
Pulsar与Rocketmq、Kafka、Inlong-TubeMQ,谁才是消息中间件的王者?

导语 | Pulsar作为下一代消息中间件的典型代表,在设计和实现上面都具备很好的前瞻性,综合考量了业界现存的一些比较常用的、优秀的消息中间的架构设计、适用场景、运营中的问题等,如目前用的比较多的Kafka、Rocketmq、Inlong-TubeMQ等。本文仅从设计角度出发,说明下Pulsar与Kafka、Rocketmq及腾讯开源的Inlong-TubeMQ在实现上的几点区别和可能遇到的问题,供大家参考。
一、云原生多租户设计
(一)分级命名
Pulsar原生支持多租户设计,非常适合作为云产品进行管理。Pulsar的topic名称如下图所示:
persistent://tenant/namespaces/topic分为四个部分:
第一部分:Domain,表示存储方式,分为nonpersistent和persistent,对应非持久化和持久化存储;
第二部分:tenant,表示租户名称,公司或团队内部使用时,也可以作为部门名称、业务分类等;
第三部分:namespace,表示命名空间,作为租户内部的一个层级划分;
第四部分:topic名称,具体的topic。Pulsar支持分区和非分区topic。但是,在业务侧视角,很难看出是否是分区topic,需要查看元数据或者日志信息。
Kafka/Rocketmq/Inlong-TubeMQ,从设计上和管理的角度看,对上云并不是特别友好。Topic管理上完全是平级的,如果需要区分不同的用户、不同的部门的topic,需要在运营层面做一定的设计支持。
(二)多级流控
Pulsar支持Broker级别、Namespace级别、Topic级别的流控,包括生产、消费的出入流控,客户端的连接数,存储配额等。
Kafka/Rocketmq/Inlong-TubeMQ的流控措施和策略相对来说要少很多,具体可以参考相关资料。
二、计算与存储
(一)Broker状态
Pulsar的broker是无状态的,这和它的计算、存储分离的架构设计有关,broker端不需要保存任何的元数据和消息信息。可以根据系统的需求,进行动态的扩/缩容处理。
Rocketmq broker具备主备的概念,且broker侧本地需要存储消息。单个broker使用一个逻辑的commitlog文件,以wal的方式写入消息。(目前,高版本已经引入自动主备选主能力和Dledger进行计算与存储分离处理,有需要的也可以关注下),所以默认方式下,算是一个有状态的broker。
另外,Rocketmq的备,仅在主挂掉或者主负载过高的时候才会提供读取服务,算是冷备份。这在目前逐步强调机器利用率的环境下,算是一个待优化的设计点。
Kafka中也有主、备的概念区分,但是主备是partition维度的。Kafka broker端也需要存储消息,它的每个分区会使用wal方式存储消息,相对Rocketmq而言会多用很多写FD(即会同时对应到多个以wal方式写入的文件句柄),这块也是Kafka在broker端分区总数过多的时候,性能下降的一个原因。
Inlong-TubeMQ中broker没有主备的概念,消息仅会存储在broker本地一份,从存储角度看Inlong-TubeMQ中的broker算是个有状态的。由于消息只会被存储一份,Inlong-TubeMQ的使用场景会受到一定的限制。但是,Tubemq broker也因此具备很高的处理性能,比较适合容忍少量丢失和需要高性能的应用场景,目前公司内部在大数据场景,有大规模的应用。
(二)集群扩展能力
Puslar的服务器端,分为broker和bookie两个部署,broker负责接入、计算、拉取、分发消息等,bookie负责消息存储存储。broker、bookie均可以按需动态的进行扩缩容处理。
其中,bookie存储过程中的多副本、数据条带化分布处理等均在bookkeeper的客户端sdk中实现,是一个胖客户端的逻辑。broker作为bookie的客户端存在,消息数据会总体均匀的分布在bookie集群中。不会出现因为某些topic或着某些topic的部分分区,在数据大规模倾斜时,导致部分存储机器磁盘使用率过高的问题。当然,如果系统需要保存的消息量比较大,扩容时可能需要同时扩容多台bookie机器(写入的副本个数的整数倍)。
此外,bookie集群扩容后,系统在写入新消息的时候会优先选用新加入的、负载低的节点作为候选节点,在存量节点不受影响的情况下,将新增消息写入到新扩容的节点上。
Rocketmq的broker端,扩展能力也比较强,只要新增主备对到集群中即可。但是需要在扩容完毕后,在新增的broker对上面创建对应的topic和订阅组信息。
此外,Rocketmq比较强大的一点是,broker端具备读、写权限控制的能力,可以针对单个topic的单个Queue和broker进行读写控制,非常便于运维操作。
Kafka的broker端,在扩所容的时候要略显麻烦些,使用的时候需要提前评估好容量,如果在运营的过程中进行扩容,需要做部分数据的迁移操作。
InLong-TubeMQ的broker端,由于是单副本方式,扩容非常容易。只需要对新增的broker节点,分配topic即可。这种设计可以很好的处理部分topic数据比较多,对broker集群产生压力的场景。也可以针对单个topic扩容broker。
三、分区与存储、消费
(一)分区与消息存储
Pulsar、Kafka、Rocketmq、InLong-TubeMQ四者的topic均支持分区配置,但四者的分区又有所不同。
Pulsar中Topic的分区是Topic内针对整个集群范围的,每个分区topic的分区数编号在集群内递增。而每个分区在内部生产、消费处理的时候均被作为最小单位的topic进行处理,sdk内部会针对每个分区单独的创建一个producer/consumer进行处理。此外,用户也可以直接的使用某个分区,给某个具体的分区生产或消费某个具体分区的消息。
例如,使用客户端sdk直接订阅分区TopicA中的第n个分区,需要使用topic名称为:persistent://tenant/namespaces/TopicA-paritition-n
当然,如无特殊的业务场景需求,不建议业务方直接这样使用。可以通过sdk中自定义router的方式进行处理。
Pulsar中的每个topic的每个分区与broker的关联关系是通过Namespace的bundle机制进行关联的,可以通过loadbalance机制自动进行load/unload的操作的,也可以通过命令进行unload操作,如图所示:
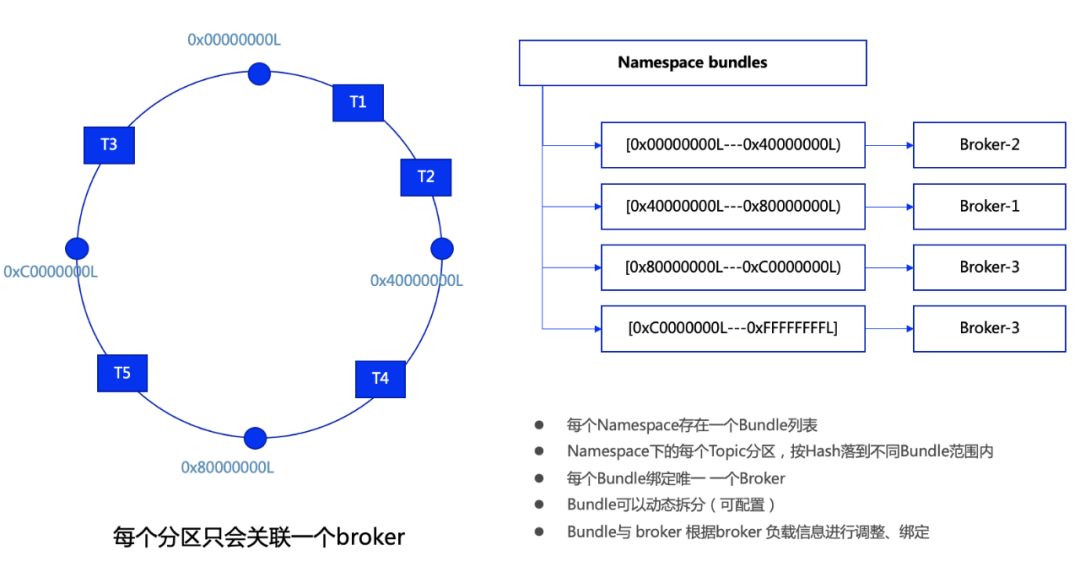
Namespace下的每个bundle区间会关联一个broker(这个关联关系会被loadbalance逻辑修改,同时也可以通过运维命令进行unload处理),每个topic的每个分区通过hash运算落到相应的bundle区间,进而找到当前区间关联的broker。在broker与bundle的关系发生变化时,客户端会有重连操作,会有相应的链接断开和重建建立链接的日志,这个现象是正常的。
当集群内broker节点的个数比较多的时候,可以通过增加topic的分区数,同时调整namespace的bundle数,将topic的分区更加均匀的分布到所有或者大多数的broker节点上,来提升集群针对这个topic的生产/消费性能。
此外,Pulsar中的每个Topic下的每个分区会对应一系列的ledger(ledger id是全局唯一的),逻辑的将消息组织起来,存储到bookie中。
由此可见,Puslar的分区是个物理上面的划分,每个分区单独的处理消息的生产、消费和存储。
Rocketmq中的分区(实际上是Queue的概念,逻辑划分)是针对单个broker主/备关系对的(Rocketmq 的broker 有主/备的区分),在单个主/备关系下的broker 内递增。如果需要在集群内的多个主/备关系对的broker间使用相同的topic,需要针对每个主/备关系对下的broker单独创建相同的topic。每个主/备对关系下的broker上面,相同名称的topic 的分区数可以不同。
Rocketmq的消息数据是通过索引方式,被逻辑的划分到每个Queue的,消费者需要通过索引文件从pagcache或者wal方式写入的commitlog文件中获取消息。
Kafka中的分区,是针对一组broker的,因为Kafka中也具有主/备的概念。但是,Kafka的主备关系是分区级别的,相同topic的不同分区的主可能是不同的broker。这样集群下的每个broker 均可交叉的对外提供读写服务。
InLong-TubeMQ中的分区,与Kafka的类似,但是在存储的处理上又有很大的不同。Kafka是针对每个分区单独进行处理的,而Inlong-TubeMQ是针对每个topic进行存储处理的。
这里对存储的具体处理的区别小结一下:
Pulsar,broker上面不存储消息,消息使用bookkeeper集群进行存储。
Rocketmq,单个broker采用wal的方式使用逻辑上唯一的一个commitlog文件存储消息数据(高版本支持存储分离)。
Kafka,单个broker采用wal的方式,针对每个分区在逻辑上使用一个文件存储这个分区上的消息。
InLong-Tubemq,单个broker采用wal的方式,针对每个Topic在逻辑上使用一个文件存储这个Topic下所有分区上的消息。
(二)分区与消费者
Pulsar中,每个topic下的每个分区会与每个订阅组下的所有消费者进行关联。这里与Kafka/Rocketmq/InLong-TubeMQ有很大的区别,如图下图所示。
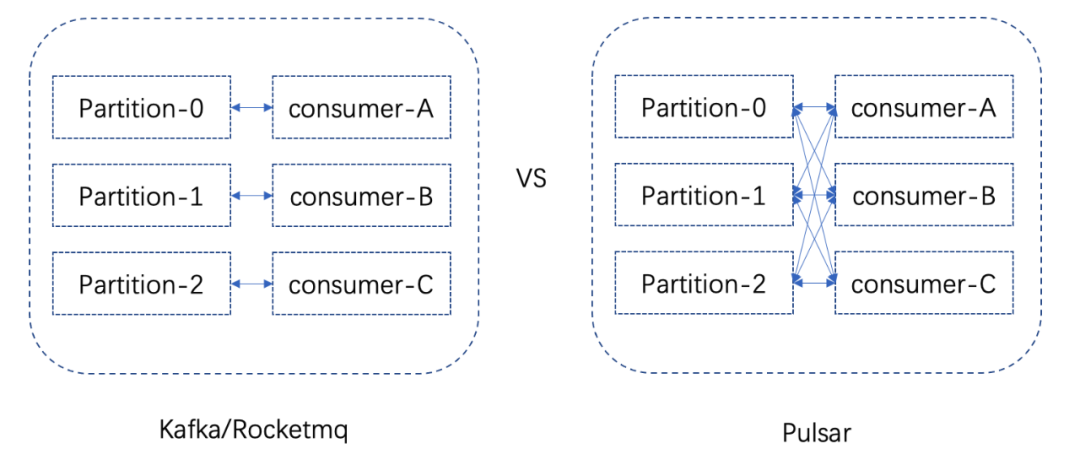
Kafka/Rocketmq/InLong-TubeMQ每个分区会负载到一个comsumer上,多出partition个数的consumer将不会起作用(即多出的消费者不能消费任何的消息)。而Pulsar这面,每个分区会与订阅下的所有消费者客户端进行关联,broker端会根据每个消费者客户端的能力,将消息推送给客户端进行消费。Pulsar的这种设计,在很大程度上提高了系统可承载的消费能力。业务方可以根据自己的消费需求,并行的部署多于分区个数的消费者。
但是,这种设计,有利也有弊,不但提高了系统实现的复杂度,也为broker端的客户端管理埋下了隐患,需要运营过程中,做好消费客户端个数、流量等的流控配置,避免因业务方使用不当,引起broker端负载压力过大,进一步导致broker oom、宕机等。
此外,Pulsar支持shared、key_share、failover、exclusice四种模式消费,但不支持广播模式消费消息,这一点与Kafka/Rocketmq/InLong-TubeMQ有比较大的区别。
(三)分区与顺序消息
目前业界,如Kafka/Rocketmq/InLong-TubeMQ等实现顺序消息的大致方法是将顺序消息,按照顺序分组关键字(或对应的key),在生产的时候,将顺序消息分发到同一个partition中。消费时,因为partition与consumer是一对一的关系,通过简单的处理即可保证消费的顺序性。如下图所示:
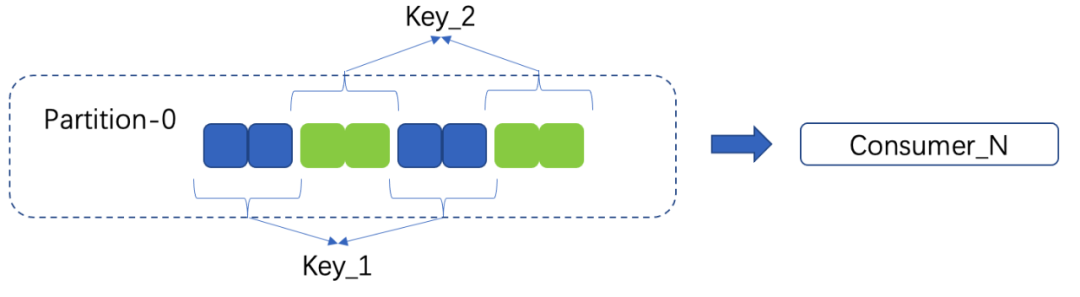
但是,这里会有个问题,负载到同一个partition中的不同分组之间实际是可以并行消费的,顺序性仅需要保证在同一个分组内即可。如果,消费者与partition是一对一的对应关系,顺序消费,效率会比较低。
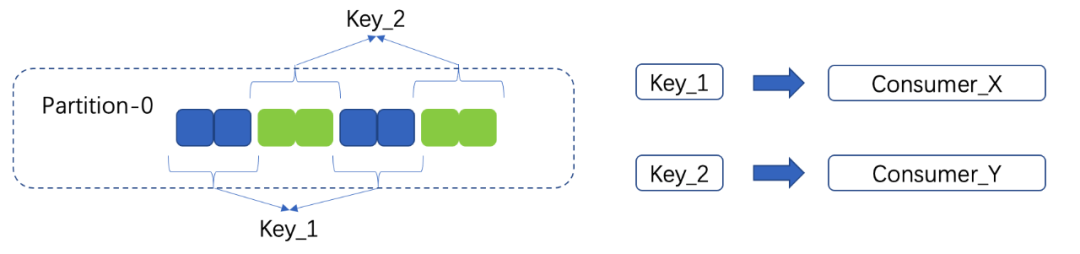
在Pulsar中,每个分区与多个消费者做关联。在顺序消息的场景,生产的时候也是根据key,将消息负载到相同的parititon内。而消费的时候,则是根据key,按照key的维度,每个key关联到固定的consumer,同一个parititon内的不同key的消息,使用不同(如果consumer足够多)的但唯一的一个consumer进行推送和消费处理,在很大的程度上提高了顺序消息场景下的消费性能。如下图所示:
(四)消息分发机制
Puslar采用的是推模式,broker端给消费者客户端推送消息。客户端在创建consumer的时候,会配置当前consumer 可以接受的消息的最大能力(receiveQueueSize,默认1000)。broker端会根据这个参数,在服务端给每个consumer初始化对应的permit参数,通过对permit的控制,批量给consumer推送消息。
同时,broker端会统计unack状态的消息个数并进行流控处理,当推送给单个consumer或整个订阅组下的unack状态的消息达到一定阈值后,broker端将不再推送任何消息到当前消费者或整个订阅下的所有消费者(订阅组维度时,即使有部分的消费者有接收能力,broker端也不会在推送消息)。分发消息时的交互流程,如下图所示:
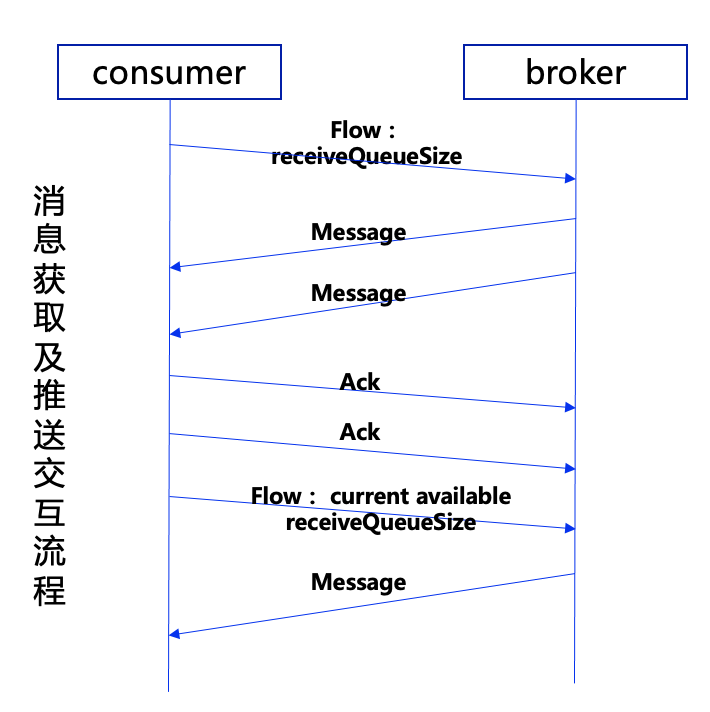
Consumer端会在处理的消息个数达到receiveQueueSize/2时,向broker端重新发送一条Flow命令,变更broker端对应当前consumer的分发permit值。
而Kafka/Rocketmq/InLong-TubeMQ,消费者均采用拉模式获取消息(Rocketmq是客户端用long pull的方式实现的push)。具体细节这里不再做过多的叙述,有兴趣的同学可以单独查阅下相关资料。
另外,在消息过滤方面,Rocketmq/InLong-TubeMQ支持服务器端过滤消息,Kafka支持在客户端过滤消息,Pulsar社区版本暂时不支持服务器端过滤(TDMQ版本支持),服务器端过滤消息的功能,目前在PIP规划和实现中。
具体细节这里不再做过多的叙述,有兴趣的同学可以单独查阅下相关资料。
(五)消息确认保存机制
Kafka/Rocketmq/InLong-TubeMQ在消费确认的时候,每次上报的是当前已经消费的最小的offset值,broker端针对每个topic的每个分区下的每个订阅,保存这个分区下当前订阅的最小的offset,如下图所示:
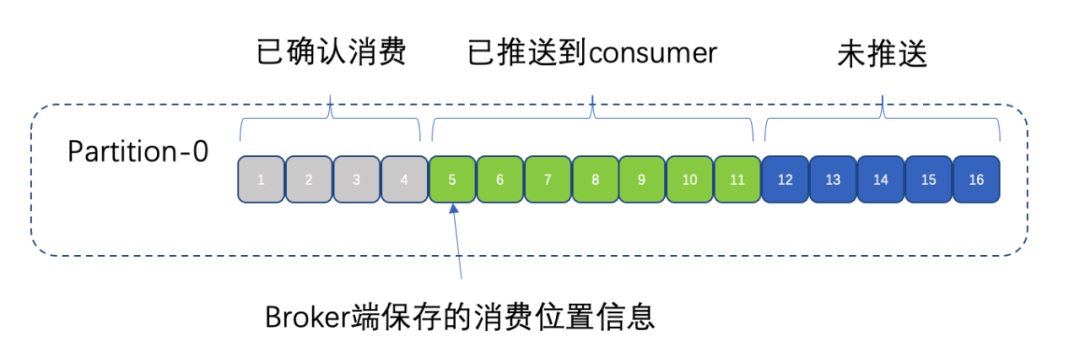
这种实现方式比较简单,但是在运营过程中,会发现存在比较严重的缺陷。因为消息是被批量拉取到客户端的,消费端有可能已经消费了后面的大量的消息,只是因为较小的offset的这条消息例如图中5这个位置,消费过程出错或者消费时间比较长,每次消费确认信息的时候只能上报到5这个位置。表面上看,有大量的消息堆积,其实可能后面的消息已经被消费很多了。当消费者重启的时候会重新从5这个位置重新拉取一遍消息,这时消费者可能要处理大量的重复消息,如果业务侧幂等措施做的不够健壮,可能会对业务造成很大的困扰。
Pulsar中,每个topic的每个分区是与订阅组下的所有消费者关联的,broker端可以将这个分区下的消息按批次分发给每个对应的消费者,每个消费者对接受到的消息进行消费和确认。如果,采用Kafka/Rocketmq/InLong-TubeMQ的确认保存方式,很难处理。因此Pulsar另辟蹊径,如图所示:
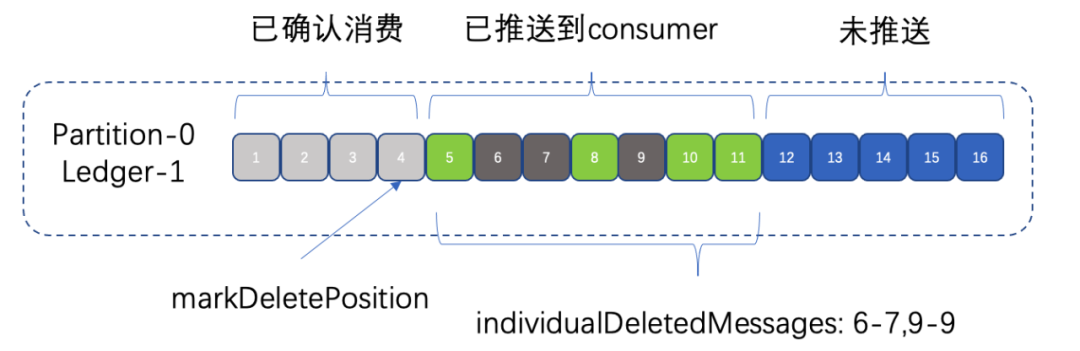
每个分区下的订阅通过markDeletePosition保存当前完全消费的最有一个位点(即这个位置之前的所有消息均已经消费和确认了),使用individualDeletedMessages表示当前正在消费的消息的确认情况,这里不是仅仅的保存一个点,而是保存多个范围,表示markDeletePosition这个位置之后哪些消息范围内的消息已经被确认了。避免了重启之后消息被重复消费的问题。
但是,这里也有一个风险点。如果,individualDeletedMessages中保存的区间信息比较多的时候,需要占用大量的内存空间,会对broker和bookie存储造成压力。因此,我们在使用的时候,需要尽量的将位点连续的消息,连续的消费和确认,避免出现大量的确认空洞。
四、元数据存储
Pulsar目前依赖Zookeeper做元数据的存储。
Rocketmq使用自己实现的NameServer做元数据。NameServer是无状态的、独立的,每个节点之间没有主、备区分,全部对外提供服务。broker在上报元信息的时候,需要向集群内每个NameServer节点上报一份信息。
Kafka正在逐步的做去Zookeeper依赖规划和处理。但是,目前元数据、选主这块还是需要依赖Zookeeper。
InLong-TubeMQ使用集中式的方式管理元数据,broker通过api从后台服务器获取元数据,对zk有比较弱的依赖。
这里提一下,使用Zookeeper的一个风险点。当Zookeeper选主阶段或集群不可用的时间较长时,如果是强依赖的场景,这个时间段内会导致消息中间件集群不可用。
另外,就是Zookeeper只有主节点能处理写请求,当元数据比较多、更新操作比较频繁时会影响系统的整体性能,在做大规模集群部署的时候,需要考虑这个风险点。
五、小结
Pulsar作为新一代的消息中间件产品,在设计架构上了顺应了当前业界云原生的诉求。同时,Pulsar充分调研了Kafka/Rocketmq等优秀消息中间件的优、缺点,在实现上进行扩展和规避。
本文主要介绍了Pulsar与Rocketmq/Kafka/InLong-TubeMQ的几点设计和实现层面与使用方关系比较大的几点区别。
Pulsar的云原生多租户设计,非常适合上云和大规模、多用户场景下的使用和管理。
Pulsar的topic的单分区与多个消费者关联这种设计,在很大程度上能够提升并行的消费能力。但是,broker端和consumer端会占用更多的资源,在使用的时候,需要做好流控策略配置和接入管理。避免因为客户端扩容导致broker集群挂掉。
Pulsar的按位点区间保存消费确认信息的方式,能够极大的避免重复消费消息的问题。但是,同样存在确认空洞的风险,在使用的时候,消费方需要尽量按消息的id顺序连续消费,避免产生大量的确认空洞,导致broker、bookie压力过大。
Pulsar在顺序消费消息的设计上,细化到了key的维度,将相同partition下的相同key的消息推送给相同的consumer进行处理。很大程度上提高了顺序消息场景下的消费能力。
Pulsar在元数据存储上,目前还是需要依赖Zookeeper,不单单是broker集群,bookkeeper集群也对Zookeeper有很强的依赖性。broker、bookie集群均具备很好的可平行扩展能力。但是,Zookeeper集群如果挂掉的话,整个Pulsar集群存在不可用的风险,这点需要进一步的优化处理,在AP和CP之间进行取舍。
此外,Pulsar在运维层面,具有很好的可平行扩展能力和丰富的admin管理接口,原生对运维相对友好。但是,也需要进一步的周边生态的建设。
最后,简单的概括下,每款消息中间件产品都有其自身的优点、缺点和对应的适用场景,选择一款比较适合自己业务团队需求的产品比较关键。综合角度来看,目前公司内部,新的业务还是推荐使用Pulsar,不管是Pulsar的多租户特性、生产/消费设计,还是内部的实现细节,都在考虑性能、可靠性及运维可操作能力的不断提升。
作者简介

鲍明宇
腾讯高级后台开发工程师
腾讯高级后台开发工程师,毕业于东北大学。目前在腾讯TEG数据平台部,负责消息中间件Pulsar、大数据接入套件Inlong相关的开发工作。
推荐阅读
gRPC如何在Golang和PHP中进行实战?7步教你上手!
如何保证MySQL和Redis的数据一致性?10张图带你搞定!
