
HTTP 缓存别再乱用了!推荐一个缓存设置的最佳姿势!
大家好,我是 ConardLi,我又来给大家解读浏览器策略了,这次是缓存相关的。
设置缓存大家可能大家都是从性能角度去考虑的,但是如果你不注意或者稍微设置不当,缓存也可能对我们的网站的安全性和用户隐私造成负面影响。
开门见山
老规矩,先把推荐的配置说出来,后面再啰嗦:
为了防止中介缓存,建议设置: Cache-Control: private建议设置适当的二级缓存 key:如果我们请求的响应是跟请求的 Cookie相关的,建议设置:Vary: Cookie
那么为啥推荐这两个配置呢?如果不配置会对我们的网站带来什么风险呢?且听我下面的讲解。
回顾 HTTP 缓存
提到缓存,大家可能很快就会想到两种缓存方式,以及对应的几个请求头,我们来快速回顾一下。
正常情况下,我们的浏览器客户端会像服务器发起请求,然后服务器会将数据响应返回给客户端。

但是一台服务器可能要对成千上万台客户端的请求进行响应,其中也有非常多是重复的请求,这会对服务器造成非常大的压力。
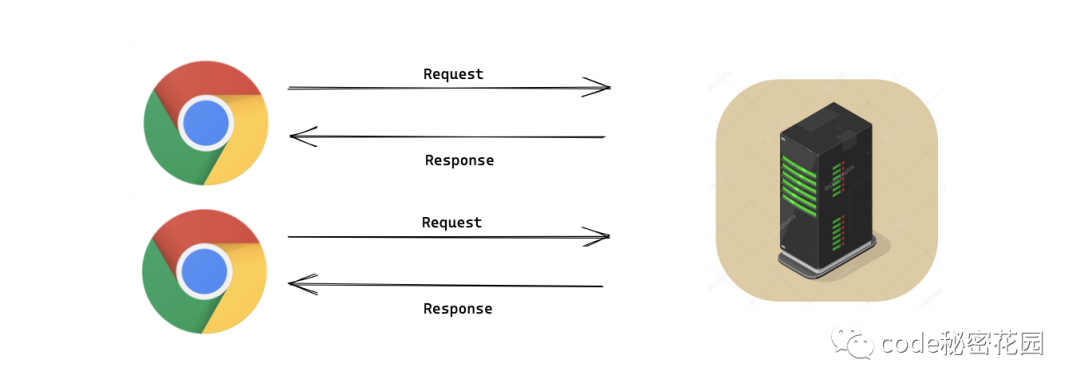
所以一般我们都会在客户端和服务器间进行一些缓存,对于一些重复的请求数据,如果之前的响应已经被存储到缓存数据库中,满足一定条件的话就会直接去缓存中取,不会到达服务器。
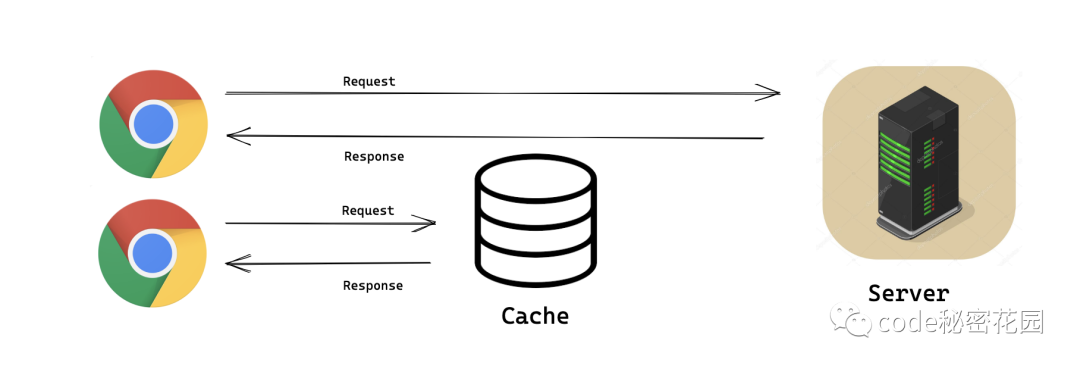
那么,HTTP 缓存一般又分为两种,强缓存和协商缓存:
强缓存
强缓存,在缓存数据未失效的情况下,客户端可以直接使用缓存数据,不用和数据库进行交互。
那么,判断请求是否失效主要靠两个 HTTP Header:
Expires:数据的缓存到期时间,下一次请求时,请求时间小于服务端返回的到期时间,直接使用缓存数据。Cache-Control:可以指定一个max-age字段,表示缓存的内容将在一定时间后失效。
协商缓存
协商缓存,顾名思义需要和服务器进行一次协商。浏览器第一次请求时,服务器会将缓存标识与数据一起返回给客户端,客户端将二者备份至缓存数据库中。
再次请求数据时,客户端将备份的缓存标识发送给服务器,服务器根据缓存标识进行判断,判断成功后,返回 304 状态码,通知客户端比较成功,可以使用缓存数据。
判断请求主要靠下面两组 HTTP Header:
Last-Modified:一个Response Header,服务器在响应请求时,告诉浏览器资源的最后修改时间。if-Modified-Since:一个Request Header,再次请求服务器时,通过此字段通知服务器上次请求时,服务器返回的资源最后修改时间。
服务器会通过收到的 If-Modified-Since 和资源的最后修改时间进行比对,判断是否使用缓存。
Etag:一个Response Header,服务器返回的资源的唯一标示If-None-Match:一个Request Header,再次请求服务器时,通过此字段通知服务器客户段缓存数据的唯一标识。
服务器会通过收到的 If-None-Match 和资源的唯一标识进行对比,判断是否使用缓存。
关于缓存的常见误区
上面提到的知识估计就是平时大家最常背到的,不过大家有没有认真想过一个问题?我们取到的缓存数据,一定缓存在浏览器里面吗?
实际上是不然的:资源的缓存通常是有多级的,一些缓存专门用于单个用户,一些缓存专用于多个用户。有些是由服务器控制的,有些是由用户控制的,有些则由中介层控制。

浏览器缓存:一般并专用于单个用户,在浏览器客户端中实现。它们通过避免多次获取相同的响应来提高性能。 本地代理:可能是用户自己安装的,也可能是由某个中介层管理的:比如公司的网络层或者网络提供商。本地代理通常会为多个用户缓存单个响应,这就构成了一种“公共”缓存。 源服务器缓存/CDN。由服务器控制,源服务器缓存的目标是通过为多个用户缓存相同的响应来减少源服务器的负载。CDN 的目标是相似的,但它分布在全球各个地区,然后通过分配给最近的一组用户来达到减少延迟的目的。
另外,我们也经常会使用本地配置的代理,这些代理能够通过配置信任证书来缓存 HTTPS 资源。
Spectre 漏洞
那么缓存怎么会对我们网站的安全性和用户隐私造成威胁呢?我们来看一个非常有名的漏洞:Spectre。

攻击者可以利用 Spectre 漏洞 来读取操作系统进程的内存,这意味着可以访问到未经过授权的跨域数据。
特别是在使用一些需要和计算机硬件进行交互的 API 时:
SharedArrayBuffer (required for WebAssembly Threads)performance.measureMemory()JS Self-Profiling API
为此,浏览器一度禁用了 SharedArrayBuffer 等高风险的 API。
这个漏洞其实在我之前的多个文章中都有提到过,其实浏览器出过的很多安全策略都和它有关:
很多小伙伴对它具体的攻击原理感兴趣,通过几个 JavaScript API 怎么做到越权访问数据的?这个下次我会专门出个文章来讲一下。
缓存是怎么影响 Spectre 的?
那么 Spectre 和缓存有啥关系呢?我们可以简单的这样理解下:
我们正常打开一个收到跨域限制的页面,肯定是获取不到数据的。但是如果我们的 Cache-Control 设置为了 Public,这份数据可能会被缓存到一个 Public Cache 上(比如我们本地代理的 Cache)。
虽然我们是没有权限访问这个数据的,但是数据却被存到缓存数据库里了。一旦数据已经被存下来了,攻击者就可以利用 Spectre 漏洞获取到这些缓存数据了。
那么为啥利用 Spectre 可以越权访问到这些缓存数据呢?我们来举个简单的小例子:
比如,我们有个网站的登录密码是 conardli,一个攻击者想要爆破我们的密码,假设我们的密码一定由小写字母组成,那攻击者也至少需要 26 的 8 次方次来猜出我们的密码。这是一个非常大的数字,几乎不可能爆破成功。
假设,我们的密码存在了一块攻击者无权限访问到的内存里,然后攻击者自己又单独使用一块内存存储了所有的26个英文字母,并把这段内存设置为不可缓存。

那么这个时候,攻击者越界访问了我们密码的存储区域,访问到了 c 这个字母,但是由于权限问题,他肯定是访问不到的,会被计算机拒绝。
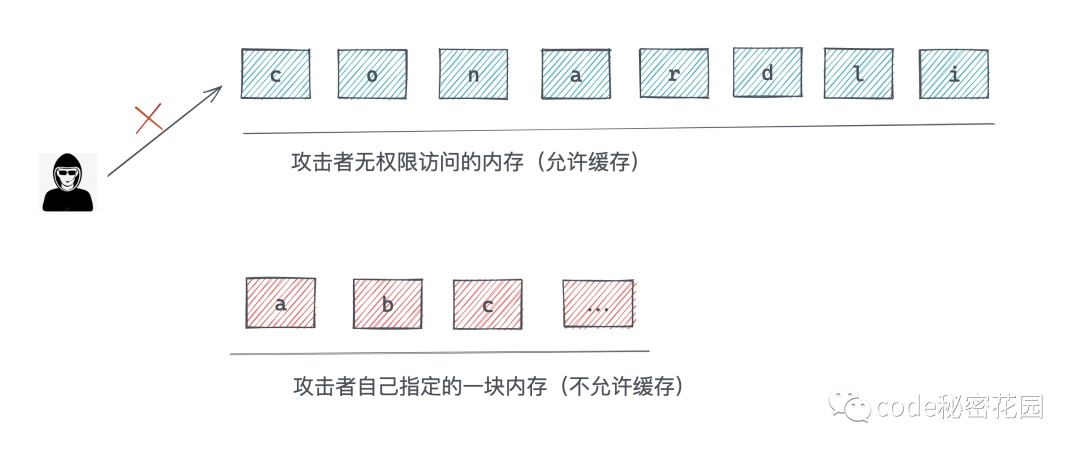
但是虽然访问不到,c 这个字母会被缓存起来。
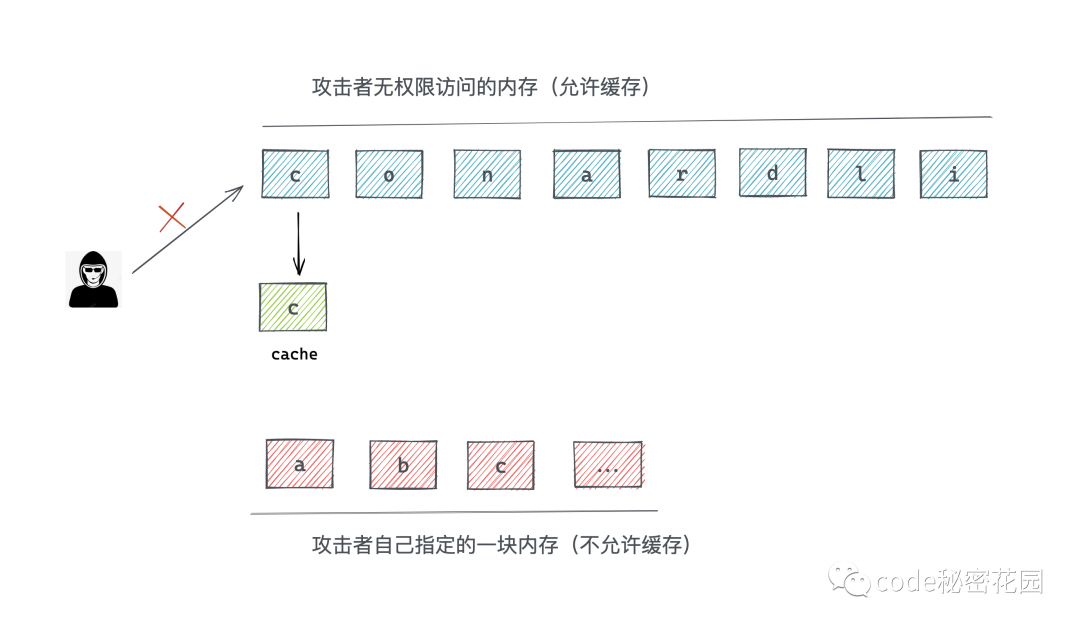
这时,攻击者再回去遍历他那 26 个字母的内存,会发现,c 的访问速度变快了 ...

所以,你的密码第一个数字是 c ...
这里就简单讲一下,下篇文章我会专门来讲一下 Spectre 漏洞,还是非常巧妙的 ... 感兴趣的小伙伴可以再留言区告诉我。
网站的建议配置
因为上面的问题,我们建议对所有比较重要的网站数据做下面的两个配置:
禁用 Public Cache
设置 Cache-Control: private,这可以禁用掉所有 Public Cache(比如代理),这就减少了攻击者跨界访问到公共内存的可能性。
这里注意,private 这个值并不是一个独立的值,比如他是可以和 max-age 进行共存的,性能和 public 差不了多少,我们打开 Google 的网站来看一下:

设置适当的二级缓存 key
默认情况下,我们浏览器的缓存使用 URL 和 请求方法来做缓存 key 的。
这意味着,如果一个网站需要登录,不同用户的请求由于它们的请求URL和方法相同,数据会被缓存到一块内存里。
这显然是有点问题,我们可以通过设置 Vary: Cookie 来避免这个问题。
当用户身份信息发生变化的时候,缓存的内存也会发生变化。
当然,如果你的资源是一个大家都可以访问的公共 CDN 资源,那你的缓存当然是随便设置了,如果你的资源数据是比较敏感的,建议走上面这两个设置。
参考
https://web.dev/http-cache-security/ https://zhuanlan.zhihu.com/p/32784852 https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Vary
最后
大家有在业务里设置过缓存吗?都是怎么设置的呢?有考虑过这个问题吗?欢迎在留言区告诉我。
往期推荐

解密初、中、高级程序员的进化之路(前端)

程序员一定会有35岁危机吗?

近 20k Star的项目说不做就不做了,但总结的内容值得借鉴

但凡早知道这28个网站,都不至于学得那么不扎实
如果你觉得这篇内容对你挺有启发,我想邀请你帮我三个小忙:
点个「在看」,让更多的人也能看到这篇内容(喜欢不点在看,都是耍流氓 -_-)
欢迎加我微信「huab119」拉你进技术群,长期交流学习...
关注公众号「前端劝退师」,持续为你推送精选好文,也可以加我为好友,随时聊骚。

如果觉得这篇文章还不错,来个【转发、收藏、在看】三连吧,让更多的人也看到~
