
【收藏!】一文看尽2020年度最出圈AI论文合集
共 9295字,需浏览 19分钟
·
2021-01-15 02:47
↑↑↑点击上方蓝字,回复资料,10个G的惊喜
本文为你总结2020年AI领域有很多精彩的重要成果。来源: 新智元


论文原文:
A. Bochkovskiy, C.-Y. Wang, and H.-Y. M. Liao, Yolov4: Optimal speed and accuracy of object detection, 2020. arXiv:2004.10934 [cs.CV].
代码地址:
https://github.com/AlexeyAB/darknet
2、DeepFace rawing:依据草图的人脸图像深度生成

论文原文:
S.-Y. Chen, W. Su, L. Gao, S. Xia, and H. Fu, “DeepFaceDrawing: Deep generation of face images from sketches,” ACM Transactions on Graphics (Proceedings of ACM SIGGRAPH2020), vol. 39, no. 4, 72:1–72:16, 2020.
代码地址:
https://github.com/IGLICT/DeepFaceDrawing-Jittor

论文原文:
S. Menon, A. Damian, S. Hu, N. Ravi, and C. Rudin, Pulse: Self-supervised photo upsampling via latent space exploration of generative models, 2020. arXiv:2003.03808 [cs.CV].
代码地址:
https://github.com/adamian98/pulse
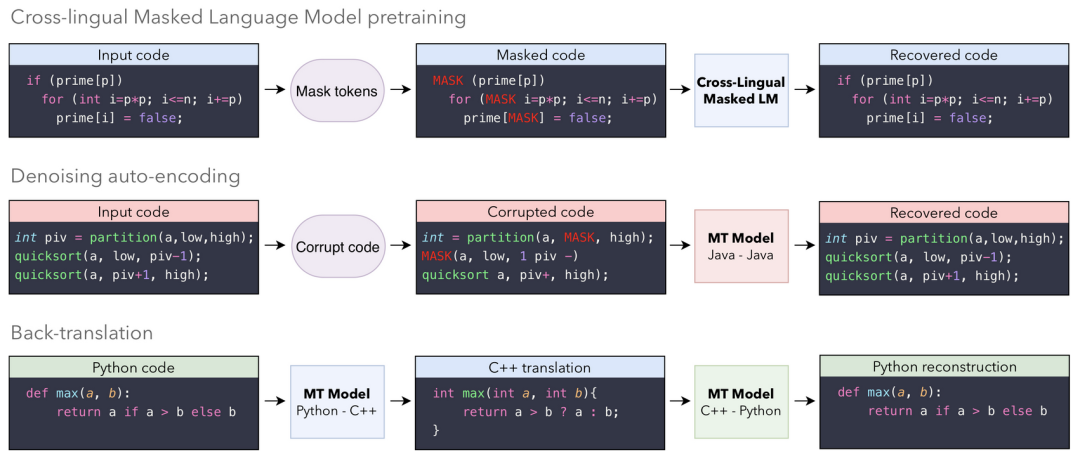
论文原文:
M.-A. Lachaux, B. Roziere, L. Chanussot, and G. Lample, Unsupervised translation of programming languages, 2020. arXiv:2006.03511 [cs.CL].
代码地址:
https://github.com/facebookresearch/TransCoder?utm_source=catalyzex.com

论文原文:
S. Saito, T. Simon, J. Saragih, and H. Joo, Pifuhd: Multi-level pixel-aligned implicit function for high-resolution 3d human digitization, 2020. arXiv:2004.00452 [cs.CV].
代码地址:
https://github.com/facebookresearch/pifuhd
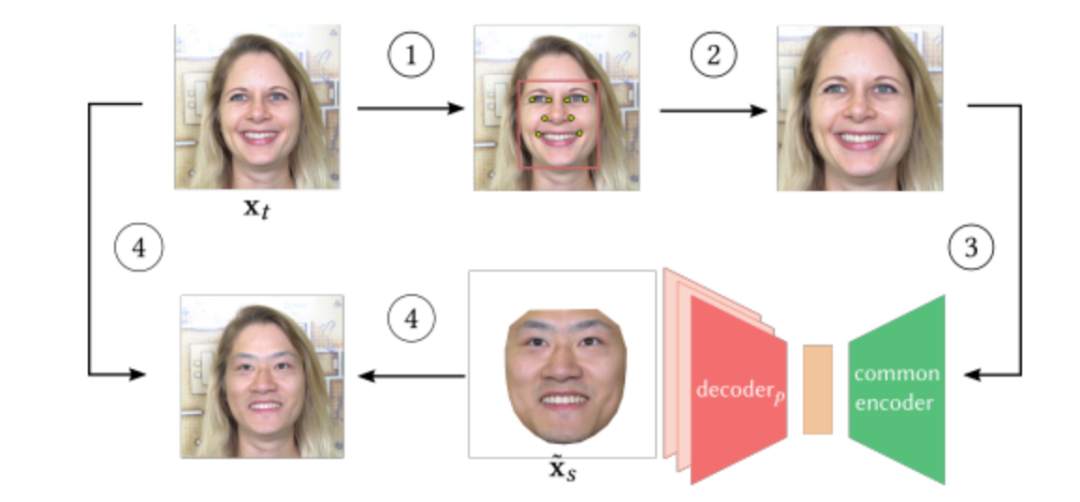
论文原文:
J. Naruniec, L. Helminger, C. Schroers, and R. Weber, “High-resolution neural face-swapping for visual effects,” Computer Graphics Forum, vol. 39, pp. 173–184, Jul. 2020.doi:10.1111/cgf.14062.
论文链接:
https://studios.disneyresearch.com/2020/06/29/high-resolution-neural-face-swapping-for-visual-effects/

论文原文:
T. Park, J.-Y. Zhu, O. Wang, J. Lu, E. Shechtman, A. A. Efros, and R. Zhang,Swappingautoencoder for deep image manipulation, 2020. arXiv:2007.00653 [cs.CV].
代码地址:
https://github.com/rosinality/swapping-autoencoder-pytorch?utm_source=catalyzex.com
8、GPT-3:实现小样本学习的语言模型

论文原文:
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P.Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S.Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei,“Language models are few-shot learners,” 2020. arXiv:2005.14165 [cs.CL].
代码地址:
https://github.com/openai/gpt-3
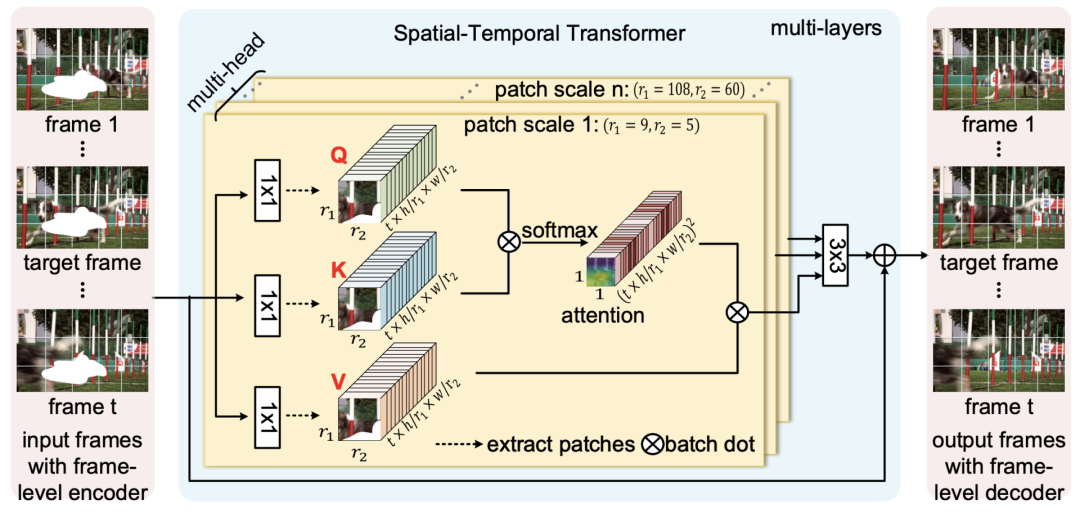
论文原文:
Y. Zeng, J. Fu, and H. Chao, Learning joint spatial-temporal transformations for video in-painting, 2020. arXiv:2007.10247 [cs.CV].
代码地址:
https://github.com/researchmm/STTN?utm_source=catalyzex.com
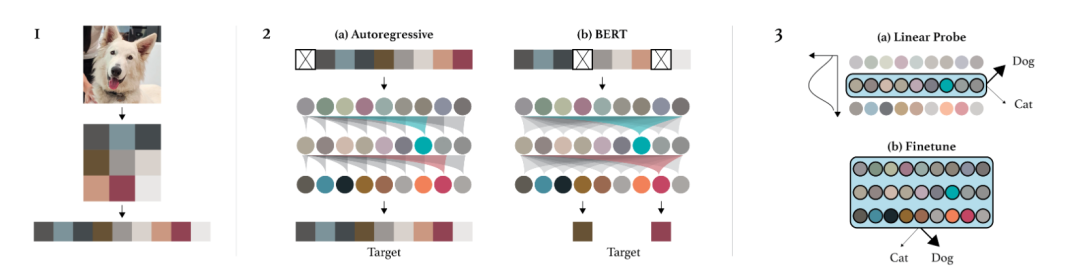
论文原文:
M. Chen, A. Radford, R. Child, J. Wu, H. Jun, D. Luan, and I. Sutskever, “Generative pretraining from pixels,” in Proceedings of the 37th International Conference on Machine Learning, H. D. III and A. Singh, Eds., ser. Proceedings of Machine Learning Research, vol. 119, Virtual: PMLR, 13–18 Jul 2020, pp. 1691–1703. [Online].
代码地址:
https://github.com/openai/image-gpt
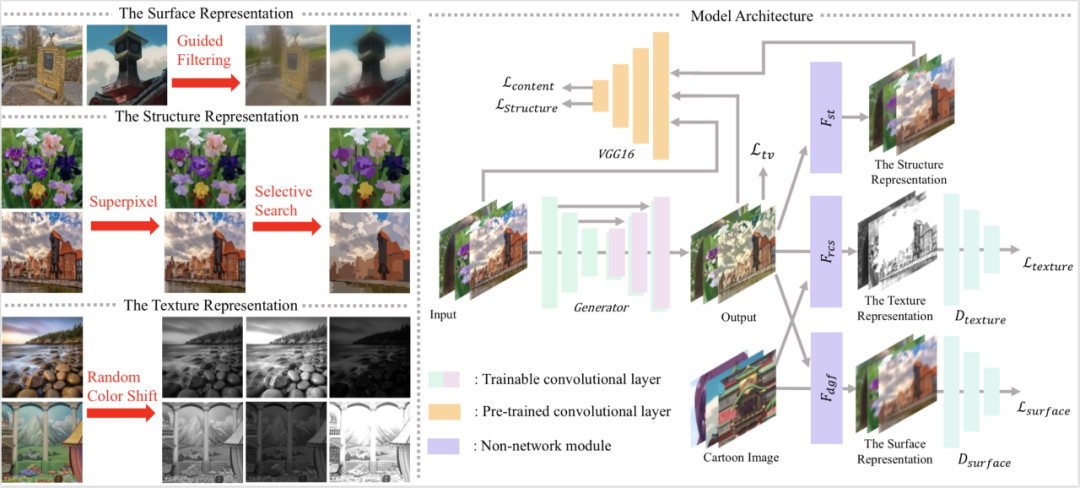
论文原文:
Xinrui Wang and Jinze Yu, “Learning to Cartoonize Using White-box Cartoon Representations.”, IEEE Conference on Computer Vision and Pattern Recognition, June 2020.
代码地址:
https://github.com/SystemErrorWang/White-box-Cartoonization

论文原文:
S. Mo, M. Cho, and J. Shin, Freeze the discriminator: A simple baseline for fine-tuning gans,2020. arXiv:2002.10964 [cs.CV].
代码地址:
https://github.com/sangwoomo/freezeD?utm_source=catalyzex.com
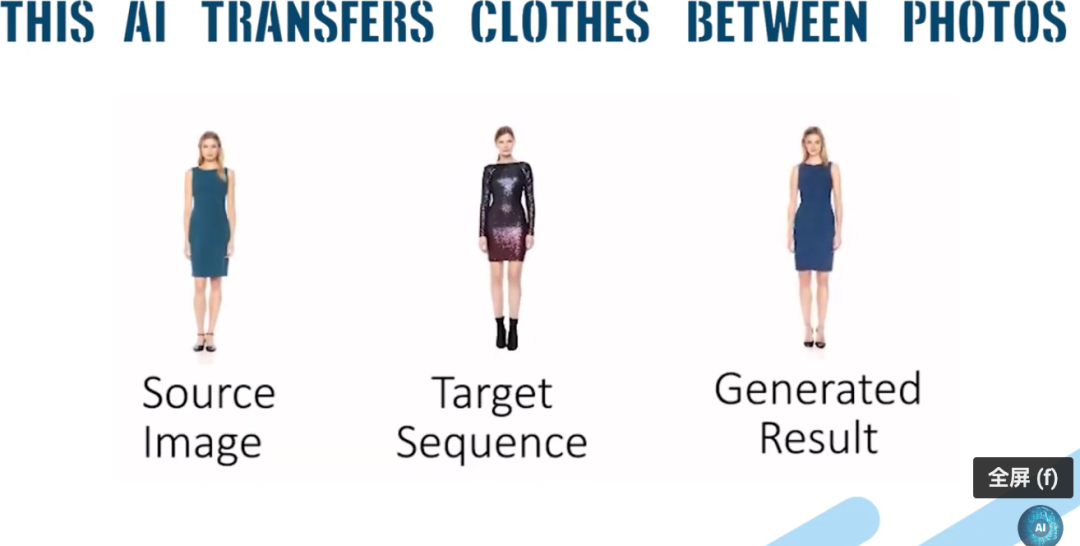
论文地址:
K. Sarkar, D. Mehta, W. Xu, V. Golyanik, and C. Theobalt, “Neural re-rendering of humans from a single image,” in European Conference on Computer Vision (ECCV), 2020.
项目主页:
http://gvv.mpi-inf.mpg.de/projects/NHRR/

论文原文:
G. Moon and K. M. Lee, “I2l-meshnet: Image-to-lixel prediction network for accurate 3d human pose and mesh estimation from a single rgb image,” in European Conference on ComputerVision (ECCV), 2020
代码地址:
https://github.com/mks0601/I2L-MeshNet_RELEASE

代码地址:
https://github.com/jacobkrantz/VLN-CE
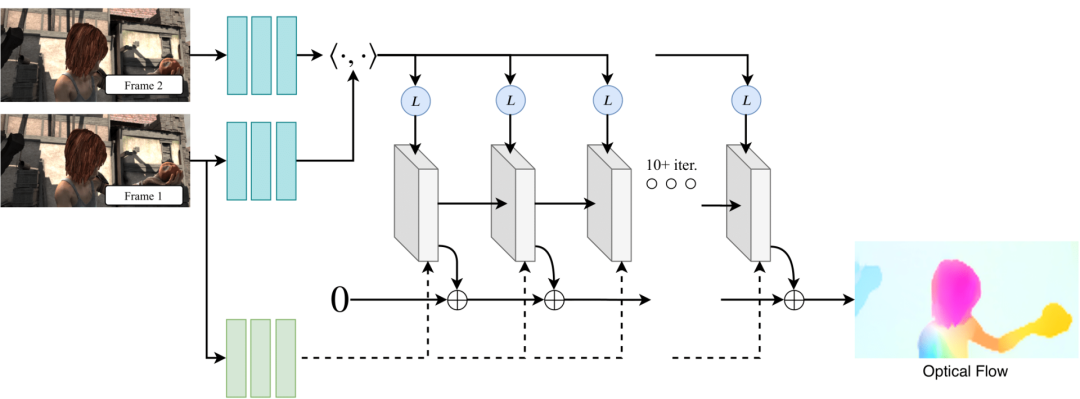
代码地址:
https://github.com/princeton-vl/RAFT

论文原文:
Z. Li, W. Xian, A. Davis, and N. Snavely, “Crowdsampling the plenoptic function,” inProc.European Conference on Computer Vision (ECCV), 2020.
代码地址:
https://github.com/zhengqili/Crowdsampling-the-Plenoptic-Function

论文原文:
Z. Wan, B. Zhang, D. Chen, P. Zhang, D. Chen, J. Liao, and F. Wen, Old photo restoration via deep latent space translation, 2020. arXiv:2009.07047 [cs.CV].
代码地址:
https://github.com/microsoft/Bringing-Old-Photos-Back-to-Life?utm_source=catalyzex.com
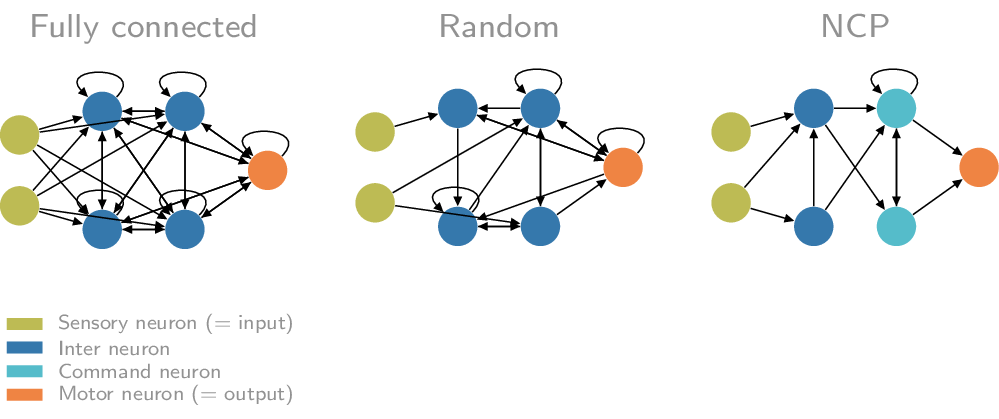
论文原文:
Lechner, M., Hasani, R., Amini, A. et al. Neural circuit policies enabling auditable autonomy. Nat Mach Intell2, 642–652 (2020).
论文地址:
https://doi.org/10.1038/s42256-020-00237-3

论文原文:
R. Or-El, S. Sengupta, O. Fried, E. Shechtman, and I. Kemelmacher-Shlizerman, “Lifespanage transformation synthesis,” in Proceedings of the European Conference on Computer Vision(ECCV), 2020.
代码地址:
https://github.com/royorel/Lifespan_Age_Transformation_Synthesis

代码地址:
https://github.com/jantic/DeOldify
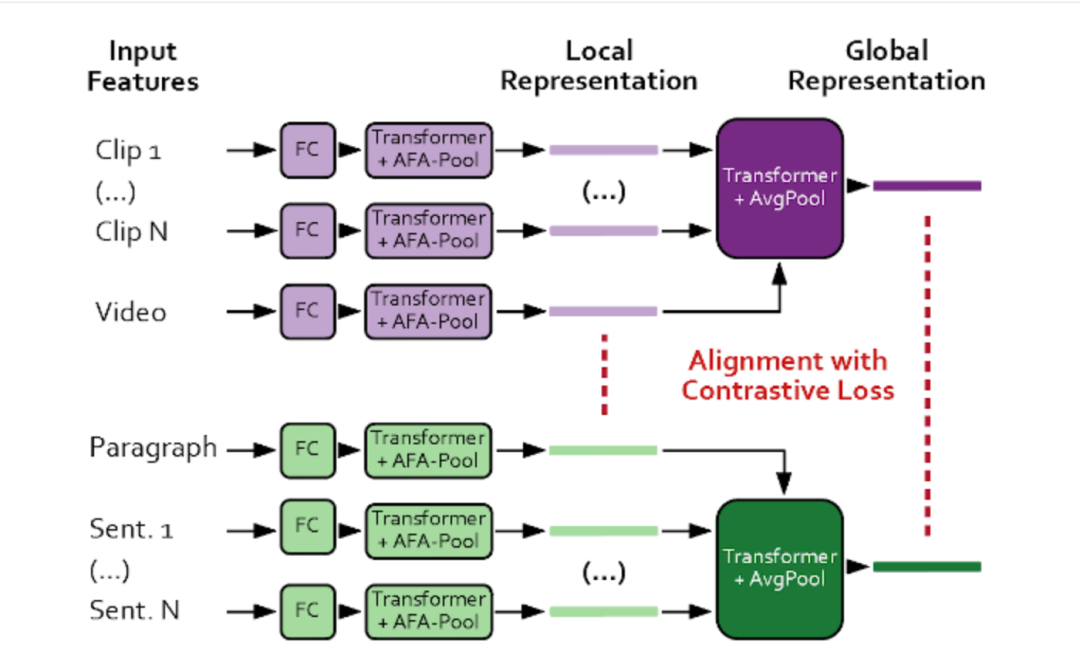
论文原文:
S. Ging, M. Zolfaghari, H. Pirsiavash, and T. Brox, “Coot: Cooperative hierarchical trans-former for video-text representation learning,” in Conference on Neural Information ProcessingSystems, 2020.
代码地址:
https://github.com/gingsi/coot-videotext
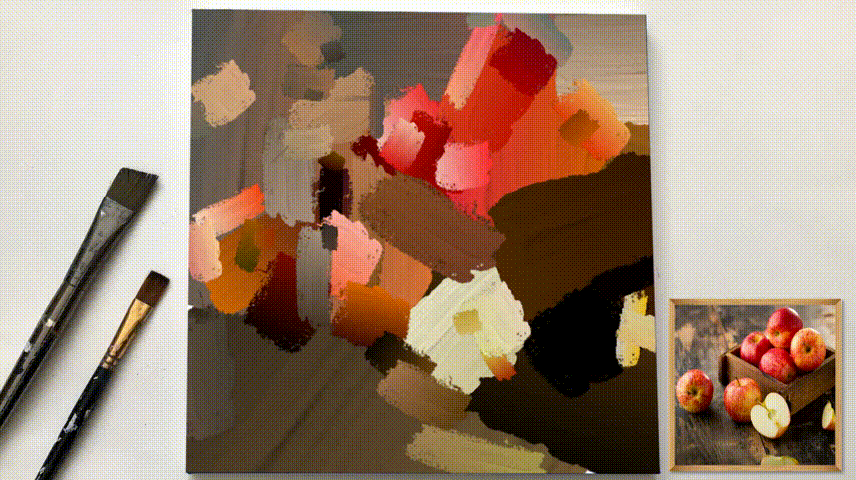
论文原文:
Z. Zou, T. Shi, S. Qiu, Y. Yuan, and Z. Shi, Stylized neural painting, 2020. arXiv:2011.08114[cs.CV]
代码地址:
https://github.com/jiupinjia/stylized-neural-painting

论文原文:
Z. Ke, K. Li, Y. Zhou, Q. Wu, X. Mao, Q. Yan, and R. W. Lau, “Is a green screen really necessary for real-time portrait matting?” ArXiv, vol. abs/2011.11961, 2020.
项目地址:
https://github.com/ZHKKKe/MODNet

论文原文:
T. Karras, M. Aittala, J. Hellsten, S. Laine, J. Lehtinen, and T. Aila, Training generative adversarial networks with limited data, 2020. arXiv:2006.06676 [cs.CV].
也可以加一下老胡的微信 围观朋友圈~~~
推荐阅读
