
原创 | 8 张彩图讲解 Spark 任务提交流程
点击上方 "大数据肌肉猿"关注, 星标一起成长
后台回复【加群】,进入高质量学习交流群

看本文之前需要先了解 Spark 的基本角色,因为本篇重点是提交流程,所以不做展开,需要的同学可以参考官方文档:
https://spark.apache.org/docs/latest/cluster-overview.html
前面我们讲过 9张图详解Yarn的工作机制,惊艳阿里面试官,今天就来讲讲提交 Spark 作业的流程。
Spark 有多种部署模式,Standalone、Apache Mesos、Kubernetes、Yarn,但大多数生产环境下,Spark 是与 Yarn 一起使用的,所以今天就讲讲 yarn-cluster 模式。
当然我也见过不带 Hadoop 环境,使用 Standalone 模式的。比如在云上,Hadoop 一般会使用对应的服务,比如 AWS 的 EMR,一方面是费用较高,另一方面是较为笨重,没那么灵活。用 Standalone 模式只需要起几台机器,安装好 Spark 就可以了。
目前大多数还是本地环境,相信学会了 yarn-cluster 模式,其他的你也都会了。
这是以 yarn-cluster 模式提交一个 Spark 任务最简单的命令,计算 Pi(π) 的值。

通过 --master 参数以及 --deploy-mode 指定为 yarn-cluster 模式,Driver 将运行在 Yarn 中。
下面则是提交 Spark 作业的流程。
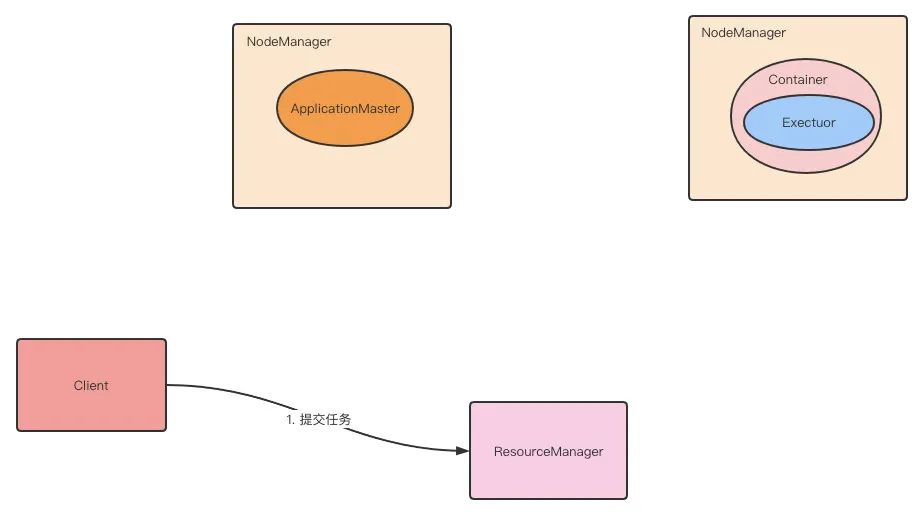
第 1 步:Client 提交 Application 到 ResourceManager。
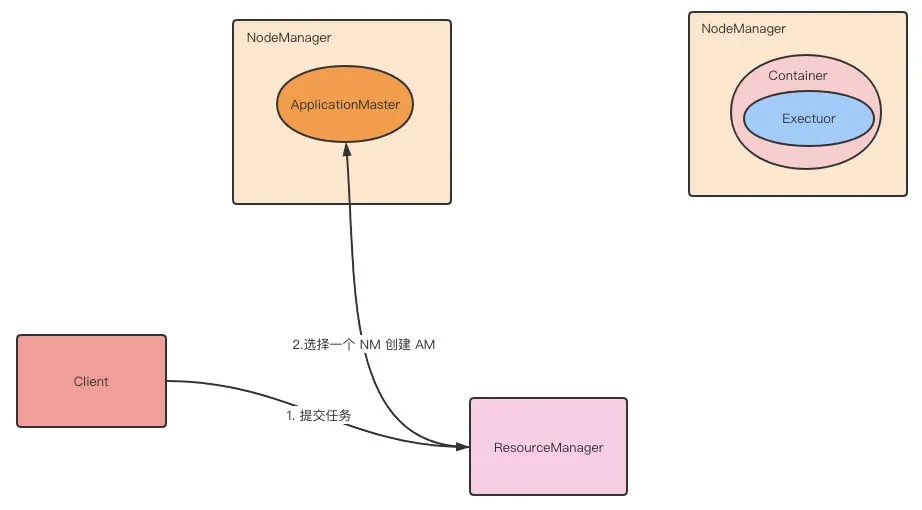
第 2 步:ResourceManager 分配 container,在对应的 NodeManager 上启动 ApplicationMaster,ApplicationMaster 会再启动 Driver。
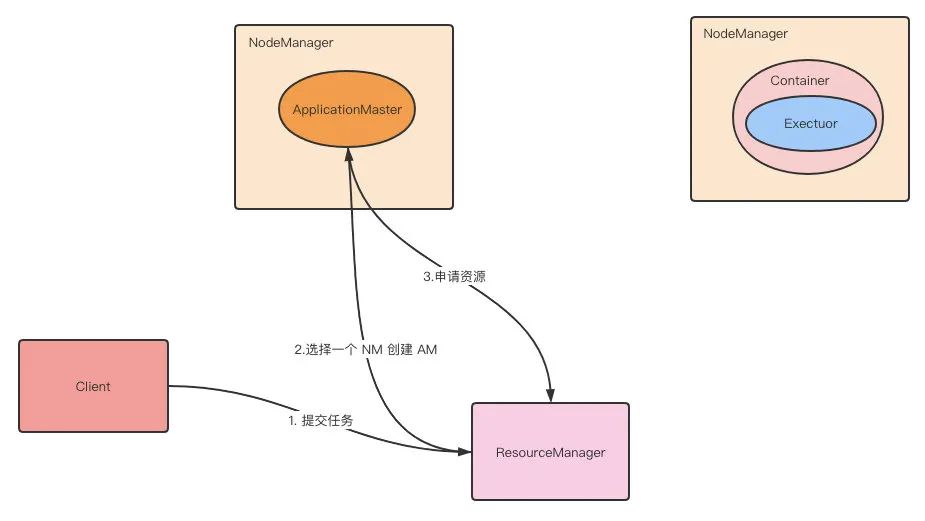
第 3 步:Driver 向 ResourceManager 申请 Executor。
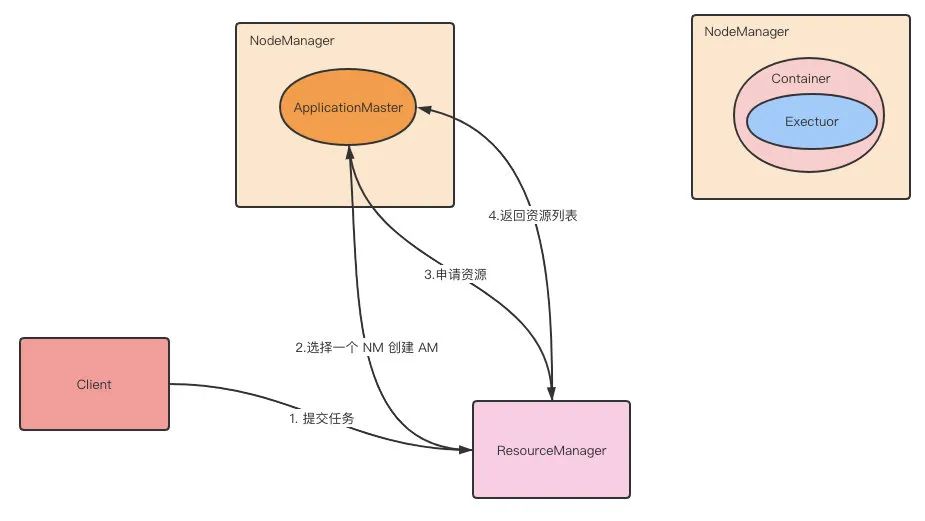
第 4 步:ResourceManager 返回 Container 给 Driver。
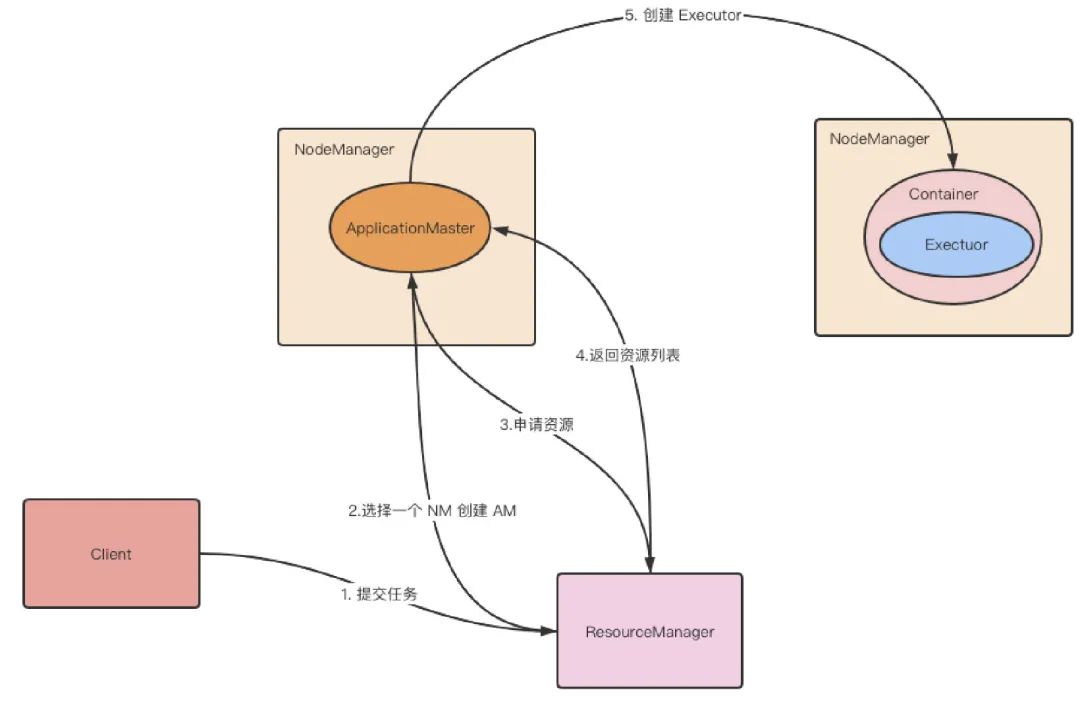
第 5 步:Driver 在对应的 Container 上启动 Executor。
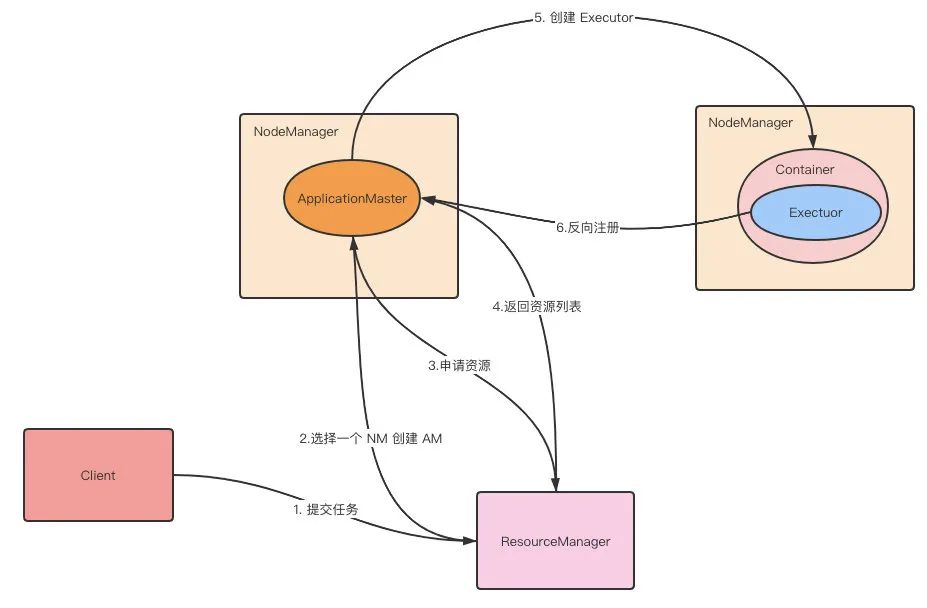
第 6 步:Executor 向 Driver 反向注册。
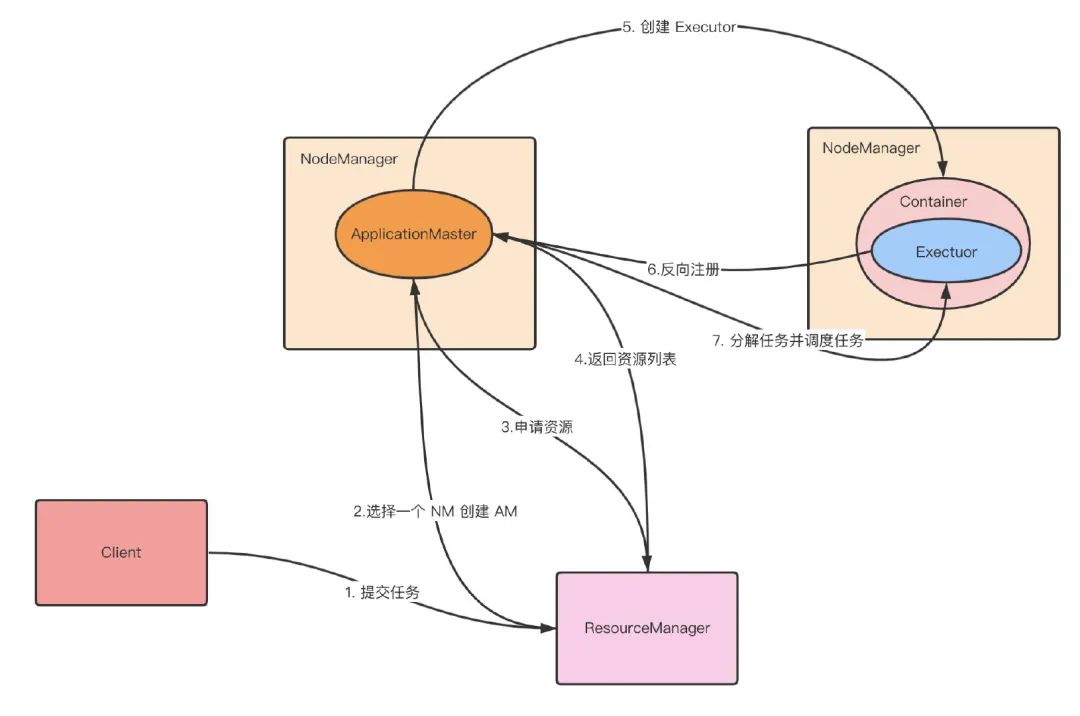
第 7 步:Executor 全部注册完,Driver 开始执行 main 函数。
第 8 步:Driver 执行函数时,遇到 action 算子就会触发一个 job,根据宽依赖划分 stage,每个 stage 生成 taskSet,将 task 分发到 Executor 上执行。
第 9 步:Executor 会不断与 Driver 通信,报告任务运行的情况。
看完这个也许你感觉自己学会了,但如果不去实践,过一段时间还是会忘记,所以赶快去面试吧。
·················END·················
你好,我是峰哥,一个骚气的肌肉男。独自穷游过15个国家,60座城市,也是国家级健身教练。
二本车辆工程转型大数据开发,拿过66个大数据offer,现任某知名外企高级数据工程师。
毕业一年,靠自己在上海买房,点此看我2020年总结。为人亲和,欢迎添加我的微信 Fawn0504 进行交流或围观朋友圈。