
为什么爬虫工程师应该有一些基本的后端常识?
共 7237字,需浏览 15分钟
·
2021-06-25 02:23
今天在交流群里面,有个同学说他发现了Requests的一个 bug,并修复了它:
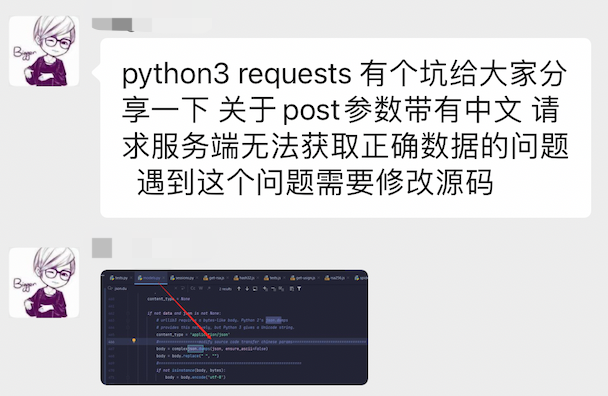
聊天记录中对应的图片为:
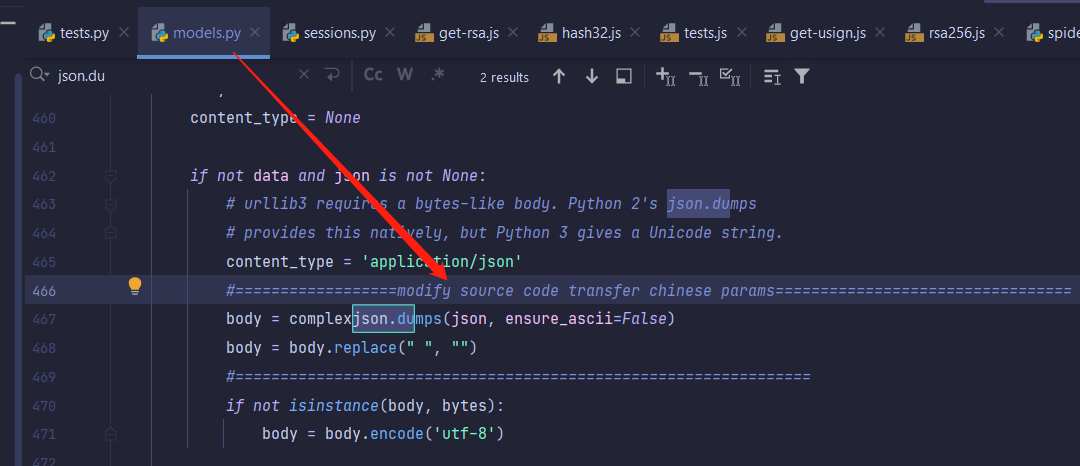
看到这个同学的截图,我大概知道他遇到了什么问题,以及为什么会误认为这是 Requests 的 bug。
要解释这个问题,我们需要首先明白一个问题,那就是 JSON 字符串的两种显示形式和json.dumps的ensure_ascii参数。
假设我们在 Python 里面有一个字典:
info = {'name': '青南', 'age': 20}
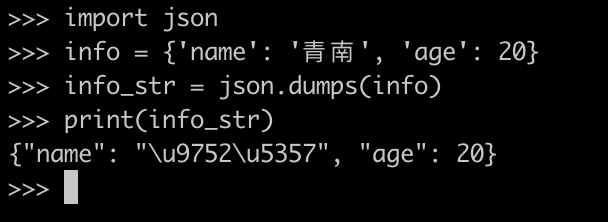
当我们想把它转成 JSON 字符串的时候,我们可能会这样写代码:
import json
info = {'name': '青南', 'age': 20}
info_str = json.dumps(info)
print(info_str)
运行效果如下图所示,中文变成了 Unicode 码:
我们也可以增加一个参数ensure_ascii=False,让中文正常显示出来:
info_str = json.dumps(info, ensure_ascii=False)
运行效果如下图所示:

这位同学认为,由于{"name": "\u9752\u5357", "age": 20}和{"name": "青南", "age": 20}从字符串角度看,显然不相等。而 Requests 在 POST 发送数据的时候,默认是没有这个参数,而对json.dumps来说,省略这个参数等价于ensure_ascii=True:
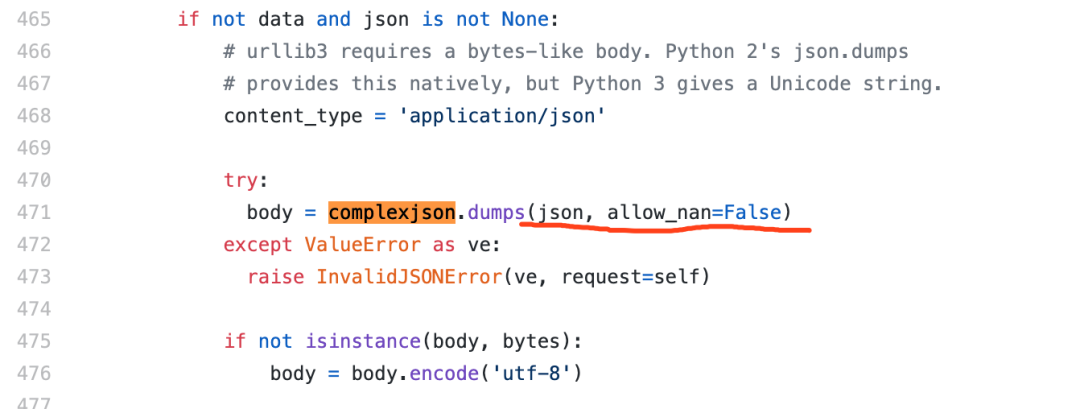
所以实际上Requests在 POST 含有中文的数据时,会把中文转成 Unicode 码发给服务器,于是服务器根本就拿不到原始的中文信息了。所以就会导致报错。
但实际上,并不是这样的。我常常跟群里的同学说,做爬虫的同学,应该要有一些基本的后端常识,才不至于被这种现象误导。为了说明为什么上面这个同学的理解是错误的,为什么这不是 Requests 的 bug,我们自己来写一个含有 POST 的服务,来看看我们POST 两种情况的数据有没有区别。为了证明这个特性与网络框架无关,我这里分别使用Flask、Fastapi 、Gin 来进行演示。
首先,我们来看看Requests 测试代码。这里用3种方式发送了 JSON 格式的数据:
import requests
import json
body = {
'name': '青南',
'age': 20
}
url = 'http://127.0.0.1:5000/test_json'
# 直接使用 json=的方式发送
resp = requests.post(url, json=body).json()
print(resp)
headers = {
'Content-Type': 'application/json'
}
# 提前把字典序列化成 JSON 字符串,中文转成 Unicode,跟第一种方式等价
resp = requests.post(url,
headers=headers,
data=json.dumps(body)).json()
print(resp)
# 提前把字典序列化成 JSON 字符串,中文保留
resp = requests.post(url,
headers=headers,
data=json.dumps(body, ensure_ascii=False).encode()).json()
print(resp)
这段测试代码使用3种方式发送 POST 请求,其中,第一种方法就是 Requests 自带的json=参数,参数值是一个字典。Requests 会自动把它转成 JSON 字符串。后两种方式,是我们手动提前把字典转成 JSON 字符串,然后使用data=参数发送给服务器。这两种方式需要在 Headers 里面指明'Content-Type': 'application/json',服务器才知道发上来的是 JSON 字符串。
我们再来看看 Flask 写的后端代码:
from flask import Flask, request
app = Flask(__name__)
@app.route('/')
def index():
return {'success': True}
@app.route('/test_json', methods=["POST"])
def test_json():
body = request.json
msg = f'收到 POST 数据,{body["name"]=}, {body["age"]=}'
print(msg)
return {'success': True, 'msg': msg}
运行效果如下图所示:
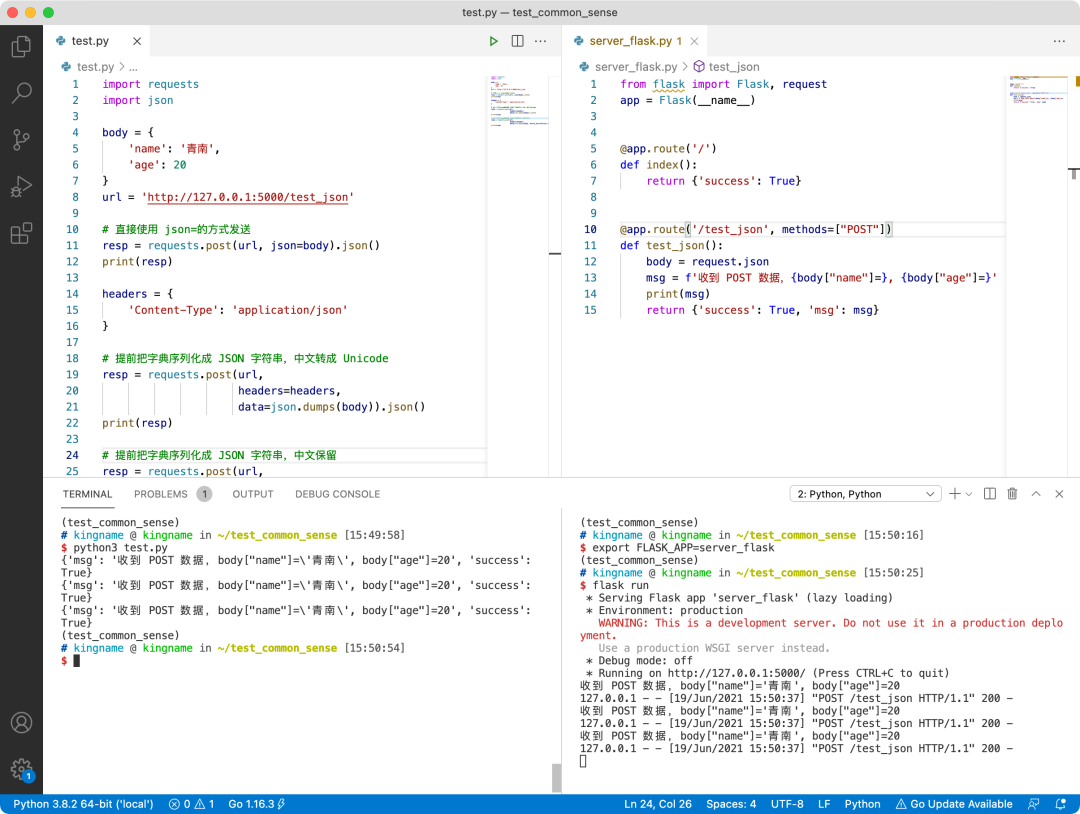
可以看到,无论使用哪种 POST 方式,后端都能接收到正确的信息。
我们再来看 Fastapi 版本:
from fastapi import FastAPI
from pydantic import BaseModel
class Body(BaseModel):
name: str
age: int
app = FastAPI()
@app.get('/')
def index():
return {'success': True}
@app.post('/test_json')
def test_json(body: Body):
msg = f'收到 POST 数据,{body.name=}, {body.age=}'
print(msg)
return {'success': True, 'msg': msg}
运行效果如下图所示,三种 POST 发送的数据,都能被后端正确识别:
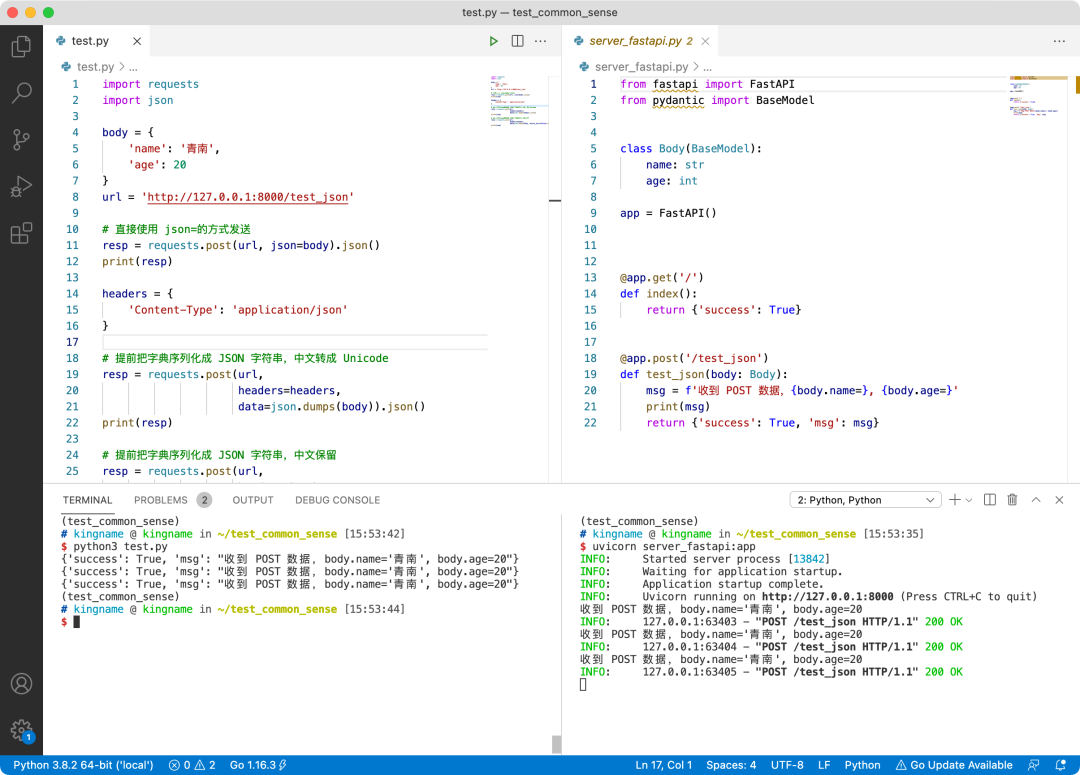
我们再来看看 Gin 版本的后端:
package main
import (
"fmt"
"net/http"
"github.com/gin-gonic/gin"
)
type Body struct {
Name string `json:"name"`
Age int16 `json:"age"`
}
func main() {
r := gin.Default()
r.GET("/", func(c *gin.Context) {
c.JSON(http.StatusOK, gin.H{
"message": "running",
})
})
r.POST("/test_json", func(c *gin.Context) {
json := Body{}
c.BindJSON(&json)
msg := fmt.Sprintf("收到 POST 数据,name=%s, age=%d", json.Name, json.Age)
fmt.Println(">>>", msg)
c.JSON(http.StatusOK, gin.H{
"msg": fmt.Sprintf("收到 POST 数据,name=%s, age=%d", json.Name, json.Age),
})
})
r.Run()
}
运行效果如下,三种请求方式的数据完全相同:
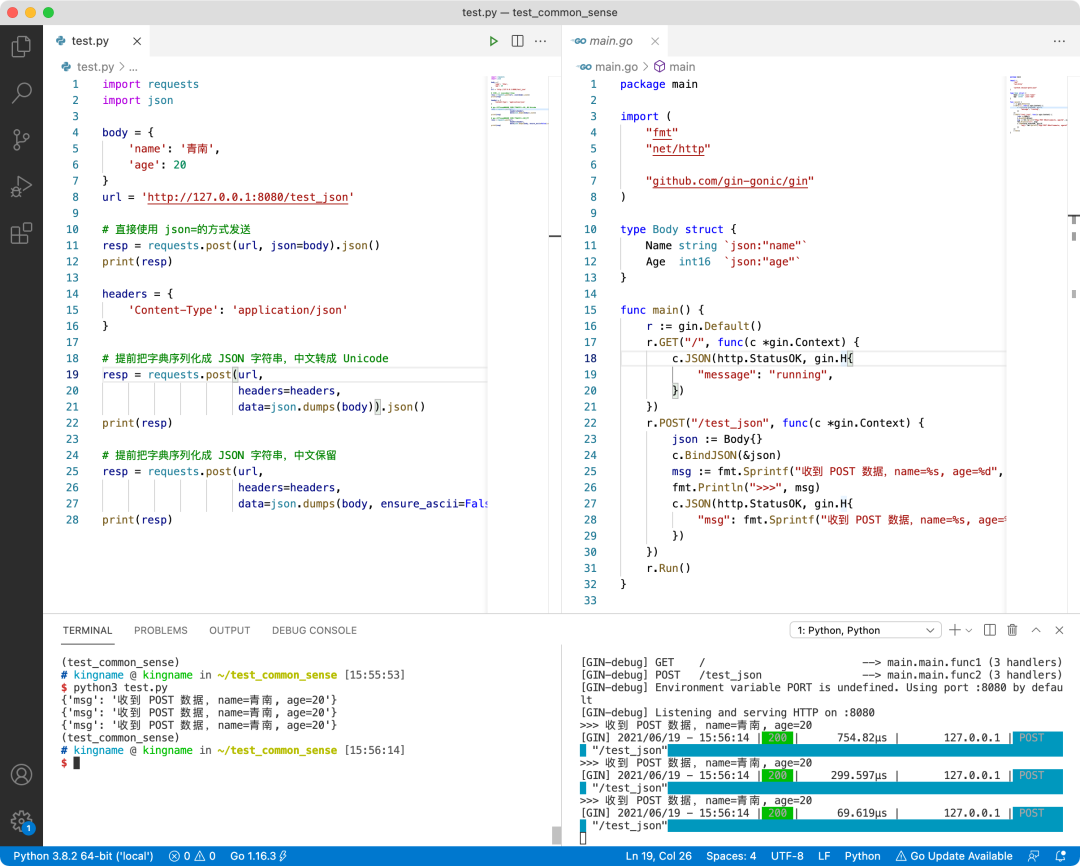
从这里可以知道,无论我们 POST 提交的 JSON 字符串中,中文是以 Unicode 码的形式存在还是直接以汉字的形式存在,后端服务都可以正确解析。
为什么我说中文在 JSON 字符串里面以哪种形式显示并不重要呢?这是因为,对 JSON 字符串来说,编程语言把它重新转换为对象的过程(叫做反序列化),本身就可以正确处理他们。我们来看下图:

ensure_ascii参数的作用,仅仅控制的是 JSON 的显示样式,当ensure_ascii为True的时候,确保 JSON 字符串里面只有 ASCII 字符,所以不在 ASCII 128个字符内的字符,都会被转换。而当ensure_ascii为False的时候,这些非 ASCII 字符依然以原样显示。这就像是一个人化妆和不化妆一样,本质并不会改变。现代化的编程语言在对他们进行反序列化的时候,两种形式都能正确识别。
所以,如果你是用现代化的 Web 框架来写后端,那么这两种 JSON 形式应该是没有任何区别的。Request 默认的json=参数,相当于ensure_ascii=True,任何现代化的 Web 框架都能正确识别 POST 提交上来的内容。
当然,如果你使用的是 C 语言、汇编或者其他语言来裸写后端接口,那确实可能有所差别。可智商正常的人,谁会这样做?
综上所述,这位同学遇到的问题,并不是 Requests 的 bug,而是他的后端接口本身有问题。可能那个后端使用了某种弱智 Web 框架,它接收到的被 POST 发上来的信息,没有经过反序列化,就是一段 JSON 字符串,而那个后端程序员使用正则表达式从 JSON 字符串里面提取数据,所以当发现 JSON 字符串里面没有中文的时候,就报错了。
除了这个 POST 发送 JSON 的问题,以前我有个下属,在使用 Scrapy 发送 POST 信息的时候,由于不会写POST 的代码,突发奇想,把 POST 发送的字段拼接到 URL 上,然后用 GET 方式请求,发现也能获取数据,类似于:
body = {'name': '青南', 'age': 20}
url = 'http://www.xxx.com/api/yyy'
requests.post(url, json=body).text
requests.get('http://www.xxx.com/api/yyy?name=青南&age=20').text
于是,这个同学得出一个结论,他认为这是一个普遍的规律,所有 POST 的请求都可以这样转到 GET 请求。
但显然,这个结论也是不正确的。这只能说明,这个网站的后端程序员,让这个接口能同时兼容两种提交数据的方式,这是需要后端程序员额外写代码来实现的。在默认情况下,GET 和 POST 是两种完全不同的请求方式,也不能这样转换。
如果这位同学会一些简单的后端,那么他立刻就可以写一个后端程序来验证自己的猜想。
再来一个例子,有一些网站,他们在 URL 中可能会包含另外一个 URL,例如:
https://kingname.info/get_info?url=https://abc.com/def/xyz?id=123&db=admin
如果你没有基本的后端知识,那么你可能看不出上面的网址有什么问题。但是如果你有一些基本的后端常识,那么你可能会问一个问题:网址中的&db=admin,是属于https://kingname.info/get_info的一个参数,跟url=平级;还是属于https://abc.com/def/xyz?id=123&db=admin的参数?你会疑惑,后端也会疑惑,所以这就是为什么我们这个时候需要 urlencode 的原因,毕竟下面两种写法,是完全不一样的:
https://kingname.info/get_info?url=https%3A%2F%2Fabc.com%2Fdef%2Fxyz%3Fid%3D123%26db%3Dadmin
https://kingname.info/get_info?url=https%3A%2F%2Fabc.com%2Fdef%2Fxyz%3Fid%3D123&db=admin
最后,以我的爬虫书序言中的一句话来作为总结:
爬虫是一门杂学,如果你只会爬虫,那么你是学不好爬虫的。

快进来看王冰冰!Python+Flask写了一个学习提醒系统

使用FastAPI重写Django官网Polls教程