代码来训练系统是对材料的“合理使用”,构建这些系统的公司和研究人员经常使用这一论点。但目前还没有法庭案件检验过这一论点。
“微软和 OpenAI 的野心远远超出了 GitHub 和 Copilot,”Butterick在接受采访时说。“他们想在任何地方免费训练任何数据,无需同意,永远。”
从GPT-3到Copilot,AI用开源数据训练是否合法?
2020 年,OpenAI 推出了一个名为 GPT-3 的系统 。研究人员使用大量数字文本对系统进行训练,其中包括数千本书籍、维基百科文章、聊天记录和其他发布到互联网上的数据。 通过精确定位所有文本中的模式,该系统学会了预测序列中的下一个单词。当有人在这个“大型语言模型”中输入几个单词时,它可以用整段文本来完成这个想法。通过这种方式,系统可以编写自己的 Twitter 帖子、演讲、诗歌和新闻文章。 令构建该系统的研究人员大吃一惊的是,它甚至可以编写计算机程序,显然是从互联网上发布的无数程序中学到的。 因此,OpenAI 更进一步,在专门存储代码的新数据集合上训练新系统 Codex 。 该实验室后来在一份详细介绍该技术的研究论文 中表示,至少部分代码来自 GitHub。 这个新系统成为 Copilot 的底层技术,微软通过 GitHub 分发给程序员。在与相对较少的程序员进行了大约一年的测试后,Copilot 于 7 月在 GitHub 上向所有程序员推出。 目前,Copilot 生成的代码很简单,可能对更大的项目有用,但必须进行修改、扩充和审查,许多使用过该技术的程序员表示。有些程序员发现它只有在学习编码或试图掌握一门新语言时才有用。
 尽管如此,Butterick还是担心 Copilot 最终会摧毁全球程序员社区。系统发布几天后,他发表了一篇博文,标题为:“
这个Copilot很蠢,它想杀了我
”。
Butterick 先生自称为开源程序员,是与世界公开分享代码的程序员社区的一员。在过去的 30 年里,开源软件帮助推动了消费者每天使用的大多数技术的兴起,包括网络浏览器、智能手机和移动应用程序。
尽管开源软件旨在在编码人员和公司之间自由共享,但这种共享受许可证约束,旨在确保它的使用方式使更广泛的程序员社区受益。Butterick 先生认为,Copilot 违反了这些许可证,并且随着它的不断改进,将使开源编码器变得过时。
在公开吐槽这个问题几个月后,他向其他几位律师提起诉讼。该诉讼仍处于早期阶段,尚未被法院授予集体诉讼地位。
令许多法律专家感到意外的是,Butterick的诉讼并未指控微软、GitHub 和 OpenAI 侵犯版权。他的诉讼采取了不同的策略,认为这些公司违反了 GitHub 的服务条款和隐私政策,同时也违反了要求公司在使用材料时
显示版权信息的联邦法律。
Butterick和诉讼背后的另一位律师乔·萨维里 (Joe Saveri) 表示,诉讼最终可能会解决版权问题。
当被问及公司是否可以讨论这起诉讼时,GitHub 发言人拒绝了采访,然后在一封电子邮件声明中表示,该公司“从一开始就致力于通过 Copilot 进行负责任的创新,并将继续改进产品,为全球开发人员提供最好的服务” 微软和 OpenAI 拒绝就诉讼发表评论。
大多数专家认为,根据现行法律,在受版权保护的材料上训练人工智能系统不一定违法。但这样做可能是因为系统最终创建的材料与它所训练的数据基本相似。
Copilot 的一些用户
表示
,它生成的代码似乎与现有程序相同(或几乎相同),这一观察结果可能成为 Butterick 先生和其他人案例的核心部分。
加州大学伯克利分校教授帕姆·萨缪尔森专门研究知识产权及其在现代技术中的作用,他说法律思想家和监管机构在技术出现之前的 80 年代简要探讨了这些法律问题。她说,现在需要进行法律评估。
“这不再是玩具问题,”萨缪尔森博士说。
Butterick还创建了一个网站,跟进诉讼情况,也呼吁更多人的支持,在网站文章中他强调:“我们反对的绝不是 AI 辅助编程工具,而是微软在 Copilot 当中的种种具体行径。微软完全可以把 Copilot 做得更开发者友好——比如邀请大家自愿参加,或者由编程人员有偿对训练语料库做出贡献。但截至目前,口口声声自称热爱开源的微软根本没做过这方面的尝试。另外,如果大家觉得 Copilot 效果挺好,那主要也是因为底层开源训练数据的质量过硬。Copilot 其实是在从开源项目那边吞噬能量,而一旦开源活力枯竭,Copilot 也将失去发展的依凭。”
相关素材:
https://archive.ph/3tuU0
https://githubcopilotinvestigation.com/
尽管如此,Butterick还是担心 Copilot 最终会摧毁全球程序员社区。系统发布几天后,他发表了一篇博文,标题为:“
这个Copilot很蠢,它想杀了我
”。
Butterick 先生自称为开源程序员,是与世界公开分享代码的程序员社区的一员。在过去的 30 年里,开源软件帮助推动了消费者每天使用的大多数技术的兴起,包括网络浏览器、智能手机和移动应用程序。
尽管开源软件旨在在编码人员和公司之间自由共享,但这种共享受许可证约束,旨在确保它的使用方式使更广泛的程序员社区受益。Butterick 先生认为,Copilot 违反了这些许可证,并且随着它的不断改进,将使开源编码器变得过时。
在公开吐槽这个问题几个月后,他向其他几位律师提起诉讼。该诉讼仍处于早期阶段,尚未被法院授予集体诉讼地位。
令许多法律专家感到意外的是,Butterick的诉讼并未指控微软、GitHub 和 OpenAI 侵犯版权。他的诉讼采取了不同的策略,认为这些公司违反了 GitHub 的服务条款和隐私政策,同时也违反了要求公司在使用材料时
显示版权信息的联邦法律。
Butterick和诉讼背后的另一位律师乔·萨维里 (Joe Saveri) 表示,诉讼最终可能会解决版权问题。
当被问及公司是否可以讨论这起诉讼时,GitHub 发言人拒绝了采访,然后在一封电子邮件声明中表示,该公司“从一开始就致力于通过 Copilot 进行负责任的创新,并将继续改进产品,为全球开发人员提供最好的服务” 微软和 OpenAI 拒绝就诉讼发表评论。
大多数专家认为,根据现行法律,在受版权保护的材料上训练人工智能系统不一定违法。但这样做可能是因为系统最终创建的材料与它所训练的数据基本相似。
Copilot 的一些用户
表示
,它生成的代码似乎与现有程序相同(或几乎相同),这一观察结果可能成为 Butterick 先生和其他人案例的核心部分。
加州大学伯克利分校教授帕姆·萨缪尔森专门研究知识产权及其在现代技术中的作用,他说法律思想家和监管机构在技术出现之前的 80 年代简要探讨了这些法律问题。她说,现在需要进行法律评估。
“这不再是玩具问题,”萨缪尔森博士说。
Butterick还创建了一个网站,跟进诉讼情况,也呼吁更多人的支持,在网站文章中他强调:“我们反对的绝不是 AI 辅助编程工具,而是微软在 Copilot 当中的种种具体行径。微软完全可以把 Copilot 做得更开发者友好——比如邀请大家自愿参加,或者由编程人员有偿对训练语料库做出贡献。但截至目前,口口声声自称热爱开源的微软根本没做过这方面的尝试。另外,如果大家觉得 Copilot 效果挺好,那主要也是因为底层开源训练数据的质量过硬。Copilot 其实是在从开源项目那边吞噬能量,而一旦开源活力枯竭,Copilot 也将失去发展的依凭。”
相关素材:
https://archive.ph/3tuU0
https://githubcopilotinvestigation.com/
 点「在看」的人都变好看了哦!
点「在看」的人都变好看了哦!
评论