
所谓数据治理


在阅读本文之前,你需要了解:
那些年,我们一起踩过的坑

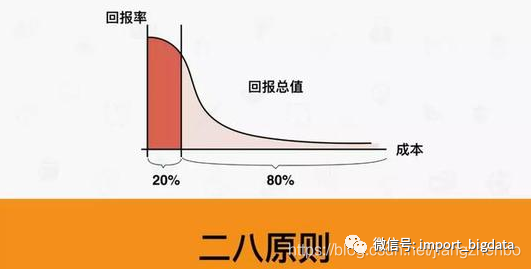


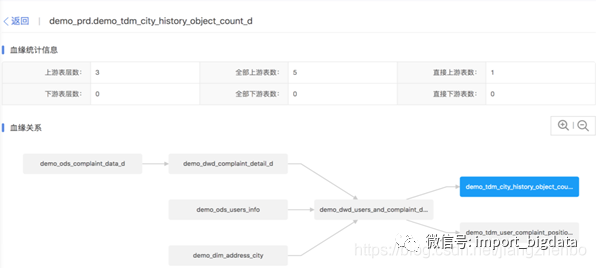
数据治理之元数据管理
一、元数据到底是个啥?



二、元数据是从哪里来的?
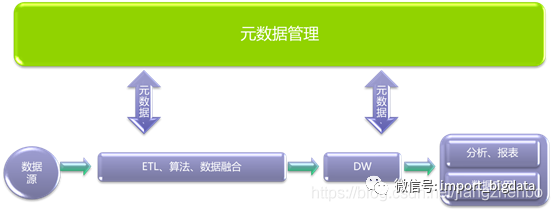
三、有了元数据,我们能做些什么?
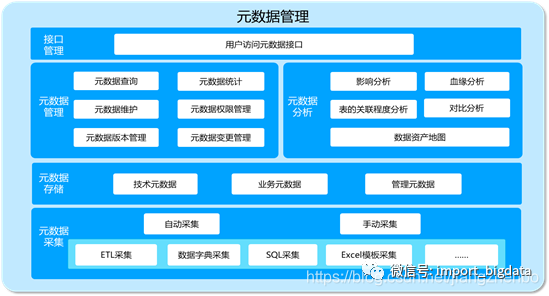
数据治理之数据质量管理
一、数据质量管理的目标
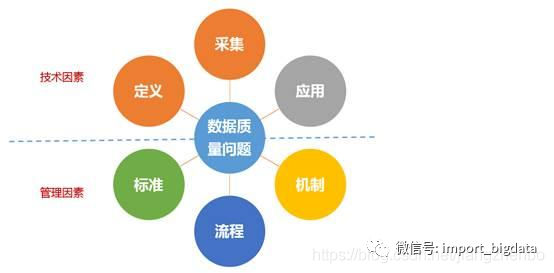
二、数据质量问题产生的根源
三、数据质量评估的标准
准确性: 描述数据是否与其对应的客观实体的特征相一致。
完整性: 描述数据是否存在缺失记录或缺失字段。
一致性: 描述同一实体的同一属性的值在不同的系统是否一致。
有效性: 描述数据是否满足用户定义的条件或在一定的域值范围内。
唯一性: 描述数据是否存在重复记录。
及时性: 描述数据的产生和供应是否及时。
稳定性: 描述数据的波动是否是稳定的,是否在其有效范围内。
以上数据质量标准只是一些通用的规则,这些标准是可以根据数据的实际情况和业务要求进行扩展的,如交叉表校验等。
四、数据质量管理的流程
五、数据质量管理的取与舍
历史数据
总结
数据治理之数据标准管理
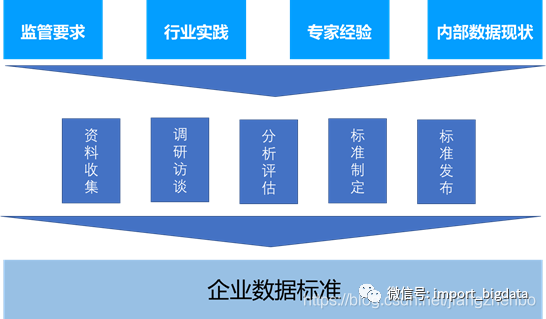
一、大数据标准体系
二、关于数据标准认识的几个误区
三、数据标准的定义
四、如何制定数据标准
五、数据标准化的难题
对建设数据标准的目的不明确。某些组织建设数据标准,其目的不是为了指导信息系统建设,提高数据质量,更容易地处理和交换数据,而是应付监管机构检查,因此需要的就是一堆标准文件和制度文件,根本就没有执行的计划。
过分依赖咨询公司。一些组织没有建设数据标准的能力,因此请咨询公司来帮忙规划和执行。一旦咨询公司撤离,组织依然缺乏将这些标准落地的能力和条件。
对数据标准化的难度估计不足。很多公司上来就说要做数据标准,却不知道数据标准的范围很大,很难以一个项目的方式都做完,而是一个持续化推进的长期过程,结果是客户越做遇到的阻力越大,困难越多,最后自己都没有信心了,转而把前期梳理的一堆成果束之高阁,这是最普遍的问题。
缺乏落地的制度和流程规划。数据标准的落地,需要多个系统、部门的配合才能完成。如果只梳理出数据标准,但是没有规划如何落地的具体方案,缺乏技术、业务部门、系统开发商的支持,尤其是缺乏领导层的支持,是无论如何也不可能落地的。
组织管理水平的不足:数据标准落地的长期性、复杂性、系统性的特点,决定了推动落地的组织机构的管理能力必须保持在很高的水平线上,且架构必须持续稳定,才能有序地不断推进。以上这些原因,导致数据标准化工作很难开展,更难取得较好的成效。数据标准化难落地,是数据治理行业的现状,不容回避。
六、如何应对这些难题
源系统改造:对源系统的改造是数据标准落地最直接的方式,有助于控制未来数据的质量,但工作量与难度都较高,现实中往往不会选择这种方式,例如有客户编号这个字段,涉及多个系统,范围广、重要程度高、影响大,一旦修改该字段,会涉及到相关的系统都需要修改。但是也不是完全不可行,可以借系统改造,重新上线的机会,对相关源系统的数据进行部分的对标落地。
数据中心落地:根据数据标准要求建设数据中心(或数据仓库),源系统数据与数据中心做好映射,保证传输到数据中心的数据为标准化后的数据。这种方式的可行性较高,是绝大多数组织的选择。
数据接口标准化:对已有的系统间的数据传输接口进行改造,让数据在系统间进行传输的时候,全部遵循数据标准。这也是一种可行的方法。
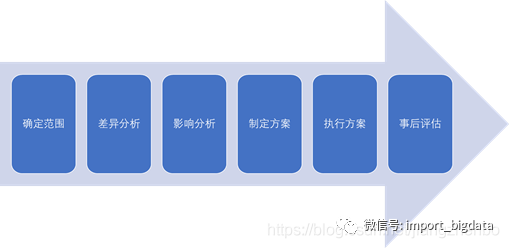
事先确定好落地的范围:哪些数据标准需要落地,涉及到哪些IT系统,都是需要事先考虑好的。
事先做好差异分析:现有的数据和数据标准之间,究竟存在哪些差异,这些差异有多大,做好差异性分析。
事先做好影响性分析:如果这些数据标准落地了,会对哪些相关下游戏厅产生什么样的影响,这些影响是否可控。元数据管理中的影响性分析可以帮助用户确定影响的范围。
制定落地的执行方案:执行方案要侧重于可落地性。不能落地的方案,最终只能被废弃。一个可落地的方案,要有组织架构和人员分工,每个人负责什么,如何考核,怎么监管,都是必须纳入执行方案中的内容。
具体地执行落地方案:根据执行方案,进行数据标准落地执行。
事后评估:事后需要跟踪、评估数据落地的效果如何,做对了哪些事,哪些做得不足,如何改进。
七、总结
数据治理之数据资产管理
数据资产与数据资产管理的定义
数据资产管理的现状和挑战
缺乏统一的数据视图:数据资源分布在企业的多个业务系统中,分布在线上线下,甚至企业的内外部,由于缺乏统一的数据视图,数据的管理人员和使用人员无法准确快速地找到自己需要的数据。数据管理人员也无法从宏观层面掌握自己拥有哪些数据资产,拥有多少数据资产,这些数据资产分布在哪里,变化情况怎么样。
数据基础薄弱:大部分企业的数据基础还很薄弱,存在数据标准混乱、数据质量参差不齐、各业务系统之间数据孤岛化严重、没有进行数据资产的萃取等现象,阻碍了数据的有效应用。
数据应用不足:受限于数据基础薄弱和应用能力不足,多数企业的数据应用刚刚起步,主要在精准营销、舆情感知和风险控制等有限场景中进行了一些探索,数据应用的深度不够,应用空间亟待开拓。
数据价值难估:企业难以对数据给业务的贡献进行评估,从而难以像运营有形资产一样运营数据。产生这个问题的原因有两个:一是没有建立起合理的数据价值评估模型;二是数据价值跟企业的商业模式密不可分,在不同应用场景下,同一项数据资产的价值可能截然不同。
缺乏安全的数据环境:随着数据的价值越来越得到全社会的广泛认可,针对数据的犯罪活动日渐猖獗,数据泄露、个人隐私受到伤害等现象层出不穷。很多数据犯罪是因为安全管理制度不完善、缺乏相应的数据安全管控措施导致的。
数据管理浮于表面:没有建立一套符合数据驱动的组织管理制度和流程,没有建设先进的数据管理平台工具,导致数据管理工作很难落地。
这些问题已经严重影响到数据价值的发挥,导致企业的数据越积越多,却逐渐成为企业的负担,大数据管理部门也成为企业的成本中心,而不是创新中心和利润部门。
数据资产管理的四个目标
可见:通过对数据资产的全面盘点,形成数据资产地图。从数据生产者、管理者、使用者等不同的角度,用数据资产目录的方式共享数据资产,用户可以快速、精确地查找到自己关心的数据资产。
可懂:通过元数据管理,完善对数据资产的描述。同时在数据资产的建设过程中,注重数据资产业务含义的提炼,将数据加工和组织成人人可懂的、无歧义的数据资产。具体来说,在数据中台之上,需要将数据资产进行标签化,标签是面向业务视角的数据组织方式。
可用:通过统一数据标准、提升数据质量和数据安全性等措施,增强数据的可信度,让数据科学家和数据分析人员没有后顾之忧,放心地使用数据资产,降低因为数据不可用、不可信而导致的沟通成本和管理成本。
可运营:数据资产运营的最终目的是让数据价值越滚越大,因此数据资产运营要始终围绕资产价值来开展。通过建立一套符合数据驱动的组织管理制度流程和价值评估体系,促进数据资产建设过程的不断改进,提升数据资产管理的水平,提升数据资产的价值。
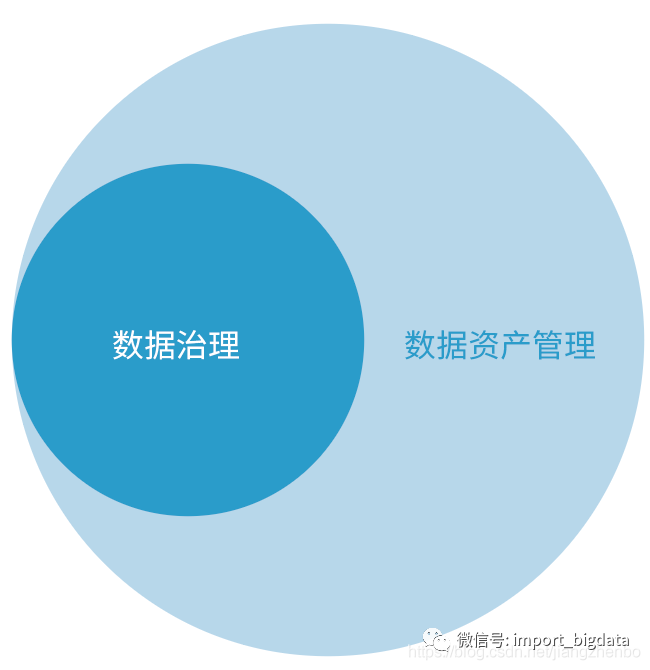
数据资产管理与数据治理的关系
数据资产门户
数据资产地图 数据资产地图为用户提供多层次、多视角的数据资产图形化呈现形式。数据资产地图让用户用最直观的方式,掌握数据资产的概况,如数据总量、每日数据增量、数据资产质量的整体状况、数据资产的分类情况、数据资产的分布情况、数据资产的冷热度排名、各个业务域及系统之间的数据流动关系等。
数据资产目录
数据资产检索
