
5张图,带你了解微服务架构治理
导读
随着公司业务规模的扩大,越来越多的公司选择了从单体架构转向微服务架构,将单体应用拆分成多个微服务更适合“较大”规模的业务。拆分成微服务后,各服务所负责的业务独立性更强,管理更方便,代码冲突更少,版本迭代更快,更能推动业务快速向前发展。
但是微服务化也带来了新的问题,在单体应用中所有的一切都发生在同一个进程内,业务间交互仅仅是方法间的调用,而拆分成微服务后,各业务间的交互就要通过rpc调用来进行,系统变得更为复杂,这就需要就引入服务治理的概念来对各服务及服务间的交互进行管理,例如:服务注册与发现、监控、鉴权&限流等。
本文从转转公司的服务治理实践出发,带领读者揭开服务治理的神秘面纱。
1 整体架构
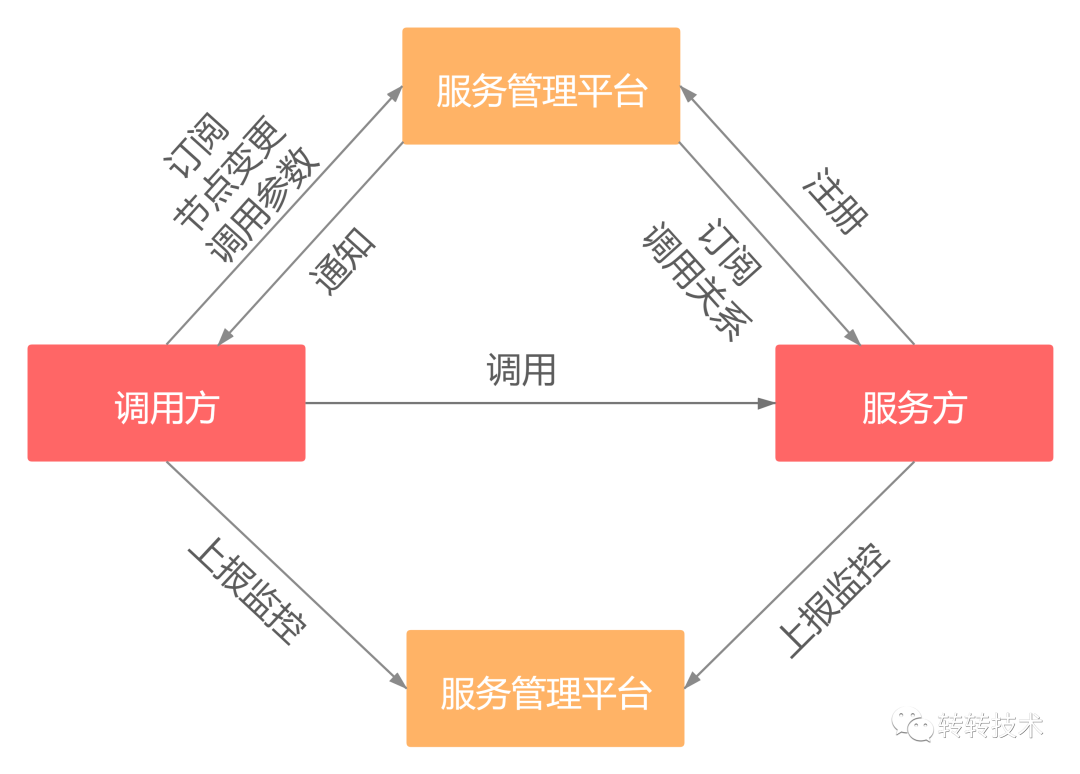
转转服务管理平台是集服务注册与发现、配置中心、监控中心、报警、鉴权&限流于一体的综合性服务治理平台,rpc框架与服务管理平台通过sdk进行交互。
当服务方启动时会向管理平台进行节点注册,并且向服务管理平台订阅调用关系用于调用鉴权、限流等功能。而订阅该服务方的调用方将收到服务方节点上线、下线事件通知,并重新通过sdk拉取服务方的节点列表。
在进行调用时,调用方和服务方都通过sdk向服务管理平台上报调用耗时、超时、异常、耗时分布、top百分位等指标。
同时服务管理平台还具有配置中心的功能,调用方可以通过服务管理平台配置rpc调用相关的参数,例如超时时间、序列化协议等参数,修改后将实时生效。
2 服务注册与发现
2.1 AP模型还是CP模型
注册中心为了高可用,往往会有多个节点,在分布式系统CAP理论中,不可能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance),往往我们会在AP和CP之间做出选择设计我们的系统。典型的注册中心如zookeeper、etcd是CP模型,而eureka是AP模型,nacos既可以工作在CP模式下也可以工作在AP模式下。
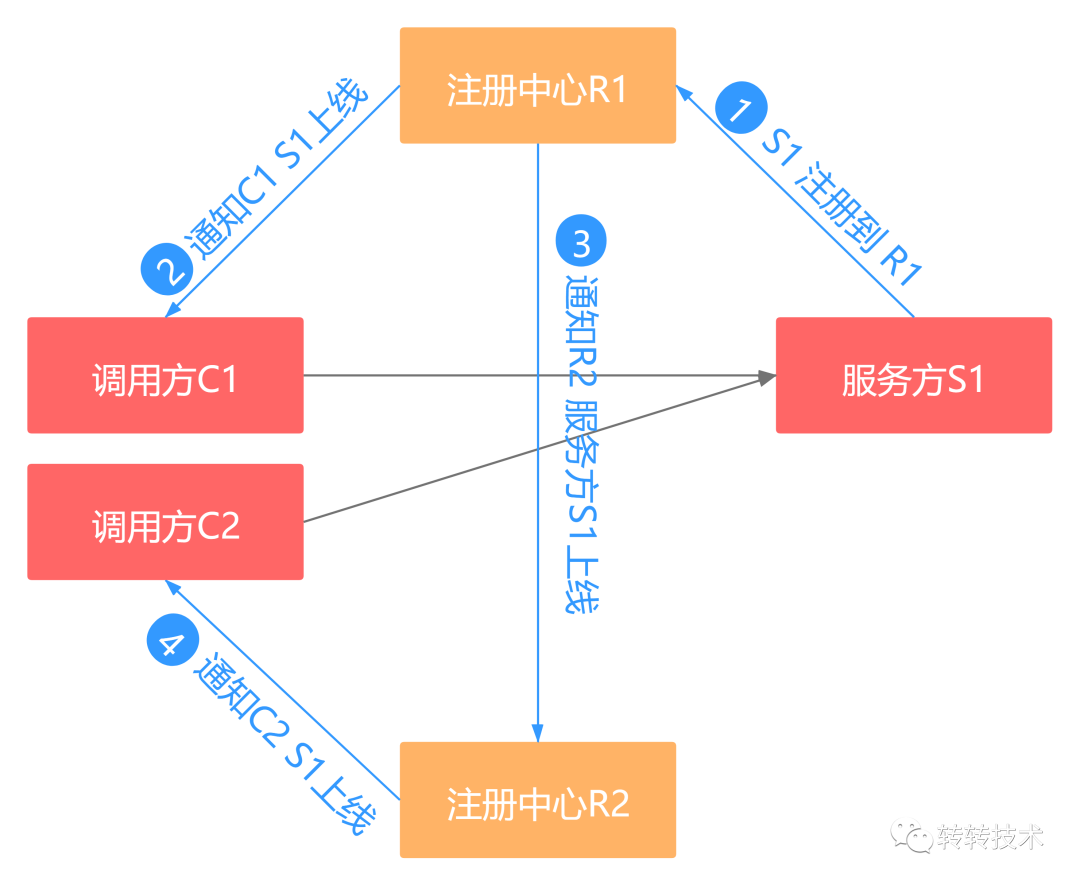
我们模拟一种场景来看看注册中心应该是CP还是AP系统。现有注册中心R1和R2,调用方C1和C2,C1和R1建立长连接,C2和R2建立长连接。
服务方S1注册到R1上,R1通知C1 S1的上线事件,再通知R2 S1的上线事件,而R2又将S1的上线事件通知到C2,此时C1和C2都获取到了S1的上线事件,C1和C2都可以调用到S1节点。
又有服务方S2注册到R2上,R2通知C2 S2的上线事件,再通知R1 S1的上线事件,此时发生了异常导致R2未能通知到R1 S2的上线事件,显然C1也未能得到S2的上线事件。C1只能调用S1节点,而C2可以调用S1和S2节点。
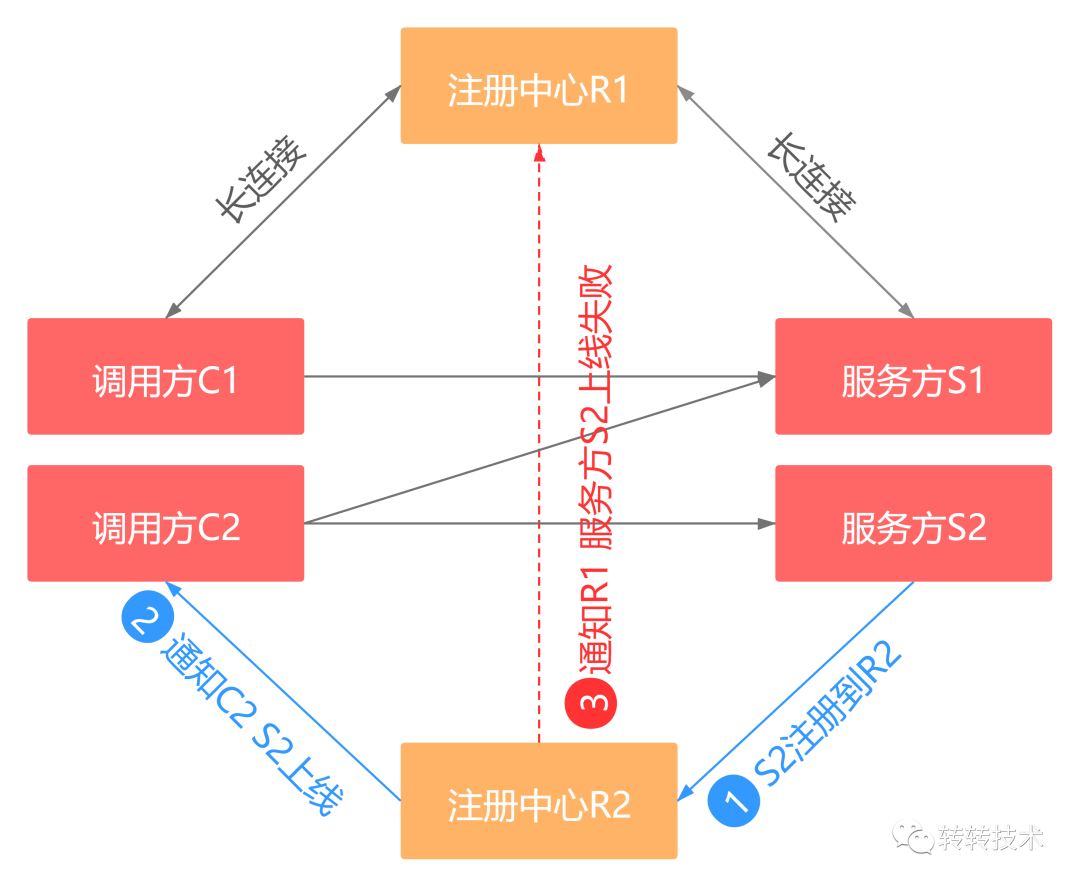
我们看到此时出现了不一致性,如果是CP系统,在解决不一致性问题之前是不能进行下一步操作的,也就是说不能有新的节点注册上来,此时注册功能已经不可用了。而仔细思考一下,这种情况下rpc调用还能正常进行吗,答案是肯定的。即使出现不一致性,我们也是可以容忍的,所以注册中心应该是一个AP系统。
出现了上述不一致问题怎么解决呢?我们在服务管理平台sdk中设置了定时任务,在未收到节点上线/下线通知时,仍然定时拉取最新的节点列表,以达到最终一致性。
结论:注册中心应该设计为AP系统,中间短暂的不一致是可以容忍的,只要在短时间内达到最终一致性即可,参考:阿里巴巴为什么不用 ZooKeeper 做服务发现[1]。
2.2 节点分组
当服务方有多个调用方,且调用方重要性等级不一样时,我们需要提供服务方节点隔离能力,即对服务方节点进行分组,不同的分组提供给不同的调用方使用。
例如服务方A有节点A-S1、A-S2、A-S3、A-S4,有调用方B、C和D,B重要性远高于C和D,我们期望对B提供更稳定的服务,就可以将A-S1、A-S2、A-S3、A-S4进行分组,例如:A-S1、A-S2分到“服务B专用”组供服务B调用,而A-S3、A-S4在“默认组”供服务C和D调用,如下图所示:
2.3 灰度发现
灰度发现功能是指让某些调用方发现服务方的某些指定节点,一般的用途为规划一条固定的调用链路做灰度验证。如下图所示,有服务A、B、C、D,某次需求修改了服务B、C、D,服务B、C、D从v1版本升级到了v2版本,而且B-v2依赖C-v2,C-v2依赖D-v2。在没有灰度发现功能时,需要将D全量升级至v2,再将C全量升级至v2,最后将B全量升级至v2,如新版本出现bug,回滚耗时长、损失大。
使用灰度发现功能可仅部署B-v2、C-v2、D-v2各一个节点,B-v2只能发现C-v2节点,C-v2只能发现D-v2节点。再配合权重功能将B-v2的权重调低,就可以小流量验证本次需求的正确性,即使出现问题,只需在管理平台操作将B-v2节点移出分组或权重调为零,无须回滚,可保留现场排查问题,损失微小。
3 配置中心
在rpc调用过程中有一系列参数是用户可以配置的,如tcp连接超时时间、请求超时时间(服务级&函数级)、序列化协议、rpc协议版本等。
例如在版本迭代过程中某些方法的耗时增长,上线后需要调用方调整方法超时时间,如果将超时时间写在调用方代码中,将调用方重新上线是不太现实的,此时就需要参数热更新功能。转转管理平台支持rpc参数的下发,配合rpc框架支持rpc参数的热更新功能,可实现平台参数调整服务实时生效。
4 监控中心
监控是服务治理中至关重要的一环,面对服务数量小则几百、多则成千上万的场景,再加上各服务间的调用关系,共同组成一张庞大的微服务网络,完善的监控设施是我们洞察这张网的火眼金睛。监控一般包括调用量、异常量、耗时、耗时分布、耗时百分位等。
监控中的难点在于,如此庞大的数据量如何上报、存储与查询的问题。转转的解决方案是针对常用查询维度提前对数据进行多阶段聚合计算,以提升查询效率。
4.1 sdk聚合
在管理平台sdk中,对调用数据的总耗时、平均耗时、最大耗时、耗时百分位、耗时分布等进行提前计算,并以分钟为维度进行上报,大大减少监控数据上报量,节省带宽,减少资源占用。
4.2 后端存储前聚合
sdk上报的数据中仅包含当前节点的监控数据,如将这些数据直接存储,那么查询服务级监控数据时再进行实时聚合计算是不太现实的,庞大的数据量将直接导致数据库不可用。
对此我们以各个查询维度在数据存储之前再次进行聚合,例如sdk上报的原始数据为<C,CIP,S,SIP,Data>,我们期待以<C>、<S>、<C,S>等维度进行查询,那么就根据sdk上报的原始数据在存储前以这些维度进行聚合计算,直接存储计算后的结果。如此以来可实现毫秒级监控数据查询。
5 鉴权&限流
鉴权是指服务间的调用权限控制,限流是指服务间的调用量控制,转转管理平台具有服务级&方法级调用权限及调用量控制能力。
若想实现方法级的调用权限及调用量控制能力,需要有标识来定位唯一的rpc方法,我们提出methodKey概念来标识唯一的rpc方法,具体格式为:(${ServiceImpl})${ServiceInterface}.$method($parameterTypes)。例如某rpc接口UserService中有saveUser(User user)方法,其实现类为UserServiceImpl,则该方法的methodKey为(UserServiceImpl)UserService.saveUser(User),methodKey中所使用的类名均为简单类名,由rpc框架来校验每个服务中methodKey的唯一性。
在服务方启动时rpc框架将暴露出的rpc方法列表通过sdk上传至服务管理平台,在服务进行调用之前需要在服务管理平台申请对方法的调用权限及调用量配置。并通过sdk订阅其他调用方对本服务的调用关系,做到实时修改生效。
在rpc框架中通过Filter扩展并结合管理平台sdk即可实现对服务调用的权限校验及流量控制能力。
6 报警
报警也是服务治理中必不可少的一环,在服务治理中发挥着哨兵的作用。依托管理平台监控能力,在出现调用异常、超时、限流时及时向服务负责人发出警报。转转管理平台允许用户对告警进行手动配置,包括告警间隔时间、告警方法、告警的服务方和调用方等。
7 总结
本篇文章从转转服务治理的整体架构出发,又分篇介绍了服务治理中主要功能的实现,以便各位读者对服务治理有简单的认识。
当然,服务治理的能力并不仅限于文中所述,转转的管理平台也不是完美的,仍然有许多问题需要解决,例如通知机制的高可用问题、一致性问题,监控数据存储问题等。我们将继续前行在技术的道路上,生命不息,探索不止。
关于作者
王建新,转转架构部资深Java工程师,主要负责服务治理、RPC框架、分布式调用追踪、监控系统等,热衷于技术,有丰富的线上实战经验。
参考资料
阿里巴巴为什么不用 ZooKeeper 做服务发现: https://github.com/markdown-it/markdown-it/issues/410
往期推荐
如果你觉得这篇文章不错,那么,下篇通常会更好。添加微信好友,可备注“加群”(微信号:zhuan2quan)。
和花一辈子都看不清的人,
注定是截然不同的搬砖生涯。
