
从Go文本文件到可执行文件
Go 是一门编译型语言,我们平时所编写的 *.go 文本文件称为源文件,源文件里面的内容就是我们的源代码。
源代码要想在目标机器上运行,就必须使用 Go compiler (缩写 gc ,指代 Go 编译器)将其先编译成操作系统能够直接识别的二进制机器码文件,或说可执行文件。后续由操作系统加载该文件,并在 CPU 中直接运行机器码。这也是编译型语言运行效率高的主要原因。
Go compiler 是用什么实现的
编译器本身也是一个程序,它的作用就是把一个以某种语言(源语言)编写的程序 翻译 成等价的另一个语言(目标语言)编写的程序。
而编译器这个程序本身的编写与编程语言是没有关系的,任何一种图灵完备的语言都可以编写任何一种形式语言的编译器。
最开始的 Go compiler (Go 1.4 以及之前)是由 C 和汇编共同编写的,等到 2015 年时 Google 开始公布实现 Go 1.5 自举的计划[1]。
首先使用 Go 语言编写一个和之前用 C 语言编写的 Go compiler 一样功能的程序出来,再用之前用 C 语言实现好的 Go compiler 来编译这个新写的程序,这样就得到一个用 Go 语言实现的 Go compiler 。后续的 Go 程序就都可以直接使用这个新的用 Go 语言实现的 Go compiler 来编译了。
这种用源语言自身来实现源语言的编译器的做法就叫自举。所以在 Go 1.5 及之后的 Go compiler 就是用 Go 语言自身实现的了。
一个编译器的结构
如果我们把编译器这个黑盒稍微打开,根据完成的任务不同,可以将编译器的组成部分划分为前端(Front End)与后端(Back End)。
编译前端负责分析(analysis)部分,把源程序分解为多个组成要素,并在这些要素之上加上语法结构,然后利用这个结构创建出源程序的中间表示形式,最后还将源程序的信息存放在一个称为符号表的数据结构中并与中间表示形式一起传送给综合部分。
可见,如果我们编写了一段语法错误的代码,在前端就会被拦截下并给予提示了。这和我们 Web 开发中的参数校验部分也有一点相似之处。
前端工作结束,则来到编译后端,后端则负责综合(synthesis)部分,根据前端传送过来的中间表示和符号表中的信息来构造用户期待的目标程序。
在编译前端和后端之间,往往还存在着多个可选的、与机器无关的优化步骤,负责将中间表示形式进一步优化转换,以便后续后端可以生成出更好的目标程序。
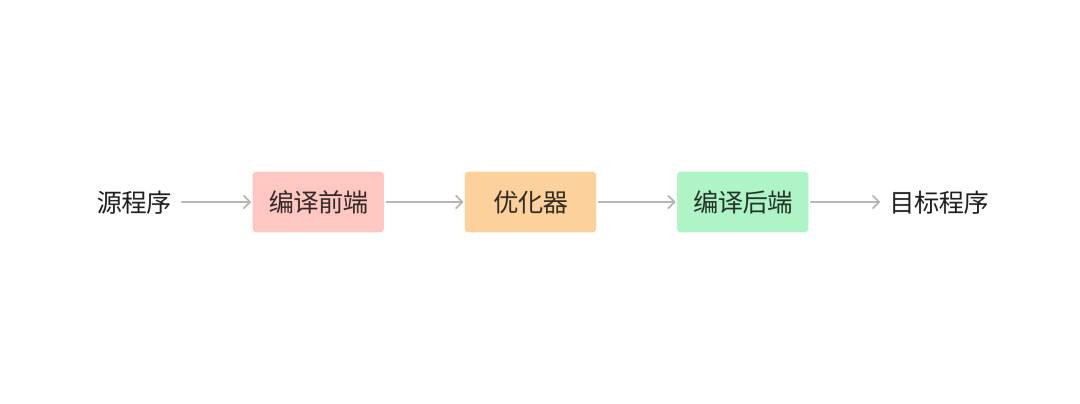
Go compiler 的多阶段流程
以当前最新的稳定版本 Go 1.18.4 为例,Go compiler 的源码位置在:https://github.com/golang/go/tree/go1.18.4/src/cmd/compile
后续的所有代码示例和源码引用也是基于此版本。
我们将编译器的结构对应到 Go compiler 上,也可以将 Go compiler 的各阶段流程划分为编译前端和编译后端(优化器部分也放在了编译后端)。
其中 Go compiler 的前端包括:词法分析、语法分析、类型检查。
后端包括:中间代码生成、代码优化、Walk 遍历和替换、通用 SSA 生成、机器码生成。
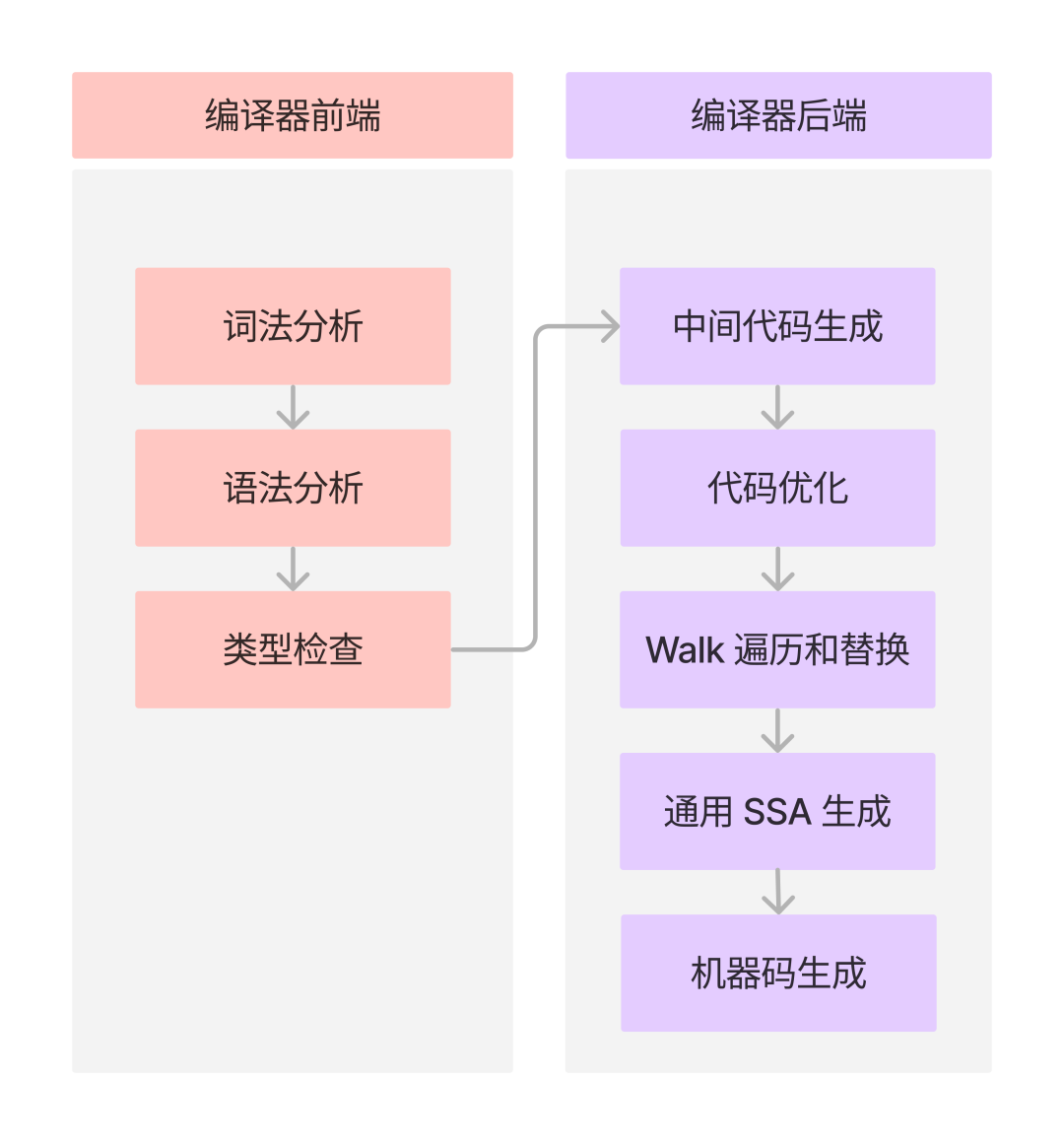
词法分析
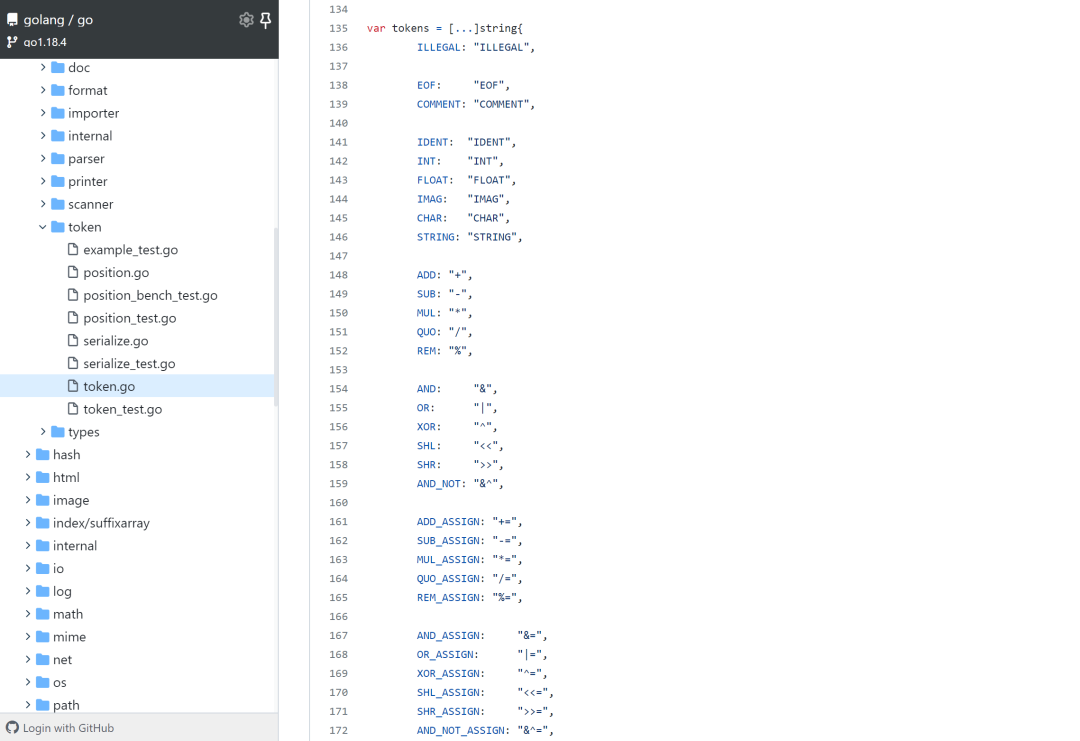
编译器的第一个步骤称为词法分析(lexical analysis)或扫描(scanning)。对应的源码位置在 cmd/compile/internal/syntax/scanner.go 。其作用便是把我们的源代码“翻译”为词法单元 token 。
token 在 go/token/token.go 中被定义为了一种枚举值,实质就是用 iota 声明的整数,好处便是在后续的操作中可以被更加高效地处理。
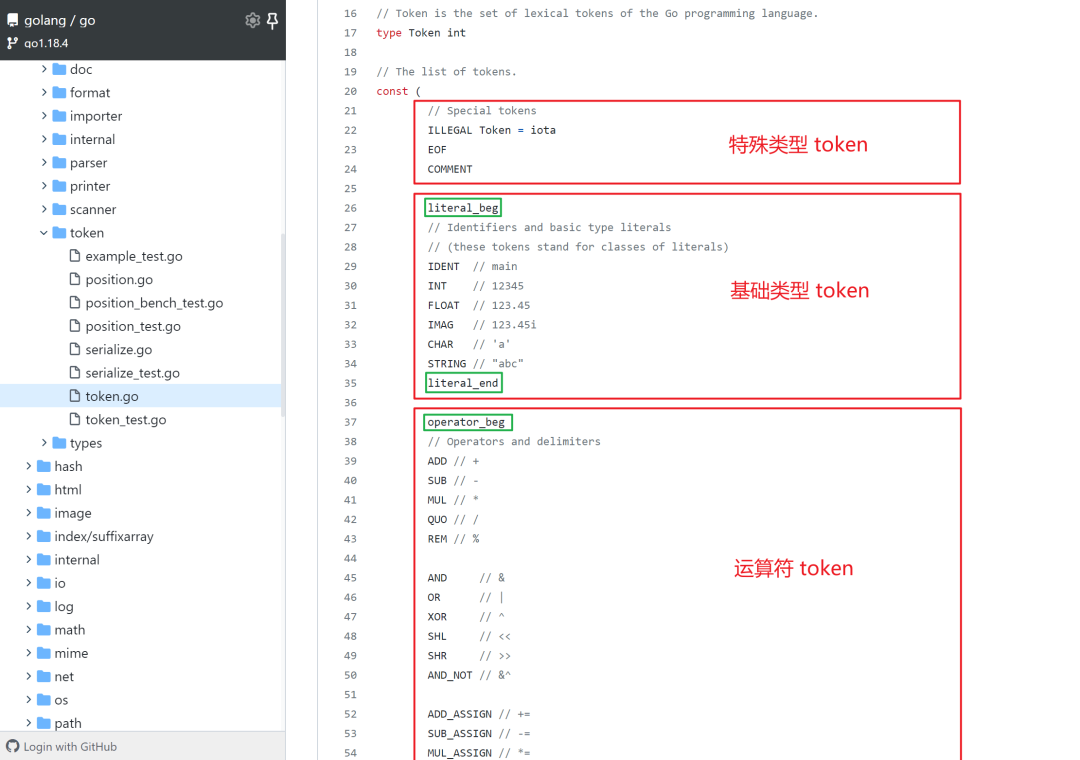
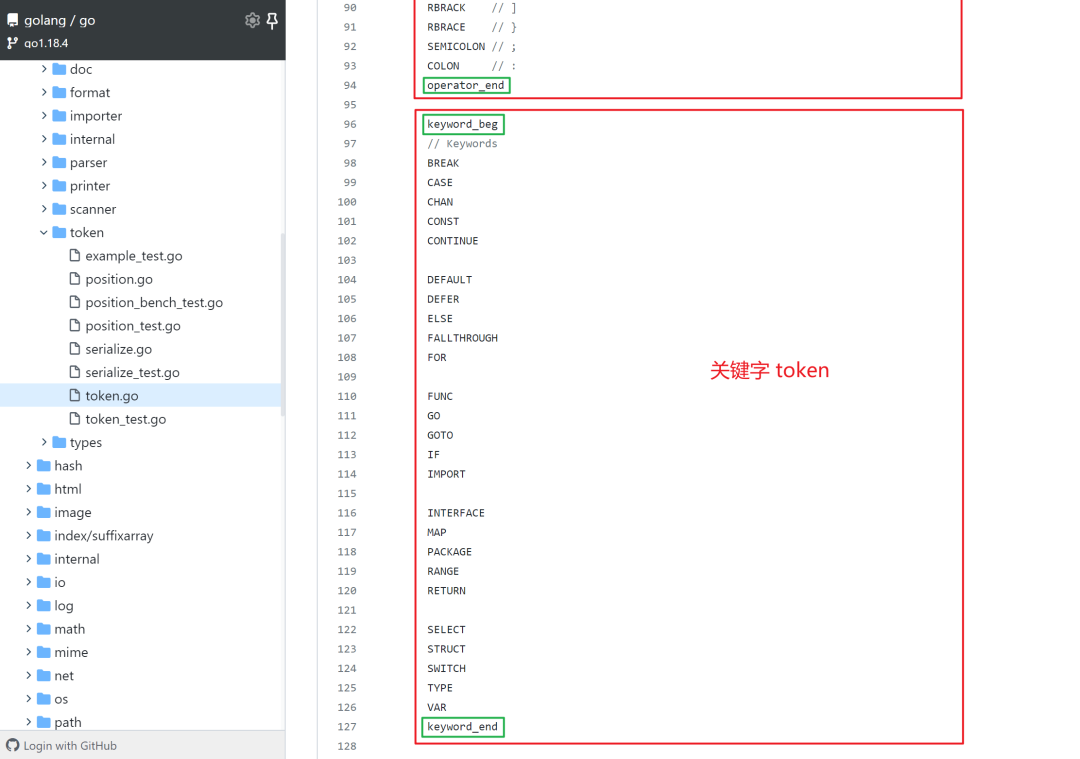
所有的 token 主要被分为四类:特殊类型、基础类型、运算符和关键字。
若存在词法错误,将统一返回 ILLEGAL ,简化词法分析时的错误处理。
其中以 _beg 和 _end 为后缀的私有常量,用来表示 token 的值域范围。
最后所有的 token 都会被放进一个 var tokens = [...]string 数组中,做了一个下标(token 值)和 token 面值的映射。
值得一提的是,词法分析除了在编译器中使用,在 go 标准库 go/scanner 中也提供了出来,我们可以用来测试看看一段源代码翻译成 token 后的样子。
package main
import (
"fmt"
"go/scanner"
"go/token"
)
func main() {
// 需要翻译的源程序
src := []byte(`package main
import "fmt"
func main() {
fmt.Println(1 + 1)
}
`)
// 初始化 scanner.
var s scanner.Scanner
fset := token.NewFileSet()
file := fset.AddFile("", fset.Base(), len(src))
s.Init(file, src, nil, scanner.ScanComments)
// 不断地扫描并输出翻译成 token 的结果
fmt.Printf("%s\t%s\t%s\n", "行列", "token符号", "对应的原词")
for {
pos, tok, lit := s.Scan()
if tok == token.EOF {
break
}
fmt.Printf("%s\t%s\t%q\n", fset.Position(pos), tok, lit)
}
}
翻译成 token 后的输出结果如下:
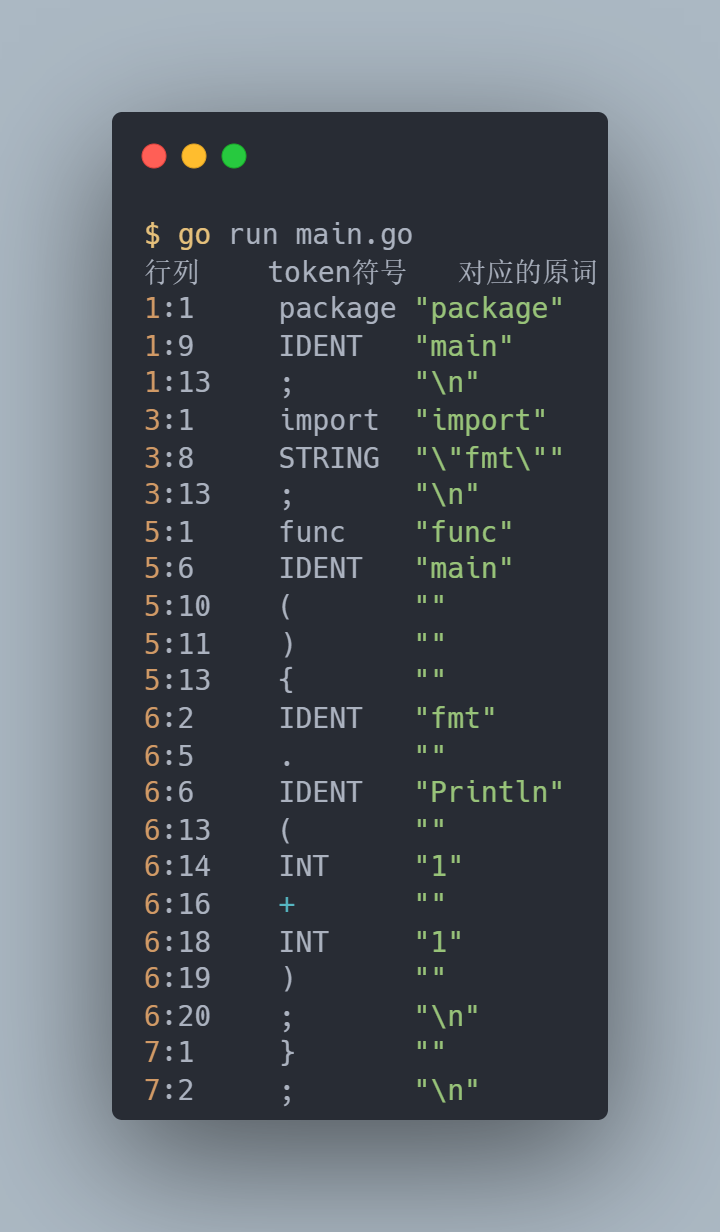
有个小细节的地方:当遇到 \n 换行符时,会翻译成一个 ; 分号,这也是 Go 语言为什么不需要 ; 结尾。
语法分析
编译器的第二个步骤称为语法分析(syntax analysis)或解析(parsing)。语法分析将把第一步骤的 token 转化成使用 AST 抽象语法树(abstract syntax tree)来表示的程序语法结构。
语法分析的源码位于 cmd/compile/internal/syntax/parser.go 。我们同样可以借助标准库 go/parser 来进行测试。
package main
import (
"go/ast"
"go/parser"
"go/token"
)
func main() {
// 需要翻译的源程序
src := `package main
import "fmt"
func main() {
fmt.Println(1 + 1)
}
`
fset := token.NewFileSet()
f, err := parser.ParseFile(fset, "", src, 0)
if err != nil {
panic(err)
}
err = ast.Print(fset, f)
if err != nil {
panic(err)
}
}
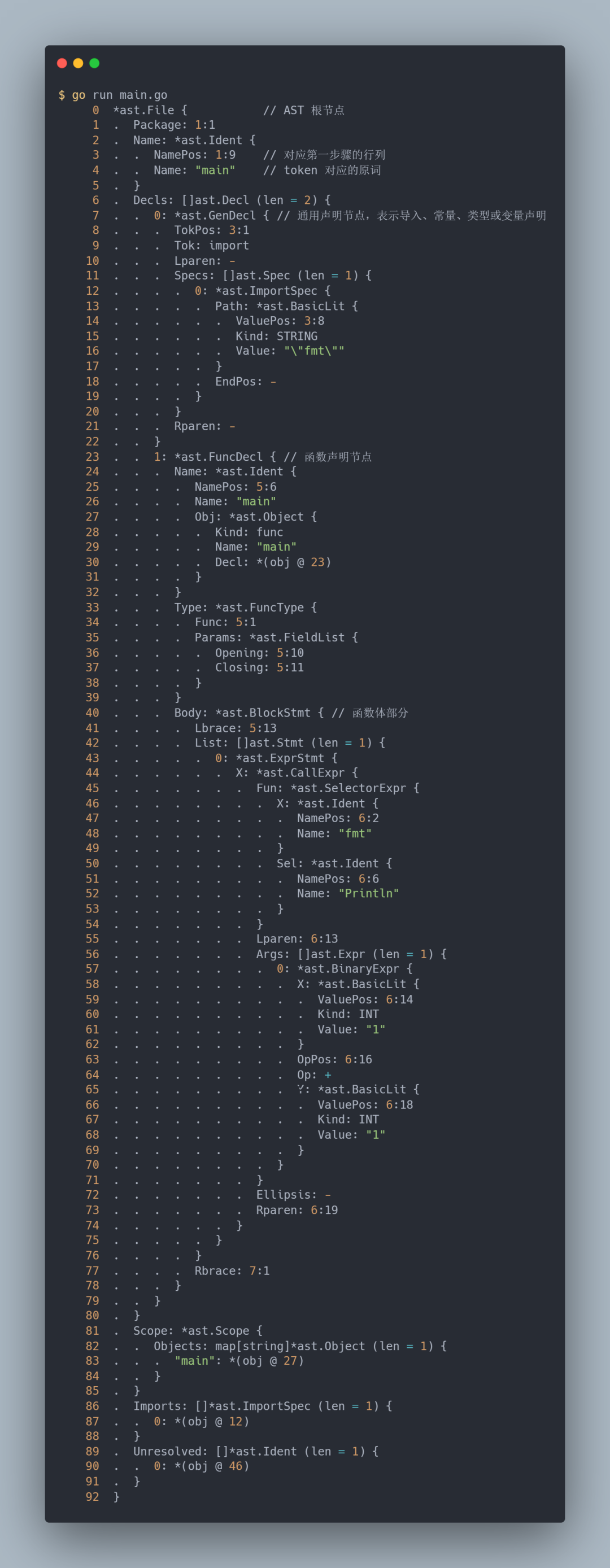
经过语法分析构建出来的每个语法树都是相应源文件的精确表示,其节点对应于源文件的各种元素,例如表达式、声明和语句。并且语法树还会包括位置信息,用于错误报告和创建调试信息。
到目前阶段为止,都还只是对源代码进行字符串层面的处理。从源代码到 token 再到 AST 。
类型检查
在编译原理中,完成 AST 的构建,就会来到语义分析(semantic analyzer)阶段,主要包括类型检查(type checking)和自动类型转换(coercion)。
而在 Go compiler 中,这一阶段被直接合称为类型检查,其源码定义在 cmd/compile/internal/types2 。
在此阶段,类型检查会遍历 AST 的节点,对每个节点的类型进行检查,比如检查每个运算符是否具有匹配的运算分量,数组的下标是否正整数等等。另外类型检查阶段也会进行类型推导,例如使用简短变量声明 i := 1 ,会自动推导出变量 i 的类型是 int。
总之,对类型系统的处理都是类型检查阶段完成的。
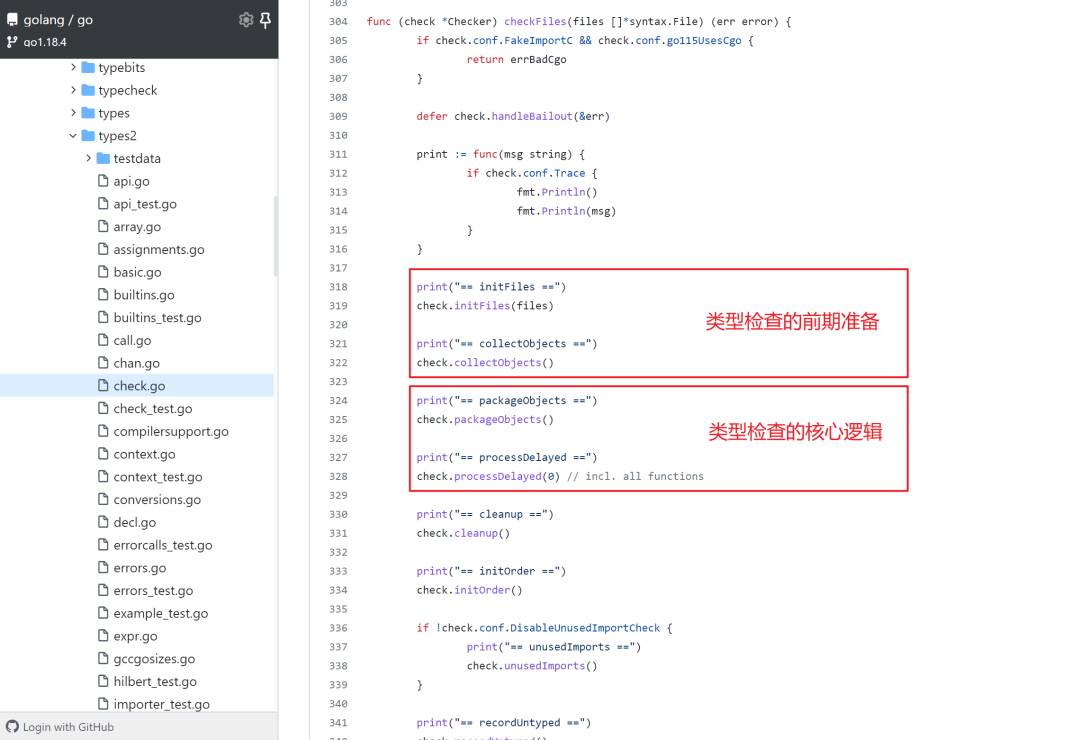
类型检查的总体流程可以查看 cmd/compile/internal/types2/check.go :
中间代码生成
一旦类型检查阶段完成,意味着编译前端工作完成,到这里代码已经没有语法错误的问题了。按理是可以直接翻译成机器码了,但是在此之前,还需要先翻译成介于源代码和目标机器码中间的中间代码(IR, Intermediate Representation)。
使用中间代码来衔接前、后端的好处很大。因为中间代码不会包含与任何源代码相关的信息,也不会包含与特定目标机器相关的信息,我们可以基于中间代码来进行一些和机器无关的优化工作。
另外,有了中间代码,后端编译还可以得到复用,比如我现在想要创建一门新的语言,只需要编写编译器前端,构造出相同的中间代码,编译器后端就可以直接使用现成的了,不必重复构建。
其实这种做法就是平时我们程序设计常提到的解耦。
回到中间代码生成本身,在这一阶段中,会基于前面构造出的 AST 再生成一颗 IR Tree 。
因为我们是基于 Go 1.18.4 来分析,Go Team 在此已经增加了许多新的语言特性(包括泛型),以往的很多模块也被重新重构,代码结构更加清晰。但是难免还会关联到之前一些旧版本的包(在之前 IR Tree 的生成与类型检查是同时完成的)。
在 IR 生成阶段,主要会涉及以下几个目录:
cmd/compile/internal/typescmd/compile/internal/ircmd/compile/internal/typecheckcmd/compile/internal/noder
IR 生成的入口位置在 cmd/compile/internal/noder/irgen.go :
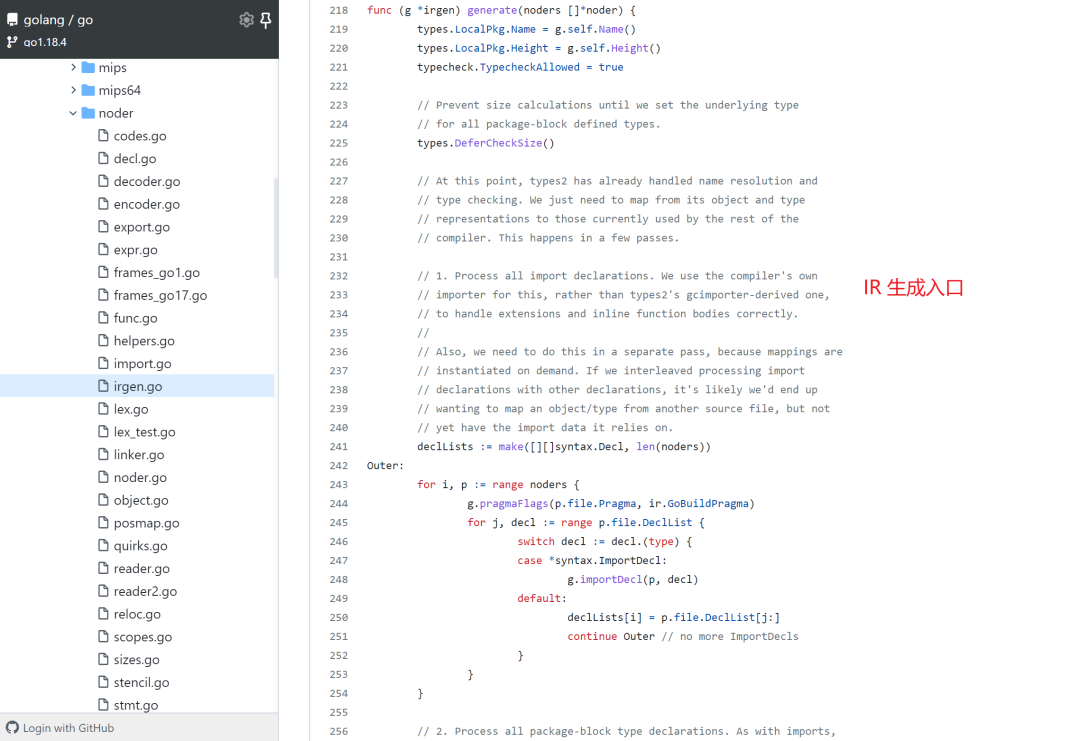
func (g *irgen) generate(noders []*noder) 中的参数 noders 就是类型检查的输出结果 AST 。
到这里我们小结一下,编译前端完成了 源代码 -> token -> AST 的翻译工作,而现在的中间代码生成阶段完成了 AST -> 基于 AST 的 IR Tree 的翻译工作。所以为什么说编译器的工作就是在翻译。
代码优化
终于来到了代码优化,这个阶段可谓是八股文的重灾区。即使不懂编译流程,也听过了这些名词:死代码消除(dead code elimination)、函数内联(function call inlining)、逃逸分析(escape analysis)。
以上这些便是对 IR 的进一步优化过程。其源码位置分别在:
cmd/compile/internal/deadcodecmd/compile/internal/inlinecmd/compile/internal/escape
代码优化的目的就是让代码的执行效率更高,例如可能存在一些代码,虽然具备语义上的价值,但程序在运行时可能永远不会执行到,死代码消除就会去除这些无用代码(就像 if 里的条件为 true )。
如果程序中存在大量的小函数的调用,函数内联就会直接用函数体替换掉函数调用来减少因为函数调用而造成的额外上下文切换开销。
最后逃逸分析可以判断变量应该使用栈内存还是堆内存,为 Go 的自动内存管理奠定基础。
Walk 遍历和替换
经历过代码优化的 IR ,将迎来它生命旅游的最后一站:Walk ,源码在 cmd/compile/internal/walk。
Walk 会遍历函数把复杂的语句分解为单独的、更简单的语句,并且还可能会引入临时变量来对某些表达式和语句进行重新排序。还会将高层次的 Go 结构替换为更原始的结构。
例如, n += 2 将被替换为 n = n + 2 ;switch 选择分支将替换为二分查找或跳转表;map 和 chan 的 make 操作将替换为运行时调用的 makemap 和 makechan 等。
通用 SSA 生成
Walk 是基于 AST 的 IR 的最后一程,意味着来到这里,又要再次翻译了。
而这次 IR 将被转换为静态单赋值(SSA)(Static Single Assignment)形式,这是一种具有特定属性的较低级别的中间表示,可以更轻松地实现优化并最终生成机器代码。
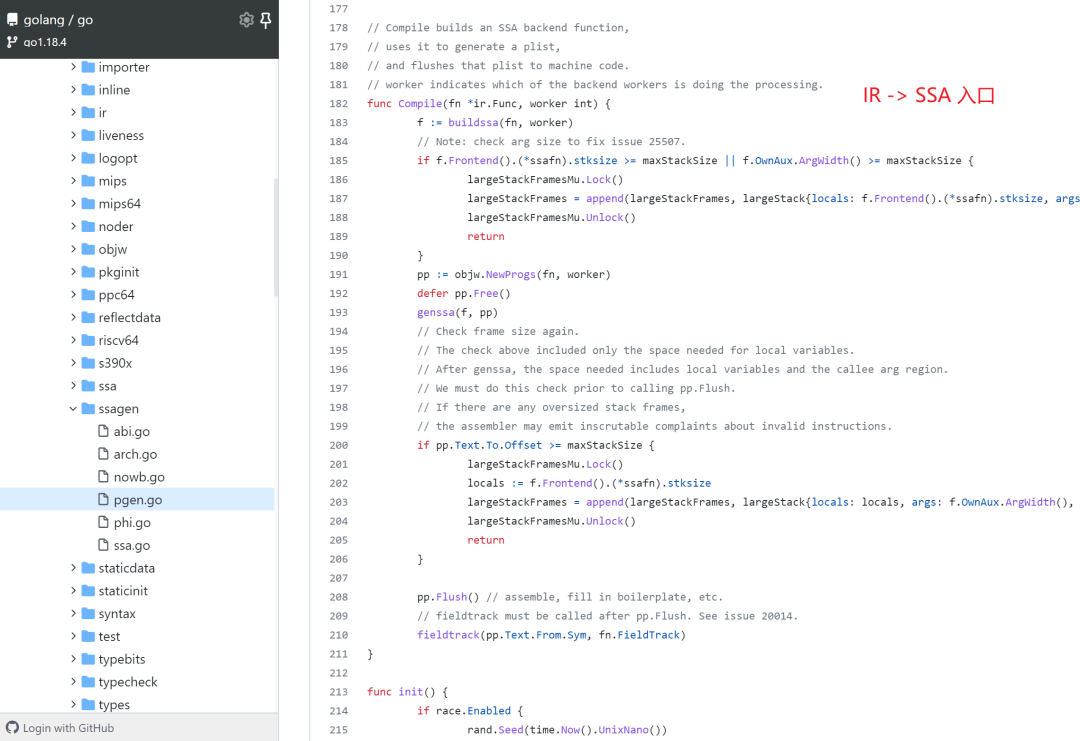
SSA 的规则定义在:cmd/compile/internal/ssa ,而 IR 转换为 SSA 的代码位于:cmd/compile/internal/ssagen 。
其翻译的入口在 func Compile(fn *ir.Func, worker int) 函数。
我们可以通过在编译过程加上 GOSSAFUNC=函数名 环境变量来查看 SSA 的生成过程。
还是以这段代码为例:
package main
import "fmt"
func main() {
fmt.Println(1 + 1)
}
$ GOSSAFUNC=main go build hello.go
# runtime
dumped SSA to D:\Project\GoProject\awesome\ssa.html
# command-line-arguments
dumped SSA to .\ssa.html
根据提示,会生成 ssa.html 文件:

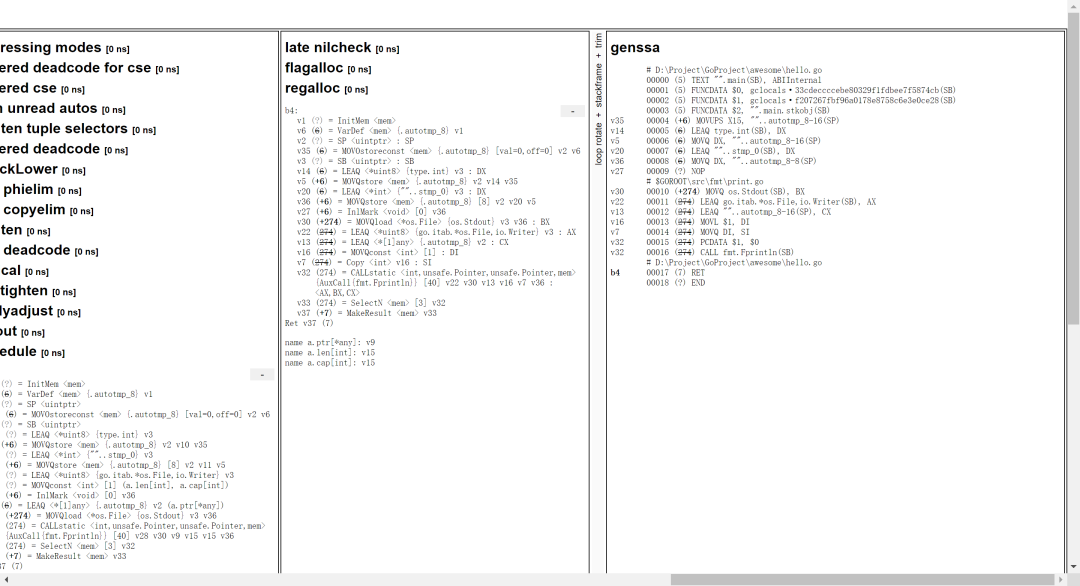
可以从中看到 SSA 为了尽最大可能地提升执行效率,会经历 多轮转换 后才生成最终的 SSA 。
机器码生成
来到最后一步,也是从 .go 文本文件到可执行文件的最终谜团,把 SSA 翻译成特定目标机器(目标 CPU 架构)的机器码。
首先需要把 SSA 降级(lower),针对具体目标架构,进行 多轮转换 来执行代码优化,包括死代码消除(和之前的代码优化中的不同)、将数值移到离它们的用途更近的地方、删除多余局部变量、寄存器分配等等。
这个降级操作最后的结果,其实就是我们上面的 ssa.html 文件最后的 genssa :
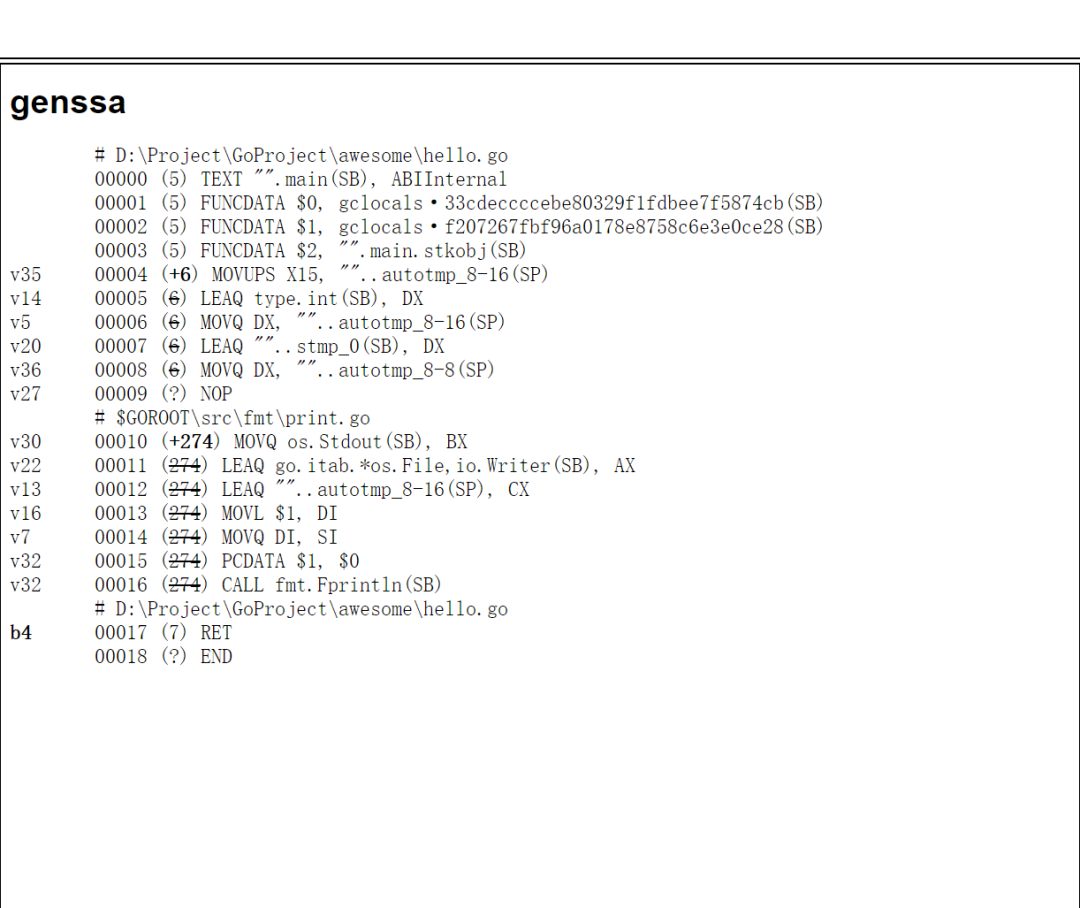
把 SSA 多轮转换得到了 genssa 之后(此时已经很接近汇编了),会先继续把 genssa 翻译成汇编代码(Plan9),然后才调用汇编器(cmd/internal/obj)将它们转换为机器代码并写出最终的目标文件。目标文件中还会包含着反射数据、导出数据和调试信息。这一步就需要十分了解 CPU 指令集架构了。
最后程序如果使用了其他程序或库,还需要使用静态链接或动态链接引用进来。在没有使用 CGO 时,Go 默认会使用静态链接,当然也可以在 go build 时指定。
最后
编译原理是一门十分复杂的系统,每一个阶段单独拎出来,其涉及的知识体系都够吓人的了。。。
本文也只是蜻蜓点水般的过一遍,关于其中的一些细节我也并不太清楚,但是也让我明白了一点道理:不管是多复杂多底层的系统,也都是通过分层来解耦、复用,并且也是不断迭代优化来完成的。
另外,知道了 Go 语言编译过程中的代码优化,也能让我们在平时的代码编写中结合对应的特性编写出更加高性能的代码,例如尽量在栈上分配对象,减少变量逃逸到堆上也可以提高 GC 效率等。这些后面再单独写篇文章来介绍。
本文部分内容参考自经典龙书《编译原理》以及《Golang 编译器代码浅析》[2] ,如果想要了解更多编译领域的知识,推荐大家进行阅读。
对于最后机器码生成中提到的 Plan9 汇编可以阅读曹大的《plan9 assembly 完全解析》[3]。
参考资料
Google 公布实现 Go 1.5 自举的计划: https://docs.google.com/document/d/1OaatvGhEAq7VseQ9kkavxKNAfepWy2yhPUBs96FGV28/edit
[2]《Golang 编译器代码浅析》: https://gocompiler.shizhz.me/
[3]《plan9 assembly 完全解析》: https://go.xargin.com/docs/assembly/assembly/
推荐阅读