
这次排查接口超时原因,鬼知道我经历了什么
排查接口问题是程序员必备技能,加上生产环境错综复杂,定位一个问题可能更加困难,今天分享的是接口超时问题排查
Jdk 的 native 方法当然不是终点,虽然发现 Jdk、docker、操作系统 Bug 的可能性极小,但再往底层查却很可能发现一些常见的配置错误。
为了便于复现,我用 JMH 写了一个简单的 demo,控制速度不断地通过 log4j2 写入日志。将项目打包成 jar 包,就可以很方便地在各处运行了。
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
@State(Scope.Benchmark)
@Threads(5)
public class LoggerRunner {
public static void main(String[] args) throws RunnerException {
Options options = new OptionsBuilder()
.include(LoggerRunner.class.getName())
.warmupIterations(2)
.forks(1)
.measurementIterations(1000)
.build();
new Runner(options).run();
}
}
我比较怀疑是 docker 的原因。但是在 docker 内外运行了 jar 包却发现都能很简单地复现日志停顿问题。而 jdk 版本众多,我准备首先排查操作系统配置问题。
系统调用
strace 命令很早就使用过,不久前还用它分析过 shell 脚本执行慢的问题( 解决问题,别扩展问题),但我还是不太习惯把 Java 和它联系起来,幸好有部门的老司机指点,于是就使用 strace 分析了一波 Java 应用。
命令跟分析普通脚本一样, strace -T -ttt -f -o strace.log java -jar log.jar, -T 选项可以将每一个系统调用的耗时打印到系统调用的结尾。当然排查时使用 -p pid 附加到 tomcat 上也是可以的,虽然会有很多容易混淆的系统调用。
对比 jmh 压测用例输出的 log4j2.info() 方法耗时,发现了下图中的状况。

一次 write 系统调用竟然消耗了 147ms,很明显地,问题出在 write 系统调用上。
文件系统
结构
这时候就要好好回想一下操作系统的知识了。
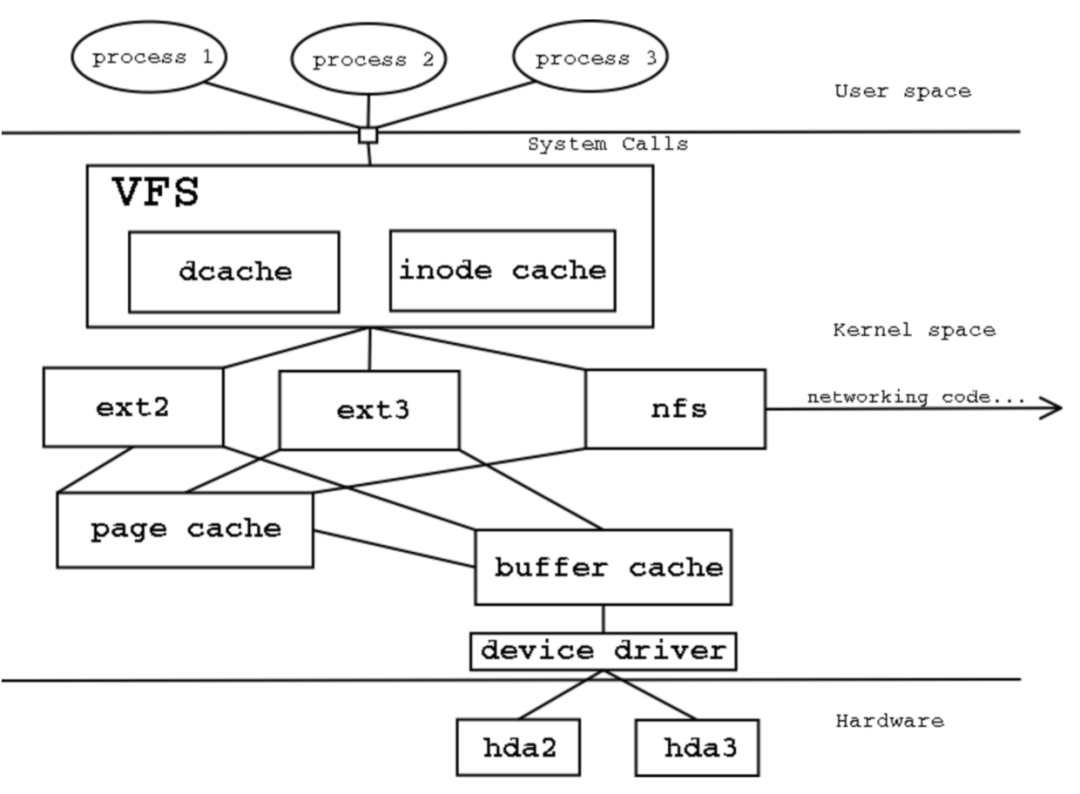
在 linux 系统中,万物皆文件,而为了给不同的介质提供一种抽象的接口,在应用层和系统层之间,抽象了一个虚拟文件系统层(virtual file system, VFS)。上层的应用程序通过 系统调用 system call 操作虚拟文件系统,进而反馈到下层的硬件层。
由于硬盘等介质操作速度与内存不在同一个数量级上,为了平衡两者之间的速度,linux 便把文件映射到内存中,将硬盘单位块(block)对应到内存中的一个 页(page)上。这样,当需要操作文件时,直接操作内存就可以了。当缓冲区操作达到一定量或到达一定的时间后,再将变更统一刷到磁盘上。这样便有效地减少了磁盘操作,应用也不必等待硬盘操作结束,响应速度得到了提升。
而 write 系统调用会将数据写到内存中的 page cache,将 page 标记为 脏页(dirty) 后返回。
linux 的 writeback 机制
对于将内存缓冲区的内容刷到磁盘上,则有两种方式:
首先,应用程序在调用 write 系统调用写入数据时,如果发现 page cache 的使用量大于了设定的大小,便会主动将内存中的脏页刷到硬盘上。在此期间,所有的 write 系统调用都会被阻塞。
系统当然不会容忍不定时的 write 阻塞,linux 还会定时启动 pdflush 线程,判断内存页达到一定的比例或脏页存活时间达到设定的时间,将这些脏页刷回到磁盘上,以避免被动刷缓冲区,这种机制就是 linux 的 writeback 机制。
猜测
了解了以上基础知识,那么对于 write 系统调用为什么会被阻塞,提出了两种可能:
page cache 可用空间不足,导致触发了主动的 flush,此时会阻塞所有对此 device 的 write。 写入过程被其他事务阻塞。
首先对于第一种可能:查看系统配置 dirty_ratio 的大小:20。此值是 page cache 占用系统可用内存(real mem + swap)的最大百分比, 我们的内存为 32G,没有启用 swap,则实际可用的 page cache 大小约为 6G。
另外,与 pdflush 相关的系统配置:系统会每 vm.dirty_writeback_centisecs (5s) 唤醒一次 pdflush 线程, 发现脏页比例超过 vm.dirty_background_ratio (10%) 或 脏页存活时间超过 vm.dirty_expire_centisecs(30s) 时,会将脏页刷回硬盘。
查看 /proc/meminfo 内 Dirty/Writeback 项的变化,并对比服务的文件写入速度,结论是数据会被 pdflush 刷回到硬盘,不会触发被动 flush 以阻塞 write 系统调用。
ext4 的 journal 特性
write 被阻塞的原因
继续搜索资料,在一篇文章(Why buffered writes are sometimes stalled )中看到 write 系统调用被阻塞有以下可能:
要写入的数据依赖读取的结果时。但记录日志不依赖读文件; wirte page 时有别的线程在调用 fsync() 等主动 flush 脏页的方法。但由于锁的存在,log 在写入时不会有其他的线程操作; 格式为 ext3/4 的文件系统在记录 journal log 时会阻塞 write。而我们的系统文件格式为 ext4。维基百科上的一个条目( https://en.wikipedia.org/wiki/Journaling_block_device ) 也描述了这种可能。
journal
journal 是 文件系统保证数据一致性的一种手段,在写入数据前,将即将进行的各个操作步骤记录下来,一旦系统掉电,恢复时读取这些日志继续操作就可以了。但批量的 journal commit 是一个事务,flush 时会阻塞 write 的提交。
我们可以使用 dumpe2fs /dev/disk | grep features 查看磁盘支持的特性,其中有 has_journal 代表文件系统支持 journal 特性。
ext4 格式的文件系统在挂载时可以选择 (jouranling、ordered、writeback) 三种之一的 journal 记录模式。
三种模式分别有以下特性:
journal:在将数据写入文件系统前,必须等待 metadata 和 journal 已经落盘了。 ordered:不记录数据的 journal,只记录 metadata 的 journal 日志,且需要保证所有数据在其 metadata journal 被 commit 之前落盘。ext4 在不添加挂载参数时使用此模式。 writeback: 数据可能在 metadata journal 被提交之后落盘,可能导致旧数据在系统掉电后恢复到磁盘中。
当然,我们也可以选择直接禁用 journal,使用 tune2fs -O ^has_journal /dev/disk,只能操作未被挂载的磁盘。
猜测因为 journal 触发了脏页落盘,而脏页落盘导致 write 被阻塞,所以解决 journal 问题就可以解决接口超时问题。
解决方案与压测结果
以下是我总结的几个接口超时问题的解决方案:
log4j2 日志模式改异步。但有可能会在系统重启时丢失日志,另外在异步队列 ringbuffer 被填满未消费后,新日志会自动使用同步模式。 调整系统刷脏页的配置,将检查脏页和脏页过期时间设置得更短(1s 以内)。但理论上会略微提升系统负载(未明显观察到)。 挂载硬盘时使用 data=writeback 选项修改 journal 模式。但可能导致系统重启后文件包含已删除的内容。 禁用 ext4 的 journal 特性。但可能会导致系统文件的不一致。 把 ext4 的 journal 日志迁移到更快的磁盘上,如 ssd、闪存等。操作复杂,不易维护。 使用 xfs、fat 等 文件系统格式。特性不了解,影响不可知。
当然,对于这几种方案,我也做了压测,以下是压测的结果。
| 文件系统特性 | 接口超时比例 |
|---|---|
| ext4(同线上) | 0.202% |
| xfs文件系统 | 0.06% |
| page过期时间和pdflush启动时间都设置为 0.8s | 0.017% |
| ext4 挂载时 journal 模式为 writeback | 0% |
| 禁用 ext4 的 journal 特性 | 0% |
| log4j2 使用异步日志 | 0% |
小结
接口超时问题总算是告一段落,查了很久,不过解决它之后也非常有成就感。遗憾的是没有在 linux 内核代码中找到证据,160M 的代码,分层也不熟悉,实在是无从查起,希望以后有机会能慢慢接触吧。
程序员还是要懂些操作系统知识的,不仅帮我们在应对这种诡异的问题时不至于束手无策,也可以在做一些业务设计时能有所参考。
又熟悉了一些系统工具和命令,脚手架上又丰富了。