
手把手教你使用scrapy框架来爬取北京新发地价格行情(实战篇)
共 3190字,需浏览 7分钟
·
2021-10-03 02:38
回复“书籍”即可获赠Python从入门到进阶共10本电子书
大家好!我是霖hero。上个月的时候,我写了一篇关于IP代理的文章,手把手教你使用XPath爬取免费代理IP;前几天,我又发布了第二篇文章,这篇文章主要是讲Scrapy理论知识的,手把手教你使用scrapy框架来爬取北京新发地价格行情(理论篇),今天在这里分享我的第三篇文章,关于Scrapy实战的应用文章,希望大家可以喜欢。
前言
关于Scrapy理论的知识,可以参考我的上一篇文章,这里不再赘述,直接上干货。
实战演练
爬取分析
首先我们进入北京新发地价格行情网页并打开开发者工具,如下图所示:
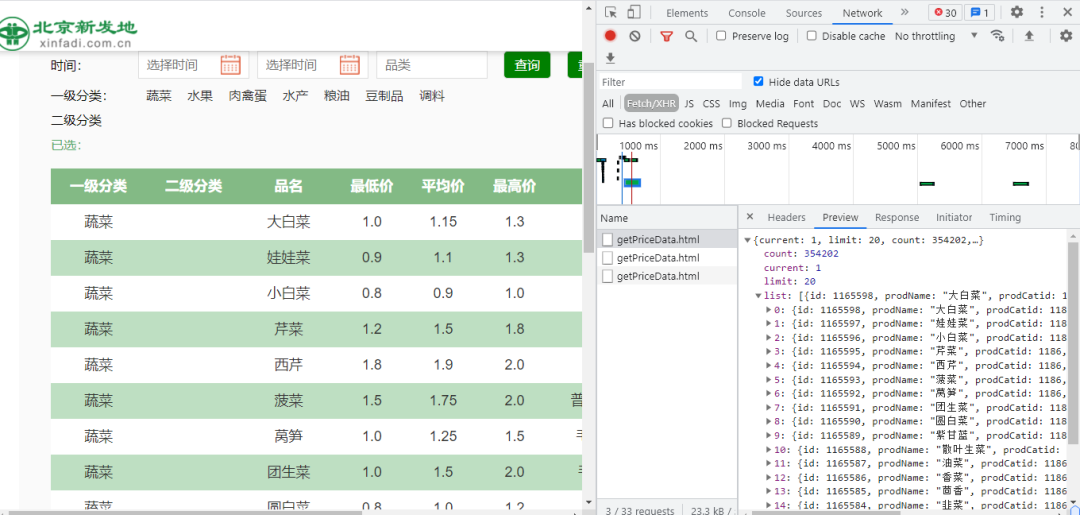
经过简单的查找,发现每个getPriceData.html存放着价格行情的数据,由此可得,我们可以通过getPriceData.html来进行数据的获取。
观察Headers请求,如下图所示:
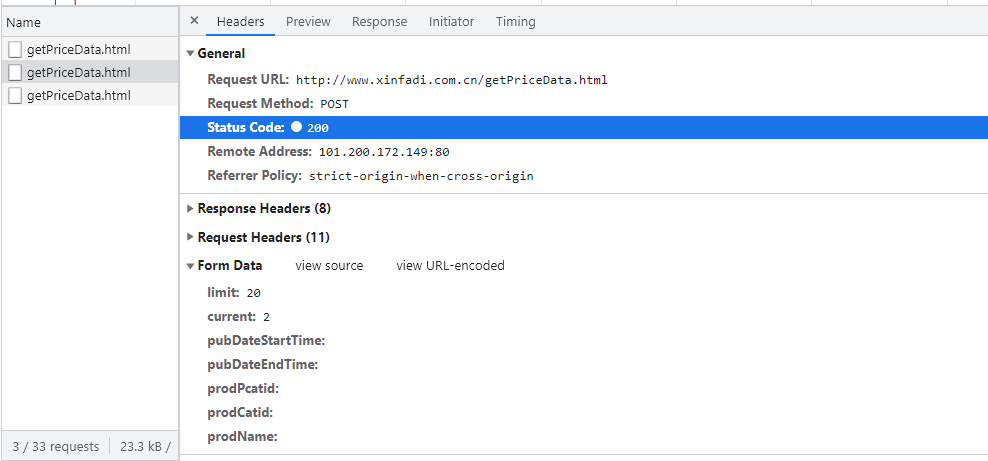
发现它是POST请求,请求URL链接是http://www.xinfadi.com.cn/getPriceData.html,current是翻页的重要参数,limit是每页有多少行数据,我们可以构造消息体,代码如下所示:
data={'limit': '20','current':page}
通过scrapy.Request()方法将消息体传入到参数里面。
或者我们可以根据测试和观察规律,自己构造URL链接,通过观察分析,请求的URL链接可以为:
http://www.xinfadi.com.cn/getPriceData.html?limit=20¤t=1http://www.xinfadi.com.cn/getPriceData.html?limit=20¤t=2http://www.xinfadi.com.cn/getPriceData.html?limit=20¤t=3
创建Spider爬虫
分析北京新发地价格行情后,接下来我们首先创建一个Scrapy项目,使用如下命令:
scrapy startproject Vegetables这样我们就成功创建了一个Scrapy项目,项目文件如下所示:
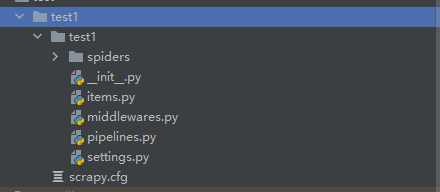
接下来创建spider爬虫,使用如下命令:
scrapy genspider vegetables www.xinfadi.com.cn创建后vegetables.py内容如下所示:
import scrapyclass VegetablesSpider(scrapy.Spider):name = 'vegetables'allowed_domains = ['www.xinfadi.com.cn']start_urls = ['https://www.xinfadi.com.cn']def parse(self, response):pass
提取数据
在提取数据前,我们首先把要爬取的数据字段在items.py文件中定义好,代码如下所示:
import scrapyclass VegetablesItem(scrapy.Item):# define the fields for your item here like:productName = scrapy.Field()lowPrice=scrapy.Field()highPrice=scrapy.Field()
这里我们定义了三个字段分别是productName、lowPrice、highPrice
定义好字段后,接下来将在创建的vegetables.py文件中进行数据的提取,具体代码如下
import scrapyfrom Vegetables.items import VegetablesItemclass VegetablesSpider(scrapy.Spider):name = 'vegetables'allowed_domains = ['www.xinfadi.com.cn']def start_requests(self):for i in range(1, 3):url = f'http://www.xinfadi.com.cn/getPriceData.html?limit=20¤t={i}'yield scrapy.Request(url=url, callback=self.parse)def parse(self, response):html = response.json()fooddata = html.get('list')for i in fooddata:item=VegetablesItem()item['highPrice'] =i.get('highPrice'),item['lowPrice'] = i.get('lowPrice'),item['prodName'] = i.get('prodName'),yield item
首先我们导入vegetablesitem,使用start_requests函数实现翻页,大家可以使用刚才我们所讲的方法实现翻页,实现翻页后,我们通过编写parse()方法实现数据的获取,首先我们把引擎响应的数据以json()格式存放在html里面,调用get()方法来提取我们想要的数据,最后通过yield生成器返回给引擎。
最后我们在settings.py设置引擎的启动,代码如下所示:
ITEM_PIPELINES = {'Vegetables.pipelines.VegetablesPipeline': 300,}
在这里我们就不保存数据在MongoDB数据库里面了,我们直接启动Spider爬虫并把数据以csv格式输出,使用如下命令:
scrapy crawl vegetables -o 11.c运行结果如下:
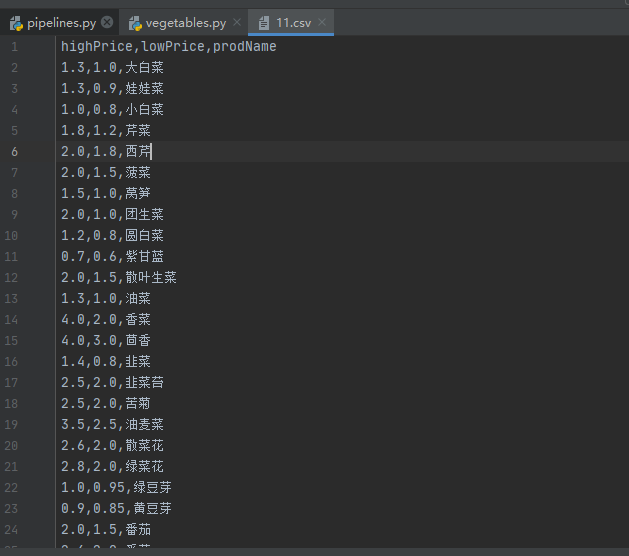
好了,Scrapy框架爬取北京新发地就讲解到这里了,感谢观看!!!
总结
大家好,我是霖hero。这篇文章基于上篇理论文章,主要给大家分享了Scrapy爬虫框架的实战内容,Scrapy是一个基于Twisted的异步处理框架,是纯Python实现的爬虫框架,是提取结构性数据而编写的应用框架,其架构清晰,模块之间的耦合程度低,可扩展性极强。
最后需要本文完整代码的小伙伴,可以在后台回复关键字“菜狗”进行获取,觉得不错,记得点赞、收藏、转发三连支持噢!
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~